Used: Eureka Server, Config Server, Config Client, Zuul Api Gateway, Feign Client, RestTemplate, WebClient, Hystrix, Ribbon, Security (JWT), Spring WebFlux + MongoDB + Docker
Мое знакомство со стеком началось больше полугода назад, и я нашел в нем определенные классные фичи, которые работают из коробки и которые, как мне кажется, достаточно интересные. Я начал писать статьи в блоге и частично переводить документацию на русский язык, т.к. на русском довольно простой и понятной документации я не нашел, когда изучал данный материал.
В ходу статьи буду стараться давать ссылки на свои статьи. Надеюсь кто-то найдет из этого что-нибудь полезное.
В этом небольшом примере рассмотрим все из вышеуказанных топиков. В этом примере я намешал всего и постарался показать все фишки вместе. Не пугайтесь :)
Я понимаю, что далеко до совершенства, но цель данного примера показать стандартные возможности Spring Cloud (Netflix OSS).
Если вы нашли какие-либо неточности или видите, что можно что-то улучшить, предложите свои изменения и я с радостью добавлю их. Давайте сделаем это вместе :)
Облачные вычисления — это предоставление вычислительных служб (серверов, хранилища, баз данных, сетей, программного обеспечения, аналитики и т.д.) посредством интернета. Такие службы ускоряют внедрение каких-либо инноваций, повышают гибкость ресурсов и обеспечивают экономию благодаря высокой масштабируемости. Пользователь обычно платит только за облачные службы, которые он использет.
Какие проблемы это решает ?
- Затраты
Облачные вычисления позволяют избежать капитальных затрат на приобретение оборудования и программного обеспечения, настройку и эксплуатацию.
- Скорость
Большинство облачных вычислительных служб предоставляются в режиме самообслуживания и по запросу.
- Глобальный масштаб
Преимущества служб облачных вычислений включают возможность эластичного масштабирования.
- Производительность
Для локальных центров обработки данных обычно требуются много стоек и серверов, а также настройка оборудования. Облачные вычисления позволяют избежать многих из этих задач. Самые большие облачные вычислительные службы работают в мировой сети безопасных центров обработки данных, которые регулярно обновляются до самого последнего поколения быстрого и эффективного вычислительного оборудования.
- Надежность
Облачные вычисления делают резервное копирование данных, аварийное восстановление и непрерывность бизнес-процессов
- Безопасность
Многие поставщики облачных служб предлагают широкий набор политик, технологий и средств контроля, которые в целом повышают уровень безопасности, помогая защитить данные, приложения и инфраструктуру от потенциальных угроз.
Если вам нужны некоторые из ваших микросервисов на другом языке, то Kubernetes может это сделать, если не бояться потратить деньги на инвестиции в ваш технический стек, чтобы иметь более широкую и менее зависимую систему.
Если вам нужна быстрая разработка, хорошо интегрированная со стеком Spring без большого участия DevOps - то здесь не обойтись без Spring Cloud.
Spring Cloud имеет богатый набор хорошо интегрированных библиотек Java для решения всех проблем во время выполнений.
В результате у самих микросервисов есть библиотеки для различных задач:
- для обнаружения клиентов
- для балансировки нагрузки
- для обновления конфигурации
- для отслеживания показателей и т.д.
Kubernetes предназначен не только для платформы Java, и решает проблемы распределенных вычислений в общем для всех языков.
Он предоставляет услуги по управлению конфигурацией, обнаружению сервисов, балансировке нагрузки, трассировке, метрикам, запланированным заданиям и т.д.
Некоторые библиотеки, такие как Hystrix, Spring Boot, одинаково полезны для обеих сред. Есть области, где обе платформы являются взаимодополняющими и могут быть объединены вместе для создания более мощного решения (такие примеры - KubeFlix и Spring Cloud Kubernetes например).
https://github.com/spring-cloud/spring-cloud-kubernetes
http://www.ofbizian.com/2016/12/spring-cloud-compared-kubernetes.html
Он нужен чтобы облегчить интеграцию приложений Spring Cloud и Spring Boot, работающих в Kubernetes.
Kubernetes integration with Netflix
https://blog.fabric8.io/kubeflix-kubernetes-integration-with-netflix-69f76d27ef91
Немного биографии.
Netflix - это американская развлекательная компания, предоставляющая услуги видео онлайн (online Video streaming) и видео по запросу (Video on demand), основана в 1997 году, штаб-квартира находится в Лос Гатос, Калифорния. Изначально она являлась компанией по дистрибуции DVD, модель продажи былла отправка DVD по почте покупателям (DVD Emailing).
В 2006 году Amazon объявила о своем большом проекте и совсем не связано с индустрией их бизнеса, это "облачные вычисления" (Cloud computing).
Сервис, который позже был назван как Amazon S3 (Amazon Simple Storage Service) позволяет пользователям сохранять свои данные в облачных серверах и иметь доступ всегда и везде.
Netflix понял что Amazon является нужным для них партнером. Вместо того, чтобы инвестировать много денег в сервера, можно использовать инфраструктуру у Amazon. Так и началось их сотрудничество.
На данный момент Netflix является самой большоей компанией в мире предоставляющей сервис онлайн фильмов и видео по запросу (video on demand).
Почти все ресурсы Netflix развернуты на Amazon Web Service (AWS).
Ниже приведено изображение архитектуры их системы в качестве примера:
Есть множество моментов, когда Docker, микросервисы и реактивщина просто не нужны.
На эту тему есть отличная статья:
https://dataart.ua/news/vsegda-li-nuzhny-docker-mikroservisy-i-reaktivnoe-programmirovanie/
Eureka Server — это приложение, которое содержит информацию обо всех клиентских сервисных приложениях.
Каждый микросервис регистрируется на сервере Eureka, и Eureka знает все клиентские приложения, работающие на каждом порту и IP-адресе.
Eureka Server также известен как Discovery Server.
Его аналоги:
- Consul
- Zookeeper
- Cloud Foundry
Если простыми словами, то — это сервер имен или реестр сервисов. Обязанность — давать имена каждому микросервису. Регистрирует микросервисы и отдает их ip другим микросервисам.
Таким образом, каждый сервис регистрируется в Eureka и отправляет эхо-запрос серверу Eureka, чтобы сообщить, что он активен.
Для этого сервис должен быть помечен как @EnableEurekaClient, а сервер @EnableEurekaServer.
При указании аннотаций @EnableDiscoveryClient тоже отработает, т.к. Eureka является Discovery сервисом, но вот в случае если использовать наоборот - юбой другой Dicovery сервис и использовать аннотацию @EnableEurekaClient, так уже не получится.
Eureka Client сбрасывает все HTTP-соединения, которые простаивали более 30 секунд, которые он создал для связи с сервером.
Клиент взаимодействует с сервером следующим образом:
-
Eureka Client регистрирует информацию о запущенном экземпляре на сервере Eureka.
-
Каждые 30 секунд Eureka Client отсылает запрос на сервер и информирует сервер о том, что он (экземпляр) еще жив. Если сервер не видел обновления в течение 90 секунд, он удаляет экземпляр из своего реестра.
-
Eureka Client получает информацию реестра от сервера и кэширует ее у себя локально. Эта информация обновляется периодически (каждые 30 секунд), получая обновления между последним апдейтом и текущим. Клиент автоматически обрабатывает дублирующую информацию.
-
Получив обновления, клиент сверяет информацию с сервером, сравнивая количество экземпляров, возвращаемых сервером, и если информация по какой-либо причине не совпадает, вся информация реестра извлекается снова. Клиент получает информацию в сжатом формате JSON, используя клиент jersey apache.
-
При завершении работы клиент отправляет запрос отмены на сервер. Таким образом экземпляр удаляется из реестра экземпляров сервера. Eureka использует протокол, который требует, чтобы клиенты выполняли явное действие отмены регистрации.
Клиенты, которые использовали 3 неудачные попытки синхронизации с сервером с интервалом в 30 секунд будут удалены автоматически.
Серверы Eureka взаимодействуют друг с другом, используя тот же механизм, который используется между клиентом и сервером.
Когда сервер запускается, он пытается получить всю информацию реестра экземпляра от соседнего узла.
Если при получении информации от узла возникает проблема, сервер проверяет все равноправные узлы.
В случае проблем сервер пытается защитить уже имеющуюся у него информацию.
Более подробную информацию про Eureka вы можете прочитать в моей статье. Надеюсь она будет полезна.
https://medium.com/@kirill.sereda/spring-cloud-netflix-eureka-%D0%BF%D0%BE-%D1%80%D1%83%D1%81%D1%81%D0%BA%D0%B8-5b7829481717
Подсказки для настроек в файлах application.property, application.yml:
https://cloud.spring.io/spring-cloud-static/Dalston.SR5/multi/multi__appendix_compendium_of_configuration_properties.html
Минимальные настройки eureka server - это порт и имя, а также @EnableEurekaServer над основным классом. Этого будет достаточно.
В нашем примере мы указали следующие настройки в файле application.yml
spring:
application:
name: eureka-server
server:
port: ${PORT:8761}
eureka:
client:
register-with-eureka: false
fetch-registry: false
instance-info-replication-interval-seconds: 10
server:
eviction-interval-timer-in-ms: 50000
wait-time-in-ms-when-sync-empty: 5
Наш сервер работает на порту 8761 с именем eureka-server.
Более детальное описание других настроек можно увидеть в коде на github.
Ссылка на Eureka Server:
https://github.com/ksereda/Gallery-Service/tree/master/eureka-server
Некоторые настройки в application.yml закомментированы. Не обращайте на них внимание, к ним вернемся чуть позже.
Основной класс:
@SpringBootApplication
@EnableEurekaServer
public class EurekaServerApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaServerApplication.class, args);
}
}
Запустите приложение и перейдите в браузере
http://localhost:8761
Вы увидите дашборд для управления.
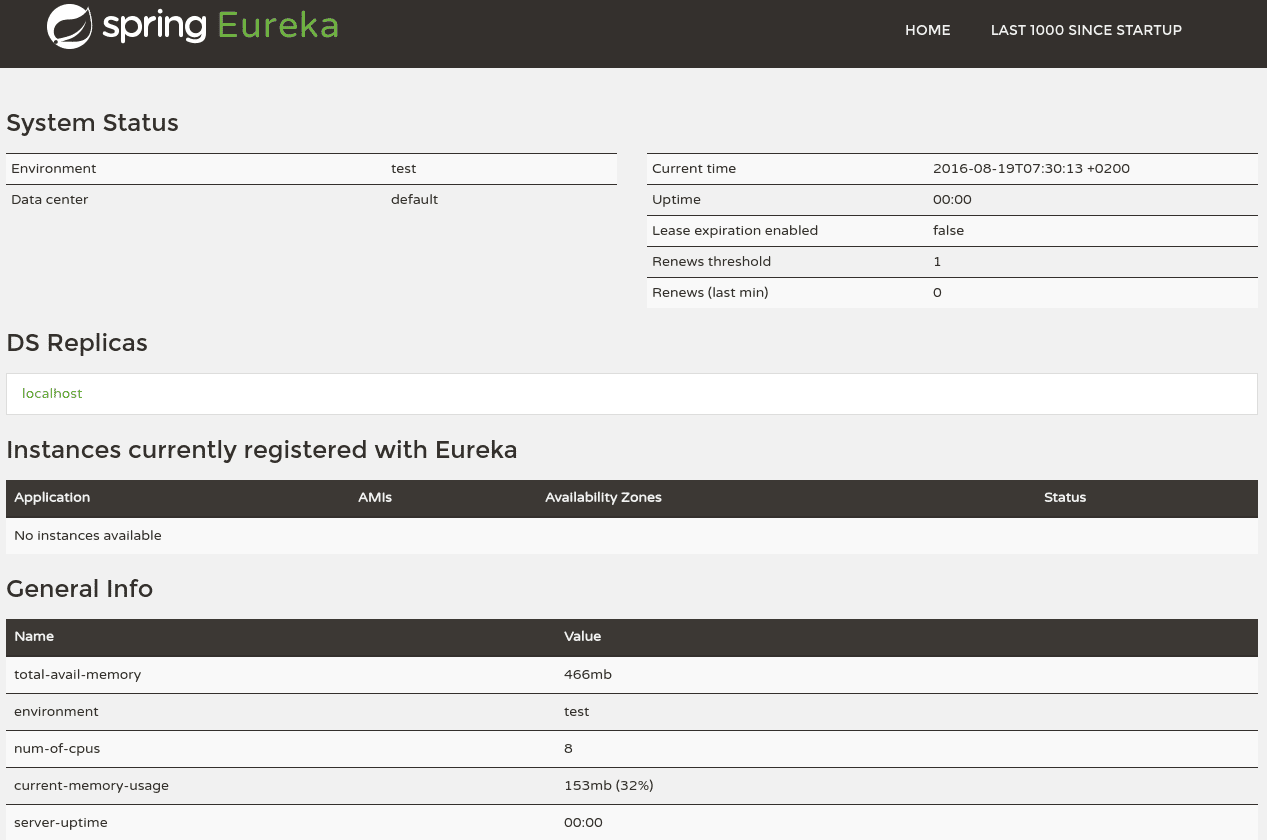
Для того, чтобы сервис стал клиентом Eureka, ему необходимо над основным классом указать @EnableEurekaClient
@SpringBootApplication
@EnableEurekaClient
public class GalleryServiceApplication {
public static void main(String[] args) {
SpringApplication.run(GalleryServiceApplication.class, args);
}
}
В нашем примере все остальные сервисы будут по совместительству клиентами Eureka, не важно, каку функцию они выполняют.
Рассмотрим gallery-service.
Он представляет обычный CRUD.
Мы будем использовать базу MongoDB, Spring WebFlux для реактивности и Lombok.
У нас есть Bucket модель с темами для изучения
@Data
@Builder
@AllArgsConstructor
@Document(collection = "buckets")
public class Bucket {
@Id
private String id;
@NotBlank
@Size(max = 10)
private String title;
private String description;
private int personalNumber;
private String imageLink;
}
У нас есть контроллер BucketController , который обрабатывает запросы через реактивный репозиторий
@Repository
public interface BucketRepository extends ReactiveMongoRepository<Bucket, String> {
}
Все достаточно просто.
Файл настроек также прост
spring:
application:
name: gallery-service
data:
mongodb:
uri: mongodb://localhost:27017/gallerydb
server:
port: 8081
eureka:
client:
serviceUrl:
defaultZone: ${EUREKA_URI:http://localhost:8761/eureka}
instance:
preferIpAddress: true
Используем MongoDB в докере на порту 27017 с именем базы gallerydb
Запустите Eureka Server вначале, а затем запустите наш сервис и перейдите на
http://localhost:8081/
чтобы получить информацию что наш сервис работает.
Если вы перейдете в Eureka
http://localhost:8761
Вы увидите что Eureka увидела наш сервис (имя и на каком порту он работает). Сервер и клиент обменялись эхо запросами и поддерживают связь.
Также при старте gallery-service в консоли вы можете увидеть строки
2019-08-29 15:53:41.923 INFO [gallery-service,,,] 1333 --- [ restartedMain] com.netflix.discovery.DiscoveryClient : Getting all instance registry info from the eureka server
2019-08-29 15:53:42.389 INFO [gallery-service,,,] 1333 --- [ restartedMain] com.netflix.discovery.DiscoveryClient : The response status is 200
2019-08-29 15:53:42.410 INFO [gallery-service,,,] 1333 --- [ restartedMain] o.s.c.n.e.s.EurekaServiceRegistry : Registering application gallery-service with eureka with status UP
что означает, что сервис зарегистрировался в Eureka и получил подтверждение.
Непосредственно в консоли самой Eureka можно увидеть следующее
2019-08-29 15:53:42.484 INFO 1053 --- [nio-8761-exec-1] c.n.e.registry.AbstractInstanceRegistry : Registered instance GALLERY-SERVICE/192.168.97.121:gallery-service:8081 with status UP (replication=false)
2019-08-29 15:53:43.056 INFO 1053 --- [nio-8761-exec-3] c.n.e.registry.AbstractInstanceRegistry : Registered instance GALLERY-SERVICE/192.168.97.121:gallery-service:8081 with status UP (replication=true)
Eureka успешно зарегистрировала gallery-service.
Вы также можете запустить gallery-service не запуская перед ним Eureka, тогда вы увидите что сервис поднялся, но не смог зарегистрироваться в Eureka и получите сообщение об ошибке
2019-08-29 15:58:42.529 WARN [gallery-service,,,] 1333 --- [freshExecutor-0] c.n.d.s.t.d.RetryableEurekaHttpClient : Request execution failed with message: java.net.ConnectException: В соединении отказано (Connection refused)
2019-08-29 15:58:42.529 ERROR [gallery-service,,,] 1333 --- [freshExecutor-0] com.netflix.discovery.DiscoveryClient : DiscoveryClient_GALLERY-SERVICE/192.168.97.121:gallery-service:8081 - was unable to refresh its cache! status = Cannot execute request on any known server
com.netflix.discovery.shared.transport.TransportException: Cannot execute request on any known server
Но вы сможете работать с ним.
Каждые 30 секунд сервис будет слать эхо запрос на Eureka и ждать что она ответит ему взаимностью.
Ссылка на gallery-service
https://github.com/ksereda/Gallery-Service/tree/master/gallery-service
Некоторые настройки в application.yml закомментированы. Не обращайте на них внимание, к ним вернемся чуть позже.
В основном классе я указал
@Bean
CommandLineRunner run(BucketRepository bucketRepository) {
return args -> {
bucketRepository.deleteAll()
.thenMany(Flux.just(
new Bucket("1", "Java", "OOP", 280, "http://infopulse-univer.com.ua/images/trenings/java.png"),
new Bucket("2", "Java", "Steram API", 437, "https://www.hdwallpaperslife.com/wp-content/uploads/2018/09/JAVA14-480x270.png"),
new Bucket("3", "Java", "Collections", 14, "https://i.ytimg.com/vi/oOOESCvGGcI/hqdefault.jpg"),
new Bucket("4", ".NET", "Basic", 1213, "https://upload.wikimedia.org/wikipedia/commons/0/0e/Microsoft_.NET_logo.png"),
new Bucket("5", "C++", "Basic", 870, "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSmgIz9Ug-MVzBQJMcgXedOXTqHWGmbSu5pPDivz8hrfo_GE0HZEA"),
new Bucket("6", "JavaScript", "Angular 8", 155, "https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTg41zepuyHbew8bIsTYeKWJ9RYOnnV922lNa85-fQTVrKDG19K2w")
)
.flatMap(bucketRepository::save))
.thenMany(bucketRepository.findAll())
.subscribe(System.out::println);
};
}
чтобы при старте приложения атвоматически создались данные, которые отобразятся в нашей MongoDB (чтобы не создавать вручную).
Как настроить MongoDB я опишу ниже.
Перейдите в браузере на
http://localhost:8081/getAll
чтобы получить все данные из базы.
Аналогично /create, /update, /delete
-
если вы перейдете на
вы получите все данне из базы стримом.
Здесь во всю используется прелесть реактивной системы с
MediaType.TEXT_EVENT_STREAM_VALUE
-
перейдите на
И будете получать каждую секунду новое деволтное значение
-
перейдите на
При помощи Flux мы можем получить все обьекты из базы с интервалом в 2 секунды каждый. Здесь мы сэмулировали ситуацию, которая позволяет получить данные по мере их поступления. Это одна из основных идей реактивного программирования.
Мы подписываемся на поток и ждем данные. Spring сам уведомит нас о поступлении данных.
Основная концепция реактивного программирования базируется на неблокирующем вводе/выводе.
Напрмиер при старте приложения в нашей базе находится 4 записи а не 6. без использовании реактивности мы бы получили 4 записи. Потом кто-либо в этот промежуток времени добавил еще 2 записи и когда мы сделали второй запрос, мы бы получили 6 записей.
С использованием потоков Mono/Flux мы сэмулировали такую ситуацию и за один запрос сможем получить все данные с небольшим интервалом.
Реактивные типы не предназначены для того, чтобы вы могли обрабатывать ваши запросы или данные быстрее, на самом деле они привносят небольшие накладные расходы по сравнению с обычной блокировкой.
Их сила заключается в их способности одновременно обслуживать больше запросов и более эффективно обрабатывать операции с задержкой, такие как запрос данных с удаленного сервера.
Они позволяют вам обеспечить лучшее качество обслуживания и предсказуемое планирование пропускной способности, изначально имея дело со временем и задержкой, не затрачивая больше ресурсов.
В отличие от традиционной обработки, которая блокирует текущий поток во время ожидания результата, Reactive API, который ожидает, ничего не стоит, запрашивает только тот объем данных, который он способен обработать, и предоставляет новые возможности, поскольку он имеет дело с потоком данных, а не только с отдельными элементами.
Следуя документации Spring WebFlux, Spring Framework использует Reactor для своей собственной реактивной поддержки.
Reactor - это реализация Reactive Streams, которая еще больше расширяет базовый Publisher контракт Reactive Streams с типами Flux и Mono, чтобы обеспечить декларативные операции над последовательностями данных.
На стороне сервера Spring поддерживает аннотации и функциональные модели программирования. Использование модели аннотаций @Controller и других аннотаций также поддерживается Spring MVC.
Реактивный контроллер будет очень похож на стандартный REST-контроллер для синхронных служб.
Обратите внимание, что вам нужна Spring Boot версии 2.xx для использования модуля Spring WebFlux.
Для поддержки реактивного программирования и создания реактивных систем команда Spring Boot создала совершенно новый веб-стек под названием Spring WebFlux.
Этот новый веб-стек поддерживает аннотированные контроллеры, функциональные конечные точки, WebClient (аналог RestTemplate в Spring Web MVC), WebSockets и многое другое.
WebFlux по умолчанию использует Netty.
Tomcat не поддерживает реактивщину.
Если можно сказать прсотыми словами, то
Реактивное программирование — это программирование с асинхронными потоками(streams) данных.
Т.е. можно слушать поток и реагировать на события в нем. Можем фильтровать поток как нам вздумается, объединять потоки, кроме того потоки могут быть входными параметрами других потоков.
Поток - это некая последовательность чего-либо, остортированных по времени.
Нам лишь надо подписаться на поток.
Наблюдатель (observers) подписывается на поток.
Неблокирующий ввод/вывод.
Есть два варианта получить данные:
- Pull
Это когда мы сами делаем запрос на получение и нам приходит ответ.
- Push
Когда данные сами нас уведомляют об изменениях и выталкивают данные нам.
Реактивное приложение, это когда приложение само извещает нас об изменении своего состояния. Не мы делаем запрос и проверяем, а не изменилось ли там что-то, а приложение само нам сигнализирует. Ну и конечно эти события, эти сигналы мы соответственно можем обрабатывать.
Для начала надо понять, что же такое Push и Pull коллекции, т.к. эти понятия тесно связаны друг с другом.
-
Pull - коллекция (аналог - массив): в ней есть данные, которые мы можем получить по запросу, предварительно обработав их как нам хочется.
-
Push - полная противоположность: изначально в ней нет данных, но как только они появятся, она нам сообщит об этом. Во время этого мы также можем делать с ней что хотим и как только в коллекции появятся значения, она выполнит все наши фильтры (которые мы на нее навесили) и выдаст нам результат.
Push коллекция как-бы "состоит" из новой сущности Observable.
Это и есть коллекция, которая будет рассылать уведомления об изменении своего состояния.
Существует еще одно понятие - Observer.
Он может подписаться на событие объекта и выполнять какие либо действия с полученным результатом.
У одного Subject может быть много подписчиков.
Во всех реактивных библиотеках есть встроенные инструменты для превращения стандартных ивентов в Observables (для преобразования событий в реактивные потоки).
Спецификация для реактивного подхода Spring WebFlux:
https://github.com/reactive-streams/reactive-streams-jvm/blob/v1.0.1/README.md#specification
В новом подходе у нас есть два основных класса для работы в реактивном режиме:
- Mono
Класс Mono нужен для работы с единственным объектом.
- Flux
Данный класс схож с Mono, но предоставляет возможность асинхронной работы со множеством объектов:
Flux и Mono реализуют Publisher интерфейс из спецификации Reactive Streams.
Также можно унаследовать MongoReactRepository.
Если заглянуть в интерфейс ReactiveMongoRepository, то можно увидеть, что нам возвращаются объекты, обернутые в классы Mono и Flux.
Это значит, что при каком-либо обращении в БД, мы не получаем сразу же результат. Вместо этого мы получаем поток данных Publisher, из которого можно получить данные по мере готовности, а точнее он сам нам их отдаст по мере готовности.
Новый поток не нужен, так как текущий поток не блокируется!
-
Реактивность дает слабую связанность.
-
В некоторых случаях это дает возможность писать более простой и понятный код.
Например мы можем взять обычную коллекцию, преобразовать ее к реактивной коллекции и тогда мы будем иметь коллекцию событий об изменении данных в ней. Мы очень просто получаем только те данные, которые изменились. По этой коллекции мы можем делать выборку, фильтровать и т.д.
Если бы мы это делали традиционным способом, то нам нужно было бы закэшировать текущие данные, потом делать запрос на получение новых данных и сравнить их с текущим значением. Не удобно.
Чтобы получить данные, мы обращаемся к базе данных, получаем данные и отдаем пользователю. Если у вас в этот момент времени на секунду пропадет интернет то вы получите ошибку. Беда.
Реактивщина нам поможет в данном случае.
Аналог для примера: Gmail, Facebook, Instagram, Twitter. Когда у вас плохой интернет, вы не получаете ошибку, а просто ждете результат больше обычного.
-
Приложение должно отдавать пользователю результат за полсекунды
-
Обеспечить отзывчивость под нагрузкой
-
Система остается в рабочем состоянии даже, если один из компонентов отказал.
-
Elastic: Данный принцип говорит о том, что система должна занимать оптимальное количество ресурсов в каждый промежуток времени.
-
Общение между сервисами должно происходить через асинхронные сообщения. Это значит, что каждый элемент системы запрашивает информацию из другого элемента, но не ожидает получение результата сразу же. Вместо этого он продолжает выполняеть свои задачи.
Реативщину стоит использовать, когда есть поток событий, растянутый во времени (например, пользовательский ввод).
Функционал, написанный при помощи реактивных потоков, может быть легко дополнен и расширен.
Что касается меня, я сильно запарился по этой теме :) Но это вовсе не значит что надо использовать реактивщину везде.
Я запускаю MongoDB в докере.
При условии что у вас установлен docker, приступим.
docker pull mongo
Docker сольет с docker-hub актуальную версию
Проверить можем так
docker images
В результате увидим все текущие образы, которые у вас скачаны (на данный момент у вас должен быть он всего один, при условии что вы раньше не пользовались docker)
По умолчанию используется порт 27017, поэтому можем не указывать его
docker run mongo
или можете явно указать порт
docker run mongo --port 27017
Открываем новую консоль, пишем
mongo
Вы попали в оболочку Mongo.
При условии что вы запустили Eureka Server и gallery-service (он настроен с MongoDB на порту 27017) вы можете в оболочке Mongo написать
use gallerydb
где gallerydb - Это имя базы (см файл application.yml)
Затем выполнить в ней
show collections
и вы увидите объект buckets (см Bucket класс)
Затем выполнить
db.buckets.find()
И вы получите все данные (6 объектов), которые создались по умолчанию при старте приложения.
Если хотите запустить вторую Mongo на другом порту
docker run mongo --port 27018
Открываем новую консоль, пишем
mongo
Я также написал статью для более подробной информации:
https://medium.com/@kirill.sereda/%D0%B7%D0%B0%D0%BF%D1%83%D1%81%D0%BA-%D0%BD%D0%B5%D1%81%D0%BA%D0%BE%D0%BB%D1%8C%D0%BA%D0%BE-mongodb-%D0%B2-docker-7667c04d8e7d
В нашем примере также есть user-service.
Он будет общаться с gallery-service и будет получать данные из базы данных непосредственно через gallery-service.
Сам он с БД не связан.
Есть несколько вариантов использования данной коммуникации:
-
RestTemplate
-
Feign Client
-
WebClient (поскольку у нас реактивная система). Т.к.
Feign Clientне дружит с реактивщиной (хотя недавно вышел патч для использования Feign в реактивной системе - Reactive Feign Client, или можно использовать OpenFeign - реализация от Netflix, либо же использовать спецаильный для этого WebClient)
В данном примере мы рассморим все 3 варианта.
В кратце:
Наш user-service будет получать данные из базы данных через gallery-service.
В случае выхода из строя БД или gallery-service мы будем использовать библиотеку Hystrix, которая вместо ошибки будет возвращать нам дефолтное значение либо вы можете настроить реплику сервиса gallery-service, и в случае выхода из строя самого сервиса, вы будете обращаться к его реплике.
Пользователь ничего не заметит.
Очень удобно.
Также наш user-service будет использовать Ribbon - балансировщик нагрузки между репликами другим сервисов.
У нас будет Movie-service с запасной репликой, и мы натсроим Load Balancer.
Также к user-service я прикрутил ELK (Elastic Search Kibana) для просмотра логов.
Также ы прикрутим сюда JWT Security и только admin сможет создавать новые Bucket в базе данных.
Сам user-service находится по ссылке:
https://github.com/ksereda/Gallery-Service/tree/master/user-service
Настройки в файле application.yml аналогичные gallery-service.
Те настройки, которые закоментированы, мы рассмотрим чуть позже, когда дойдем до Config Server и Config Client.
У нас есть UserController, в котором мы будем общаться с gallery-service через RestTemplate, FeignClient и WebClient.
Также у нас есть LogInterceptor, который будет выводить в консоль время выолнения нашего каждого запроса на нашем сервисе.
Также у нас есть точно такой же класс Bucket (как и в gallery-service) - это обязательное условие для общения через FeignClient и WebClient. Но здесь Lombok мы не сможем применить, т.к. WebClient с ним не особо дружит.
В этом примере я намешал всего и постарался показать все фишки вместе. Не пугайтесь :)
Это простой и гибкий http-клиент, который нативно интегрирован с Ribbon.
Feign использует интерфейсы аннотированные @FeignClient чтобы генерировать API запросы и мапить ответ на Java классы.
Он шлет http запросы другим сервисам.
Его особенность в том, что нам не нужно знать где и на каком порту находится какой-то сервис.
Мы просто говорим Feign клиенту, иди к “Васе” и получи у него всех пользователей. Далее Feign обращается к Eureka Server и спрашивает где находится “Вася”.
Если “Вася” регистрировался в Eureka Server, то Eureka будет всё знать о “Васе” (где он находится, на каком порту, его URL и т.д.).
Вам нужно только описать, как получить доступ к удаленной службе API, указав такие детали, как URL, тело запроса и ответа, принятые заголовки и т. д. Клиент Feign позаботится о деталях реализации.
Netflix предоставляет Feign в качестве абстракции для вызовов на основе REST, благодаря которым микросервисы могут связываться друг с другом, но разработчикам не нужно беспокоиться о внутренних деталях REST.
Нужно указать аннотацию @EnableFeignClients над основным классом.
Теперь у нашего user-service будут уже 3 аннотации
@SpringBootApplication
@EnableEurekaClient
@EnableFeignClients
На интерфейс ставим аннотацию @FeignClient(name = “Вася”) и указываем имя того сервиса, который нам нужен (в пояснении я описывал сервис под названием “Вася”).
В том сервисе будет выполняться некая логика по работе с базой и настройки коннекта к базе, или получение всех пользователей и т.д.
Более детально про замечательный Feign Client я написал в статье:
https://medium.com/@kirill.sereda/spring-cloud-netflix-feign-%D0%BF%D0%BE-%D1%80%D1%83%D1%81%D1%81%D0%BA%D0%B8-7b8272e8e110
В нашем примере в UserController мы указали путь
@RequestMapping(path = "/getAllDataFromGalleryService")
public List<Bucket> getDataByFeignClient(Model model) {
List<Bucket> list = ServiceFeignClient.FeignHolder.create().getAllEmployeesList();
return list;
}
Теперь нам необходимо сделать сервис с бизнес логикой.
Делаем интерфейс ServiceFeignClient
@FeignClient(name = "gallery-service", url = "http://localhost:8081/", fallback = Fallback.class)
public interface ServiceFeignClient {
class FeignHolder {
public static ServiceFeignClient create() {
return HystrixFeign.builder().encoder(new GsonEncoder()).decoder(new GsonDecoder()).target(ServiceFeignClient.class, "http://localhost:8081/", new FallbackFactory<ServiceFeignClient>() {
@Override
public ServiceFeignClient create(Throwable throwable) {
return new ServiceFeignClient() {
@Override
public List<Bucket> getAllEmployeesList() {
System.out.println(throwable.getMessage());
return null;
}
};
}
});
}
}
@RequestLine("GET /show")
List<Bucket> getAllEmployeesList();
}
Смотрите, здесь мы указываем имя сервиса, к которому хотим обратиться (в аннотации), затем указываем, что в случае ошибки (недоступнсоти сервиса gallery-service или базы данных) у нас отработает наш кастомный Fallback класс с какой-то нашей кастомной логикой.
Feign Client нативно интегрирован с Hystrix, поэтому нам явно не надо указывать реализацию. Но позже мы разберем ее отдельно, для понимания.
В самой реализации Feign мы должны использовать GsonEncoder и GsonDecoder - для этого добавить зависимости в pom.
Во всей этой неразберихе у нас вызывается в итоге метод getAllEmployeesList
@RequestLine("GET /show")
List<Bucket> getAllEmployeesList();
Внимание!
Метод должен иметь возвращаемое значение и по сигнатуре быть точно таким же как и метод на gallery-service, который мы вызываем, а именно метод по пути
/show
Сам путь также должен быть идентичным.
Идем в наш gallery-service и видим вызываемый нами метод на получение всех данных
@GetMapping(path = "/show")
public Flux<Bucket> getAllEmployeesList() {
return bucketRepository.findAll();
}
Теперь когда мы будем вызывать URL
http://localhost:8082/getAllDataFromGalleryService
на нашем user-service, он посмотрит на аннотацию @FeignClient(name = “gallery-service”) и увидит, что там указан сервис gallery-service, он пойдет в Eureka Server, спросит про gallery-service, Eureka Server скажет ему где он находится и Feign Client по этому же URL в BucketController вызовет метод
@GetMapping(path = "/show")
public Flux<Bucket> getAllEmployeesList() {
return bucketRepository.findAll();
}
Все очень просто.
Для коммуникации червисов через RestTemplate используется метод
@GetMapping("/data")
public String data(){
return service.data();
}
в том же UserController у user-service.
Для этого мы создали TestService
@Autowired
private RestTemplate template;
@HystrixCommand(fallbackMethod = "failed")
public String data() {
String response = template.getForObject("http://gallery-service/data", String.class);
LOG.log(Level.INFO, response);
return response;
}
public String failed() {
String error = "Service is not available now. Please try later";
LOG.log(Level.INFO, error);
return error;
}
Здесь мы также определили Fallback метод в случае какого-либо сбоя со стороны вызывающего сервиса.
Здест просто при помощи RestTemplate мы используем метод getForObject в котором передаем адрес и необходимый нам URL.
Посколько Feign Client по умолчанию не дружит с реактивщиной, используем известный WebClient.
WebClient, представленный в Spring 5, является неблокирующим клиентом с поддержкой Reactive Streams.
Он является частью Spring 5 под названием Spring WebFlux.
Для его использования надо включить модуль spring-webflux в проект.
Он был создан как часть модуля Spring Web Reactive и будет заменять классический RestTemplate в этих сценариях. Он по протоколу HTTP/1.1.
Для тестирования конечных точек среда Spring 5 WebFlux поставляется с классом WebTestClient.
WebTestClient - это тонкая оболочка вокруг WebClient. Вы можете использовать его для выполнения запросов и проверки ответов.
WebTestClient связывается с приложением WebFlux, используя ложный запрос и ответ, или может тестировать любой веб-сервер через соединение HTTP.
Главный вопрос - заменяет ли WebClient традиционный RestTemplate ? Да, он был разработан для этого, но RestTemplate будет продолжать существовать в Spring Framework в обозримом будущем.
Основным отличием является то, что RestTemplate выполняет синхронную блокировку. Это означает, что вызов, выполненный с использованием RestTemplate, должен ждать, пока ответ не вернется, чтобы продолжить.
Поскольку WebClient является асинхронным, вызову REST не нужно ждать ответа. Вместо этого, когда есть ответ, будет предоставлено уведомление об этом.
Компания Google выпустила gRPC, который работает поверх HTTP.2, но это не совсем так :) На самом деле он yа каждое действие отправляет обычный POST запрос (HTTP). Тем самым происходит неэффективное использование ресурсов.
Т.е. другими словами это просто обертка поверх HTTP.2
Принцип работы:
Он использует прокси (envoy) между браузером и сервером и шлёт обычные HTTP POST запросы на прокси а прокси уже шлёт HTTP.2 на сервер.
Он прост в разработке и легко поддерживается, но его минус в том, что при больших нагрузках на сервер он не может справиться с ними и это не лучшее решение в реактивной системе, когда вам очень важен перворманс. Netflix с AWS уже столкнулись с данной проблемой при использовании gRPC при построении новой системы 3 года назад.
Поэтому был выпущен новый протокол - RSocket.
RSocket - это будущее для коммуникации микросервисов в реактивной системе, когда очень важен перворманс и имеются большие обьемы данных.
О нем чуть позже.
Продолжим разбираться с WebClient.
В UserController метод
@GetMapping(value = "/getDataByWebClient",produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<Bucket> getDataByWebClient() {
return webClientService.getDataByWebClient();
}
Создаем отдельный сервис для этого WebClientService
В котором собираем WebClient в конструкторе
public WebClientService() {
this.webClient = WebClient.builder()
.baseUrl(API_BASE_URL)
.defaultHeader(HttpHeaders.CONTENT_TYPE, API_MIME_TYPE)
.defaultHeader(HttpHeaders.USER_AGENT, USER_AGENT)
.build();
}
И собственно вызываем сам наш метод
public Flux<Bucket> getDataByWebClient() {
return webClient
.get()
.uri("/stream/buckets/delay")
.exchange()
.flatMapMany(clientResponse -> clientResponse.bodyToFlux(Bucket.class));
}
-
WebClient можно создать при помощи create
WebClient webClient = WebClient.create("https://localhost:8654/getData");
-
Или при помощи builder
public WebClientService() { this.webClient = WebClient.builder() .baseUrl(API_BASE_URL) .defaultHeader(HttpHeaders.CONTENT_TYPE, API_MIME_TYPE) .defaultHeader(HttpHeaders.USER_AGENT, USER_AGENT) .build(); }
В нашем примере мы используем WebClient для получения данных из базы данных через первый сервис (gallery-service) в реактивной среде.
public Flux<Bucket> getDataByWebClient() {
return webClient
.get()
.uri("/stream/buckets/delay")
.exchange()
.flatMapMany(clientResponse -> clientResponse.bodyToFlux(Bucket.class));
}
-
мы можем указать какой именно запрос мы отправляем параметром
.get() .post() .put() .delete() .options() .head() .patch() -
предоставление URL мы передаем через
.uri
для создания URI запроса вы можете также использовать URIBuilder
.uri(uriBuilder -> uriBuilder.path("/user/repos")
.queryParam("sort", "updated")
.queryParam("direction", "desc")
.build())
- мы можем установить тело запроса (Если шлем POST запрос).
Если мы хотим установить тело запроса - есть два доступных способа:
-
Первый способ - заполнить его
BodyInserterили делегировать эту работуPublisher.body(BodyInserters.fromPublisher(Mono.just("data")), String.class);
BodyInserter - это интерфейс, отвечающий за заполнение тела ReactiveHttpOutputMessage.
BodyInserters содержит методы , чтобы создать BodyInserter из Object, Publisher, Resource, FormData, и MultipartData и т.д.
Publisher - это реактивный компонент, отвечающий за предоставление потенциально неограниченного числа последовательных элементов.
- Второй способ - это метод
body().
с помощью одного объекта
.body(BodyInserters.fromObject("data"));
c помощью MultiValueMap
LinkedMultiValueMap map = new LinkedMultiValueMap();
map.add("key1", "value1");
map.add("key2", "value2");
BodyInserter<MultiValueMap, ClientHttpRequest> inserter2
= BodyInserters.fromMultipartData(map);
Если у вас есть тело запроса в форме a Mono или a Flux, то вы можете напрямую передать его body() методу в WebClient.
Если у вас есть действительное значение вместо Publisher (Flux/Mono), вы можете использовать syncBody().
- мы можем установить заголовки, куки, приемлемые типы носителей.
Существует дополнительная поддержка наиболее часто используемых заголовков, таких как __ «If-None-Match», «If-Modified-Since», «Accept», «Accept-Charset».
.header(HttpHeaders.CONTENT__TYPE, MediaType.APPLICATION__JSON__VALUE)
.accept(MediaType.APPLICATION__JSON, MediaType.APPLICATION__XML)
.acceptCharset(Charset.forName("UTF-8"))
.ifNoneMatch("** ")
.ifModifiedSince(ZonedDateTime.now())
WebClient поддерживает фильтрацию запросов с использованием ExchangeFilterFunction.
Вы можете использовать функции фильтра для перехвата и изменения запроса любым способом.
Например, вы можете использовать функцию фильтра для добавления Authorization заголовка к каждому запросу или для регистрации деталей каждого запроса.
Вы можете добавить эту логику в функцию фильтра при создании WebClient.
WebClient webClient = WebClient.builder()
.baseUrl(MY_REPO_API_BASE_URL)
.defaultHeader(HttpHeaders.CONTENT_TYPE, GITHUB_V3_MIME_TYPE)
.filter(ExchangeFilterFunctions
.basicAuthentication(username, token))
.build();
Теперь вам не нужно добавлять Authorization заголовок в каждом запросе. Функция фильтра будет перехватывать каждый запрос WebClient и добавлять этот заголовок.
Для этого есть методы exchange или retrieve
Меттод retrieve() - является самым простым способом получить тело ответа.
Но, если вы хотите иметь больше контроля над ответом, вы можете использовать exchange() метод, который имеет доступ ко всему ClientResponse, включая все заголовки и тело.
Метод retrieve(), в WebClient бросает WebClientResponseException всегда, когда был получен ответ с кодом состоянии 4хх или 5хх.
public Flux<MyRepo> listGithubRepositories() {
return webClient.get()
.uri("/user/repos?sort={sortField}&direction={sortDirection}",
"updated", "desc")
.retrieve()
.onStatus(HttpStatus::is4xxClientError, clientResponse ->
Mono.error(new MyCustomClientException())
)
.onStatus(HttpStatus::is5xxServerError, clientResponse ->
Mono.error(new MyCustomServerException())
)
.bodyToFlux(MyRepo.class);
}
Метод exchange() не генерирует исключения в случае ответов 4xx или 5xx. Вам необходимо самостоятельно проверить коды состояния и обрабатывать их так, как вы хотите.
Вы также можете проверить статусы состояний и передать какое-то свое кастомное выполнение для их реализаций
public Flux<Bucket> getDataByWebClient() {
return webClient
.get()
.uri("/getAll")
.retrieve()
.onStatus(HttpStatus::is4xxClientError, clientResponse ->
Mono.error(new RuntimeException("4xx"))
)
.onStatus(HttpStatus::is5xxServerError, clientResponse ->
Mono.error(new RuntimeException("5xx"))
)
.onStatus(HttpStatus::is3xxRedirection, clientResponse ->
Mono.error(new MyCustomServerException())
)
.onStatus(HttpStatus::isError, clientResponse ->
Mono.error(new MyCustomServerException())
)
.bodyToFlux(Bucket.class);
}
Zuul - Это прокси, шлюз, промежуточный уровень между пользователями и вашими сервисами.
Это основанный на JVM маршрутизатор и серверный балансировщик нагрузки от Netflix.
У нас может быть несколько служб (экземпляров), работающих на разных портах.
Zuul нужен для приема внешних запросов и маршрутизации в нужные сервисы внутренней инфраструктуры
Spring Cloud нативно интегрирован с ним.
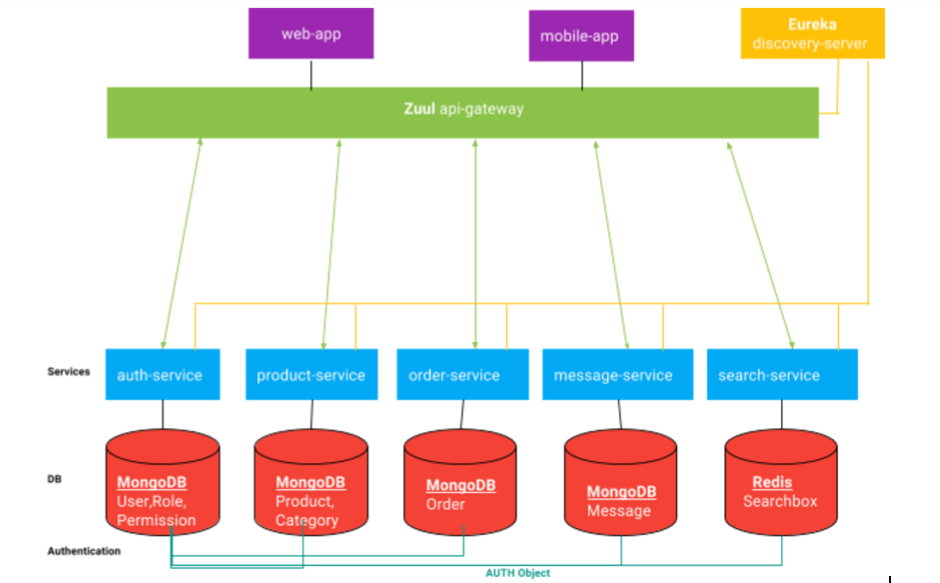
Zuul-service по ссылке на github:
https://github.com/ksereda/Gallery-Service/tree/master/zuul-service
Используется с аннотацией @EnableZuulProxy в основном классе.
Также нам надо пометить этот сервис как @EnableEurekaClient, чтобы наш Eureka Server обнаружил его и они подружились.
При старте сервиса он пошлет эхо запрос на Eureka Server и получит подтверждение от Eureka.
@SpringBootApplication
@EnableEurekaClient
@EnableZuulProxy
public class ZuulServiceApplication {
public static void main(String[] args) {
SpringApplication.run(ZuulServiceApplication.class, args);
}
}
Zuul автоматически выберет список серверов в Eureka.
Он хорошо работает в связке с Hystrix, Ribbon и Turbine.
Он запускает предварительные фильтры (pre-filters), затем передает запрос с помощью клиента Netty, а затем возвращает ответ после запуска постфильтров (post-filters).
Фильтры являются основой функциональности Zuul. Они могут выполняться в разных частях жизненного цикла “запрос-ответ”, т.к. они отвечают за бизнес-логику приложения и могут выполнять самые разные задачи.
Я также написал статью про Zuul для более подробной информации:
https://medium.com/@kirill.sereda/spring-cloud-netflix-zuul-api-gateway-%D0%BF%D0%BE-%D1%80%D1%83%D1%81%D1%81%D0%BA%D0%B8-c1e819f042e1
Фильтры написаны на Groovy, но Zuul поддерживает любой язык на основе JVM. Исходный код каждого фильтра записывается в указанный набор каталогов на сервере Zuul, которые автоматически обновляются в случае каких-либо нововведений. Обновленные фильтры считываются, динамически компилируются в работающий сервер и вызываются Zuul для каждого последующего запроса.
Zuul использует свой собственный пул подключений с помощью клиента Netty. Это сделано для того, чтобы уменьшить переключение контекста между потоками и обеспечить работоспособность. В результате весь запрос выполняется в одном и том же потоке.
Одной из ключевых функций, используемых Netflix для обеспечения отказоустойчивости, является повторная попытка отправка запроса.
-
ошибка таймаута
-
ошибка в случае кода статуса (например статус 503)
Повторный запрос отправлен не будет, в случае:
-
если утеряна часть body запроса
-
если уже был начат ответ клиенту
Начиная с версии 2.0 Zuul поддерживает отправку push-сообщения — отправку сообщений с сервера на клиент (Push-соединения отличаются от обычных HTTP-запросов тем, что они постоянны и долговечны).
Он поддерживает два протокола, WebSockets и Server Sent Events (SSE).
В нашем примере в файле application.yml
spring:
application:
name: zuul-service
server:
port: 8766
eureka:
client:
serviceUrl:
defaultZone: ${EUREKA_URI:http://localhost:8761/eureka}
instance:
preferIpAddress: true
Также мы должны настроить роутинг маршрутов на наши сервисы. Т.е. чтобы мы смогли попасть на gallery-service например не через
http://localhost:8081
А непосредственно через сам zuul!
http://localhost:8766/gallery
или на user-service
http://localhost:8766/users
Т.е. наши сервисы user-service и gallery-service ничего не знают друг о друге и не знают ничего о zuul. Это слабая связанность наших сервисов, что является одним из приемуществом использования данной архитектуры. Нам вообще не важно где находится например gallery-service. Нам даже не надо знать на каком порту, его адрес и прочее. Нам надо знать только его имя, и все!
Это очень удобно, правда ?
Для этого добавим такие настройки
zuul:
routes:
auth-service:
strip-prefix: false
sensitive-headers: Cookie,Set-Cookie
path: /auth/**
service-id: security-service
gallery-service:
path: /gallery/**
service-id: gallery-service
user-service:
path: /users/**
service-id: user-service
Также необходимо указать вот такуой параметр
zuul.ignored-services=*
которая означает, что если мы запустим наш zuul-service и перейдем по адресу
http://localhost:8766/gallery
мы попадем на наш gallery-service и дальше сможим ходить по всем его урлам без проблем. Наш zuul будет автоматически перенаправлять на все его урлы.
Также в zuul-service я настроил JWT Security.
Сейчас перейдем непосредственно к самому security-service.
Настроим здесь JWT Security для нашего user-service.
Также помечаем наш сервис как @EnableEurekaClient.
В файле application.yml указываем имя нашему сервисы, порт, и информацию про Eureka Server. Этого достаточно.
spring:
application:
name: security-service
server:
port: 9100
eureka:
client:
serviceUrl:
defaultZone: ${EUREKA_URI:http://localhost:8761/eureka}
instance:
preferIpAddress: true
-
Пользователь отправляет запрос на получение токена, передающего его учетные данные.
-
Сервер проверяет учетные данные и отправляет обратно токен.
-
При каждом запросе пользователь должен предоставить токен, и сервер будет проверять этот токен.
Для начала нам надо проверить токен.
Это может быть реализовано в самой службе аутентификации, и zuul должен вызвать службу аутентификации, чтобы проверить токен, прежде чем разрешить запросам перейти к любому сервису.
Вместо этого мы можем проверить токены на уровне zuul и позволить службе аутентификации проверять учетные данные пользователя и выдавать токены.
Мы будем блокировать запросы, если они не аутентифицированы (кроме запросов на генерацию токенов).
Давайте как раз это и сделаем.
Как я писал выше, мы настроили кое-что связанное с security в модуле zull-service. Вы можете увидеть все это в коде на github:
https://github.com/ksereda/Gallery-Service/tree/master/zuul-service
В zuul-service нам нужно сделать две вещи:
-
проверять токены с каждым запросом
-
предотвращать все неаутентифицированные запросы к нашим службам.
В классе SecurityTokenConfig мы определяем наши конфигурации безопасности.
В классе JwtTokenAuthenticationFilter мы реализовываем наш фильтр, который проверяет токены (используем OncePerRequestFilter)
Теперь перейдем к нашему security-service:
Здесь нам надо:
-
проверить учетные данные пользователя и, если он действителен, то
-
сгенерировать токен, в противном случае выдать исключение.
Точно также как и в zuul-service, здесь мы создаем класс SecurityCredentialsConfig (определяем наши конфигурации безопасности).
Также нам надо сделать фильтр:
Мы используем JwtUsernameAndPasswordAuthenticationFilter.
Он используется для проверки учетных данных пользователя и создания токенов.
Имя пользователя и пароль должны быть отправлены в запросе POST.
Запустите вначале Eureka Server. Затем запустите gallery-service, user-service, zuul-service, security-service.
Сначала попробуем получить доступ к gallery-service без токена (через наш zuul-service, а не напрямую в gallery-service)
localhost:8766/gallery
Вы должны получить несанкционированную ошибку
{
"timestamp": "...",
"status": 401,
"error": "Unauthorized",
"message": "No message available",
"path": "/ gallery /"
}
Для того, чтобы получить токен, отправьте POST запрос на наш zuul-service через Postman (например)
POST
localhost:8766/auth
{
"username":"admin",
"password":"admin"
}
При условии что у вас установлено
Content-Type - application/json Accept - application/json
В ответе в Headers вы получити сгенерированный токен.
Скопируйте и вставьте его в Authorization - и выерите там Bearer token
А теперь отправьте запрос на gallery-service через наш zuul-service (как было сделано выше)
localhost:8766/gallery
Теперь вы не получите ошибку аутентификации. Все должно быть в порядке.
Если вы используете несколько экземпляров сервиса галереи, каждый из которых работает на своем порту, то запросы будут равномерно распределены между ними.
Ссылка на user-service на Пithub:
https://github.com/ksereda/Gallery-Service/tree/master/security-service
Создадим общий сервис config-server, который будет содержать ссылки на хранилище с общими настройками. Чтобы не писать одинаковый код в разных сервисах, будем использовать общее хранилище настроек.
Мы рассмотрим оба варианта:
-
хранение настроек локально
-
хранение настроек на github
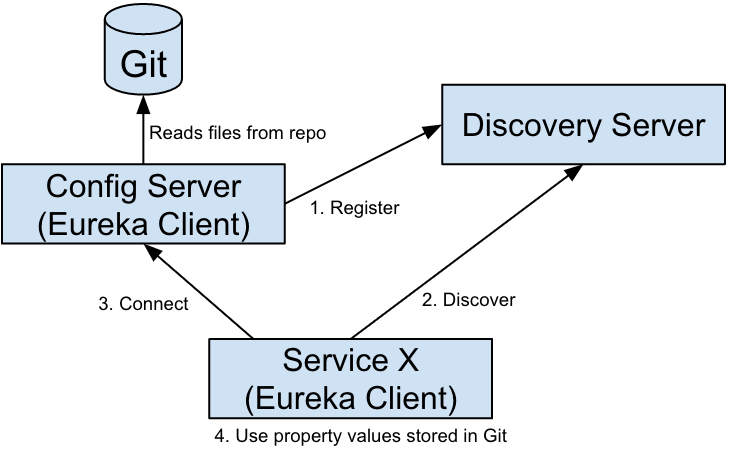
По умолчанию будем использовать локальный способ хранения (откуда другие сервисы будут считывать настройки - коннекшен к базе).
Используется с аннотацией
@EnableConfigServer
Также необходимо добавить зависимость
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
В файле application.yml
server:
port: 8888
spring:
application:
name: config-server
Указываем 2 способа хранения
spring:
profiles:
active: native
---
spring:
profiles: native
cloud:
config:
server:
native:
search-locations:
/home/ks/IdeaProjects/Gallery-Service/ms-config-properties/{application}/{profile},
---
spring:
profiles: git
cloud:
config:
server:
git:
uri: https://github.com/ksereda/Gallery-Service/
search-paths:
- "ms-config-properties/{application}/{profile}"
По умолчанию - локальный.
И создадим папку ms-config-properties в которой будут лежать сами настройки.
Рассмотрим на примере gallery-service.
Создаем внутри папку с идентичным названием нашего сервиса (gallery-service), в которой мы используем разные профили.
По умолчанию у нас профиль default.
Внутри должен быть файл с названием сервиса - gallery-service.yml, в котором будем прописывать настройки (какие хотим).
Теперь вернемся в наш gallery-service: в нем должна быть указана аннотация
@EnableConfigClient
чтобы указать, что он также является конфиг клиентом.
Также в application.yml файл нашего gallery-service необходимо добавить следующие настройки
cloud:
config:
discovery:
enabled: true
service-id: config-server
чтобы указать ему путь к config-server.
Теперь когда вы запустите ваш gallery-service, он по умолчанию зарегистрируется в Eureka и будет образаться к config-server, который уже будет направлять его в локальное хранилище с настройками.
Далее происходит получение настроек среди всех следующим образом:
Он смотрит на {application} - имя сервиса (в нашем примере это gallery-service), и далее на {profile} - профиль по умолчанию у нас default.
Это необходимо сделать не только для gallery-service, но и для всех остальных сервисов, которые исопльзуют какие-либо настройки. Чтобы не плодить конфиг в самих сервисах, лучше вынести их в отдельный сервис, который отвечает за это.
Ссылки на github:
https://github.com/ksereda/Gallery-Service/tree/master/config-server
https://github.com/ksereda/Gallery-Service/tree/master/ms-config-properties
Ribbon - это балансировщик нагрузки.
Из коробки он интегрирован с механизмом Service Discovery, который предоставляет динамический список доступных инстансов для балансировки между ними.
Но мы можем явно настроить его.
Представьте, что у вас есть распределенная система, которая имеет много приложений, работающих на разных компьютерах. Но если количество пользователей большое, приложение обычно cоздает разные реплики, каждая реплика работает на отдельном компьютере. В это время появляется "Load Balancer" (Балансировка нагрузки), которая помогает распределять входящий траффик равно между серверами.

Ribbon предоставляет:
-
Отказоустойчивость
-
Load balancing
-
Поддержка нескольких протоколов (HTTP, TCP, UDP) в асинхронной и реактивной модели
-
Кеширование
и т.д.
Eсть 2 вида LoadBalancer:
- Server side Load Balancer
Расположен на стороне сервера. Когда запросы поступают от Client они придут к балансировке нагрузки, и она определит один сервер для этого запроса. Самый простой алгоритм, используемый балансировкой нагрузки, это случайное распределение.
- Client-Side Load Balancer
Когда балансировка нагрузки находится на стороне клиента, она сама решает к какому серверу отправить запрос, основываясь на некоторых критериях.
Существуют такие понятия, как:
-
Список серверов (List Of Servers): Наш сервис должен получить необходимую информацию, расположенную на других сервисах от разных производителей. У нас есть список этих серверов. Он включает в себя сервера, которые напрямую сконфигурированы в нашем сервисе.
-
Фильтрованный список серверов (Filtered List of Servers): Например некоторые сервера заняты или недоступны сейчас. Наш сервис отбросит эти сервера из списка, и в конце будет список более подходящих серверов (фильтрованнный список).
-
Load Balancer (Ribbon): Есть некоторые стратегии для решения. Но они обычно основываются на "Rule Component" (Компонент правил). По умолчанию Spring Cloud Ribbon использует стратегию
ZoneAwareLoadBalancer(Сервера в одной зоне (zone) с нашим сервисом). -
Ping: Ping - это способ, который использует наш сервис для быстрой проверки работает ли на тот момент сервис или нет? Eureka занимается этим по умолчанию, но Spring Cloud позволяет вам кастомизировать проверку по вашему усмотрению.
Мы сделали movie-service, который представляет обычный CRUD, работающий с базой MongoDB а порту 27018 (в docker).
также м сделали реплику этого movie-service:
смотри чуть ниже как сделать реплику сервиса.
Запуск MongoDB на порту 27018
docker run mongo --port 27018
В user-service мы добавили
@RibbonClient(name = "movie-service", configuration = RibbonConfiguration.class)
Теперь наш основной класс user-service выглядит следующим образом
@SpringBootApplication
@EnableEurekaClient
@EnableFeignClients
@RibbonClient(name = "movie-service", configuration = RibbonConfiguration.class)
public class UserServiceApplication {
public static void main(String[] args) {
SpringApplication.run(UserServiceApplication.class, args);
}
// Create a bean for restTemplate to call services
@Bean
@LoadBalanced // Load balance between service instances running at different ports.
public RestTemplate restTemplate() {
return new RestTemplate();
}
// for using WebClient
public @Bean
WebClient webClient() {
return WebClient.builder().clientConnector(new ReactorClientHttpConnector()).baseUrl("http://localhost:8081").build();
}
}
чтобы он сам определял, на какой сервис стучаться (на сам movie-service или на его реплику, в зависимости от нагрузки на сам movie-service).
Также в user-service создаем класс RibbonConfiguration.
Теперь нам нужно создать еще один класс конфигурации для Ribbon, чтобы упомянуть алгоритм балансировки нагрузки и проверку работоспособности.
Теперь мы будем использовать значение по умолчанию, предоставленное Ribbon, но в этом классе мы можем переопределить их и добавить нашу собственную логику.
Я добавил MovieController, в котором при помощи RestTemplate мы получаем данные из сервиса movie-service (как было рассмотрено ранее, только для gallery-service).
В файле application.yml у нас появились дополнительные записи
movie-service:
ribbon:
eureka:
enabled: true
ServerListRefreshInterval: 1000
#movie-service:
# ribbon:
# listOfServers: localhost:8085,localhost:8086
# eureka:
# enabled: true
Вторая настройка закомментирована, но мы можем включить ее, чтобы вручную добавить серверы к этому балансировщику нагрузки в его список. Но по умолчанию Load Balancer сам будет смотреть и балансировать сервисы.
Если мы выключим первую настройку и включим вторую, то если вы запустите новый экземпляр микросервиса на другом порту (например 8057, которого нет в списке), Ribbon не отправит запрос новому экземпляру, пока мы не зарегистрируем его вручную в Ribbon (пока не добавим в этот список).
Делаем jar файл для movie-service и запускаем ее на другом порту 8086 (сам movie-service на 8085 порту).
Делаем jar файл для movie-service
maven install
и запускаем ее на другом порту 8086 (сам movie-service на 8085 порту).
java -jar -Dserver.port=8086 movie-service-0.0.1-SNAPSHOT.jar
Сейчас мы сэмулировали ситуацию, когда наша реплика не обязательно работает на этом же сервере и даже она может работать в другом часовом поясе. Для нас это не имеет никакого значения, ведь у нас для этого есть Eureka Server :)
У нас запущен Eureka Server, user-service, movie-service, реплика movie-service на порту 8086
Теперь когда шлем запрос из user-service на movie-service
localhost:8082/getAllMovies
получаем список всех фильмовю
Если пошлем запрос на получение стартовой страницы movie-service
localhost:8082/get
Мы увидим главную страницу сервиса movie-service, на которой отображается его имя и порт, на котором он запущен.
Если мы попробуем несколько раз обновить страницу по этому запросу, то увидим как меняется порт, т.к. Ribbon определяет сам, какому сервису (movie-service либо его реплике запущенной на другом порту необходимо обратиться, в зависимости от нагрузки).
Очень удобно.
Мы также можем сами указать какие сервисы мы хотим на каких портах балансировать, при помощи второй натсройки (которая была у нас закомментирована).
Вообще Ribbon позволяет производить более гибкую настройку на ваш вкус.
Ссылка на movie-service на github:
https://github.com/ksereda/Gallery-Service/tree/master/movie-service
Сделаем несколько реплик для нашего Eureka Server.
Сейчас мы сэмитируем создание реплики для Eureka Server, чтобы развернуть их на разных серверах, каждая реплика будет работать на отдельном доменном имени. Здесь мы предполагаем, что система имеет много пользователей поэтому нужно чтобы много реплик работали на разных серверах для уменьшения нагрузки. Якобы наши реплики работают в разных странах, как это часто бывает в релаьном мире.
Мы симулируем создание 2 реплик и развертываем из на 2-х разных серверах, с 2-мя разными доменными именами.
в файле /etc/hosts (я использую ubuntu) добавляем записи
127.0.0.1 my-eureka-server.com
127.0.0.1 my-eureka-server-us.com
127.0.0.1 my-eureka-server-fr.com
Обратите внимание на файл application.yml в Eureka Server - то, что закомментировано (# FOR EUREKA REPLICAS EXAMPLE)
Теперь закомментируйте то что у вас сейчас есть и раскомментируйте то что закомментировано :)
Сделайте jar файл
maven install
Разложите их по разным папкам для удобства.
Запускаем из консоли так
java -jar -Dspring.profiles.active=france eureka-server-0.0.1-SNAPSHOT.jar
java -jar -Dspring.profiles.active=united-states eureka-server-0.0.1-SNAPSHOT.jar
Теперь можем в браузере
http://my-eureka-server-us.com:9001
http://my-eureka-server-fr.com:9002
Вы увидите Eureka dashboard, и заметьте, что каждая из этих реплик видит друг друга и основной Eureka Server.
Запускаем реплики Eureka Server (см выше).
В gallery-service я создал TestController, в котором сделал пару методов:
- showAllServices
this.discoveryClient.getServices();
- showService - информация по конкретному сервису, который он увидел (по ID)
this.discoveryClient.getInstances(serviceId);
Там мы увидим информацию по сервисам (краткость - сестра таланта):
html += "<h3>Instance: " + serviceInstance.getUri() + "</h3>";
html += "Host: " + serviceInstance.getHost() + "<br>";
html += "Port: " + serviceInstance.getPort() + "<br>";
Изменили application.yml для gallery-service.
Закомментировали все что было и раскомментировали то что сейчас закомментировано :)
А именно gallery-service мы в настройках указали не саму Eureka Server, а одну из ее реплик, чтоб интересней было.
Т.е. сейчас gallery-service завязан не на Eureka Server, а на одну из ее реплик, которая якобы работает в другой доменной зоне.
defaultZone: http://my-eureka-server-us.com:9001/eureka
Делаем jar файл для gallery-service и копируем в другую папку.
maven install
Запускаем сам gallery-service.
Запускаем его реплику (имитируем ситуацию, будто бы она находится на другой еврике (которая тоже реплика) в другой стране например), у нее другой домен.
java -jar -Dspring.profiles.active=gallery-service-replica01 gallery-service-0.0.1-SNAPSHOT.jar
Идем на Eureka Server replica, ведь на ней сейчас наш gallery-service зарегистрирован
http://my-eureka-server-us.com:9001
и увидим там уже не один запущенный gallery-service, а 2 (т.к. у нас вторая - это реплика).
Идем на сам gallery-service
localhost:8081
видим что он видит Eureka Server replica и видит свою реплику (gallery-service replica).
Идем на реплику gallery-service, и видим что он видит Eureka Server replica и сам оригинальный gallery-service.
Теперь давайте настроим ELK и подключим его к нашему user-service ля получения всех логов.
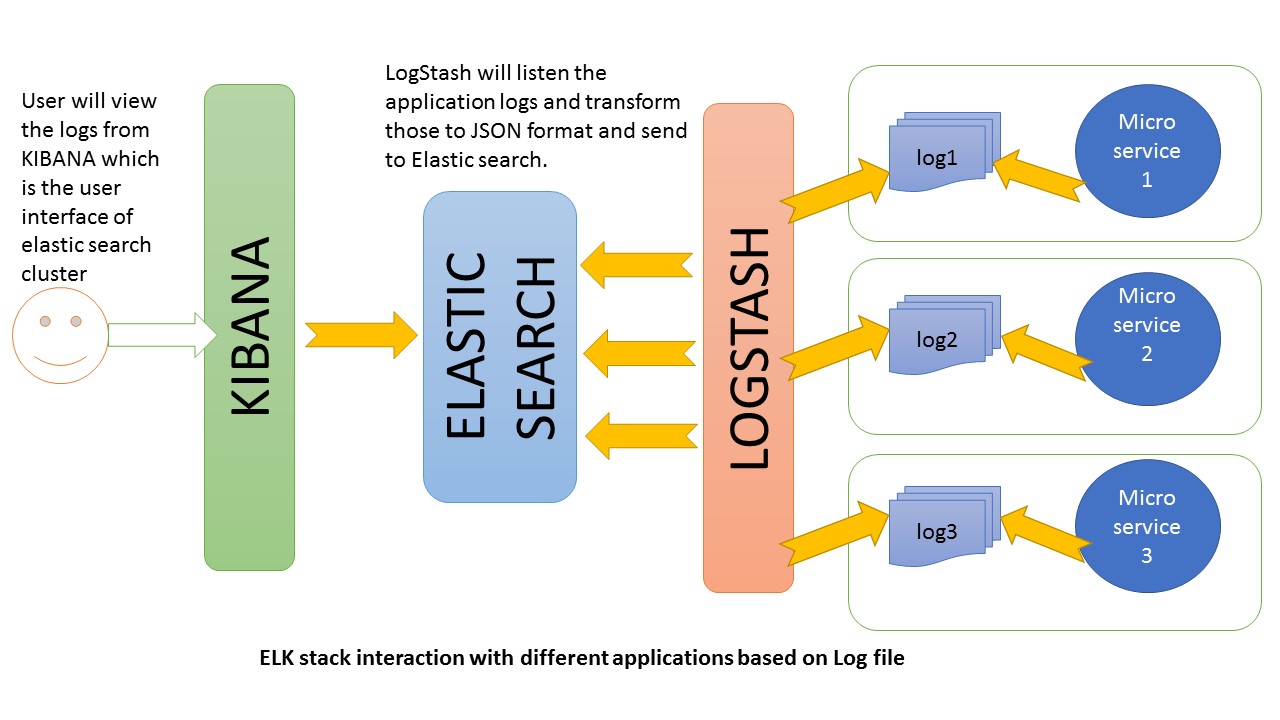
Установите по очереди
-
elasticsearch
-
logstash
-
kibana
В ubuntu по умолчанию ставится в
/usr/share/logstash/
и
/etc/logstash/
В /etc/logstash/ создайте файл logstash.conf со следующим содержимым
input {
file {
type => "java"
# Logstash insists on absolute paths...
path => "/home/ks/logs/application.log"
codec => multiline {
pattern => "^%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME}.*"
negate => "true"
what => "previous"
}
}
}
filter {
#If log line contains tab character followed by 'at' then we will tag that entry as stacktrace
if [message] =~ "\tat" {
grok {
match => ["message", "^(\tat)"]
add_tag => ["stacktrace"]
}
}
#Grokking Spring Boot's default log format
grok {
match => [ "message",
"(?<timestamp>%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME}) %{LOGLEVEL:level} %{NUMBER:pid} --- \[(?<thread>[A-Za-z0-9-]+)\] [A-Za-z0-9.]*\.(?<class>[A-Za-z0-9#_]+)\s*:\s+(?<logmessage>.*)",
"message",
"(?<timestamp>%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{TIME}) %{LOGLEVEL:level} %{NUMBER:pid} --- .+? :\s+(?<logmessage>.*)"
]
}
#Parsing out timestamps which are in timestamp field thanks to previous grok section
date {
match => [ "timestamp" , "yyyy-MM-dd HH:mm:ss.SSS" ]
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch{
hosts=>["localhost:9200"]
index=>"todo-logstash-%{+YYYY.MM.dd}"
}
}
Ваш индекс называется todo-logstash.
Точно такой же файл создайте в корне проекта в IDEA. Только укажите свой путь к сохраняемому файлу с логами
У меня это
path => "/home/ks/logs/application.log"
В коде в IDEA мы должны указать логгер и залогировать то что нам нужно.
Например в контроллере мы залогируем стартовую страницу.
private static final Logger LOG = Logger.getLogger(UserController.class.getName());
@RequestMapping("/")
public String home() {
String home = "User-Service running at port: " + env.getProperty("local.server.port");
LOG.log(Level.INFO, home);
return home;
}
А это импорты
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
Далее запускаем:
-
elasticsearch
sudo service elasticsearch start
-
logstash
переходим в папку
cd /usr/share/logstash
и там в консоли пишем
bin/logstash --verbose -f /etc/logstash/logstash.conf
т.е. запускаем logstash с нашими новыми настройками, которые мы создали (logstash.conf)
-
kibana
service kibana start
Идем в браузере на
http://localhost:9200/
и видим что elasticsearch работает
Здесь
http://localhost:9200/_cat/indices
видим все наши индексы.
И сейчас стартуем приложение в IDEA и мы здесь увидим наш новый индекс todo-logstash
http://localhost:9200/_cat/indices
Также можем протестировать:
в консоли пишем
curl -XGET http://127.0.0.1:9200
если получим ответ наподобие
{
"name" : "ks-pc",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "dZ2ldEdWSRGHwdMHydMslQ",
"version" : {
"number" : "7.3.1",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "4749ba6",
"build_date" : "2019-08-19T20:19:25.651794Z",
"build_snapshot" : false,
"lucene_version" : "8.1.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
значит все хорошо.
Идем дальше.
Теперь идем в kibana
http://localhost:5601
Слева в меню (самая последняя) - Management - там выбираем Index Patterns - и там Create index pattern.
Пишите имя нашего индекса
todo-logstash
и он должен увидеть его. Жмем Next step - выбираем в списке timestamp - Ok.
Индекс создан.
Идем слева в меню в Discover (самый верхний пункт в меню слева) - там выбираем слева в окошке этот индекс.
Отправляем любым удобным способом запрос (браузер, Postman, консоль) и жмякаем на кнопку Refresh.
Мы увидим все наши запросы. Они будут попадать сюда посредством логера, который мы указали в классах в коде.
Hystrix - библиотека задержек и отказоустойчивости, которая помогает контролировать взаимодействие между службами, обеспечивая отказоустойчивость и устойчивость к задержкам, благодаря чему повышается устойчивость всей системы в целом.
Другими словами можно сказать, что Hystrix — это имплементация паттерна Circuit Breaker. Основная идея состоит в том, чтобы остановить каскадный отказ в распределенной системе сервисов, состоящей из их большого числа. Это позволяет отдавать ошибку на раннем этапе и давая возможность "упавшему"" сервису восстановить свою работоспособность.
Hystrix позволяет определить fallback-метод, который будет вызван при неуспешном вызове. Что будет в этом fallback-методе уже решать вам.
Более подробно вы можете прочитать в моей статье, посвященной паттерну Circuit Breaker:
https://medium.com/@kirill.sereda/%D1%81%D1%82%D1%80%D0%B0%D1%82%D0%B5%D0%B3%D0%B8%D0%B8-%D0%BE%D0%B1%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D0%BA%D0%B8-%D0%BE%D1%88%D0%B8%D0%B1%D0%BE%D0%BA-circuit-breaker-pattern-650232944e37
Если вы используете Hystrix вместе с Feign Client, то чтобы это заработало необходимо в настройках указать
feign:
hystrix:
enabled: true
Естественно, для того, чтобы понять, что происходит с вашей системой, насколько она эффективна, нужно собирать метрики.
В user-service добавили настройки
management:
endpoints:
web:
exposure:
include: hystrix.stream
А также в класс TestService
@HystrixCommand(fallbackMethod = "failed")
в нашем случае метод работает через RestTemplate чтобы постучаться в gallery-service сервис и взять оттуда данные.
Теперь идем в браузер
localhost:8082/hystrix
Открывается Hystrix Dashboard

Введите туда
localhost:8082/actuator/hystrix.stream
любое значение (скажем 2000) и имя (произвольное).
Теерь попробуйте получить данные у gallery-service
curl http://localhost:8082/data
Посомтрите в Hystrix Dashboard - вы увидите изменяющееся значение в режиме реального времени. Выполните запрос несколько раз.
Теперь выключили gallery-service и попробуйте выполнить этот же запрос еще несколько раз подряд.
Обратите внимание что в Hystrix Dashboard теперь будут отображаться неудачные попытки (красные цифры).

Я привел простой пример работы Hystrix в случае недоступности удаленного сервиса. На самом деле при помощи Hystrix можно выполнять разные невероятные вещи. Можно очень гибко настроить вашу систему, если вам очень важен перфоманс и устойчивость к ошибкам.
Давайте добавим Spring Cloud Sleuth в наш проект.
Для примеры добавим его в
user-service
gallery-service
Напоминаю, что user-service общается с gallery-service посредством RestTemplate, Feign Client и WebClient (все 3 примера для наглядности).
Получается сборная солянка, но мы это все делаем ради изучения возможностей. Так что вперед.
В user-service и gallery-service lобавляем зависимости
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
Остановимся на user-service.
В UserController в методах добавим вот такую штуковину:
Заменим тот логгер, что у на сбыл на следующий
Импорт:
import java.util.logging.Logger;
Логгер:
Logger logger = java.util.logging.Logger.getLogger(UserController.class.getName());
В ендпоинт для стартовой страницы добавим его
@RequestMapping("/")
public String home() {
String home = "User-Service running at port: " + env.getProperty("local.server.port");
logger.info(home);
return home;
}
Сделаем то же самое для остальных методов.
@RestController
@RequestMapping("/")
public class UserController {
Logger logger = java.util.logging.Logger.getLogger(UserController.class.getName());
@Autowired
private Environment env;
@Autowired
private RestTemplate restTemplate;
@Autowired
private WebClient webClient;
@Autowired
private TestService service;
@Autowired
private WebClientService webClientService;
@RequestMapping("/")
public String home() {
String home = "User-Service running at port: " + env.getProperty("local.server.port");
logger.info(home);
return home;
}
// Using Feign Client
@RequestMapping(path = "/getAllDataFromGalleryService")
public List<Bucket> getDataByFeignClient() {
List<Bucket> list = ServiceFeignClient.FeignHolder.create().getAllEmployeesList();
logger.info("Calling through Feign Client");
return list;
}
// Using RestTemplate
@GetMapping("/data")
public String data() {
logger.info("Calling through RestTemplate");
return service.data();
}
// Using WebClient
@GetMapping(value = "/getDataByWebClient",produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<Bucket> getDataByWebClient() {
logger.info("Calling through WebClient");
return webClientService.getDataByWebClient();
}
@ExceptionHandler(DataAccessException.class)
public ResponseEntity<MyCustomServerException> handleWebClientResponseException(DataAccessException ex) {
return ResponseEntity.status(HttpStatus.NOT_FOUND).body(new MyCustomServerException("A Bucket with the same title already exists"));
}
}
Также заменим его в классе Fallback, используемого для ServiceFeignClient в случае ошибки соединения с gallery-service.
Теперь займемся gallery-service.
В BucketController добавим логгер в методы приветствия и получения данных из базы.
Напомню, что метод getAllEmployeesList - этот тот самый метод, который user-service вызывает у gallery-service, чтобы получить данные из базы через Feign Client,
метод data - через RestTemplate,
метод streamAllBucketsDelay - через WebClient (реактивность рулит :).
Остальные методы опустим, они нам пока не нужны.
Logger logger = java.util.logging.Logger.getLogger(BucketController.class.getName());
@RequestMapping("/")
public String home() {
String home = "Gallery-Service running at port: " + env.getProperty("local.server.port");
logger.info(home);
return home;
}
@GetMapping(path = "/show")
public Flux<Bucket> getAllEmployeesList() {
logger.info("Get data from database");
return bucketRepository.findAll();
}
@GetMapping("/data")
public Flux<Bucket> data() {
logger.info("Get data from database (RestTemplate on User-Service side");
return bucketRepository.findAll();
}
@GetMapping(value = "/stream/buckets/delay", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<Bucket> streamAllBucketsDelay() {
logger.info("Get data from database (WebClient on User-Service side");
return bucketRepository.findAll().delayElements(Duration.ofSeconds(2));
}
Запускем Eureka-Server, затем mongodb в докере (об этом писал выше статье), затем Gallery-Service, затем User-Service.
Идем на user-service и вызываем
стартовую страницу
localhost:8082
В консоли мы увидим
2019-11-07 17:53:26.237 INFO [user-service,a244a7cc14562192,a244a7cc14562192,false] 13967 --- [nio-8082-exec-1] c.e.u.controller.UserController : User-Service running at port: 8082
Отлично.
Это основная информация, добавленная Sleuth в формате
[application name, traceId, spanId, export]
где
application name - это имя приложения, указанное в application.yml
traceId - ID, назначаемый каждому запросу.
spanId - используется для отслеживания работы. Каждый запрос может иметь несколько шагов, каждый шаг имеет свой уникальный spanId.
export - это флаг, который указывает, следует ли экспортировать определенный журнал в инструмент агрегирования журналов, такой как Zipkin.
Теперь вызываем метод через Feign Client
localhost:8080/getAllDataFromGalleryService
В консоли видим
2019-11-07 17:55:07.440 INFO [user-service,4296c77df761a629,4296c77df761a629,false] 13967 --- [nio-8082-exec-6] c.e.u.controller.UserController : Calling through Feign Client
Смотрим в консоли gallery-service и видим
2019-11-07 17:55:07.399 INFO [gallery-service,5cf55a267ea457ba,5cf55a267ea457ba,false] 13750 --- [nio-8081-exec-1] c.e.g.controller.BucketController : Get data from database (Feign Client on User-Service side
Теперь вызываем через RestTemplate
localhost:8082/data
В консоли user-service видим
2019-11-07 17:57:49.069 INFO [user-service,e6738131497b256d,e6738131497b256d,false] 13967 --- [nio-8082-exec-2] c.e.u.controller.UserController : Calling through RestTemplate
а в консоли gallery-service
2019-11-07 17:57:49.090 INFO [gallery-service,e6738131497b256d,22c606c36ed48e63,false] 13750 --- [nio-8081-exec-6] c.e.g.controller.BucketController : Get data from database (RestTemplate on User-Service side
И также для WebClient.
Настоящая проблема кроется здесь не в том, чтобы идентифицировать журналы в пределах одного микросервиса, а в том, чтобы отслеживать цепочку запросов между несколькими микросервисами.
Именно параметр traceId - это то, что позволит вам отслеживать запрос при его переходе от одного сервиса к другому.
Это будет работать аналогично, если одно приложение с поддержкой Sleuth вызывало другое, передавая traceId и spanId в заголовках.
Если вы используете Feign от Spring Cloud Netflix, информация трассировки также будет добавлена к этим запросам. Кроме того, Zuul из Spring Cloud Netflix также будет перенаправлять заголовки через прокси в другие сервисы. Это очень удобно!
Например вы используете ELK для сбора и анализа логов с ваших микросервисов. Используя Sleuth, вы можете легко выполнять поиск по всем собранным журналам при помощи traceId и видеть, как запрос передается от одного микросервиса к следующему.
Если вдруг вы захотите видеть информацию о времени, вы можете воспользоваться Zipkin.
Давайте займемся этим.
Добавьте новые зависимость в ваши сервисы
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
Далее установите и запустите Zipkin
Вы можете установить Zipkin следуюшим образом:
-
Запустить с помощью docker
docker run -d -p 9411:9411 openzipkin/zipkin
-
Скачать с сайта (нужна минимум java 8 или выше)
curl -sSL https://zipkin.io/quickstart.sh | bash -s java -jar zipkin.jar
Более детальный разбор вы можете прочитать в моей статье про Sleuth + Zipkin.
Перейдите по урлу
localhost:9411 и вы увидите веб интерфейс Zipkin
В свои сервисы в application.yml необходимо добавить
spring:
zipkin:
baseUrl: http://localhost:9411/
sleuth:
sampler:
probability: 100
для интеграции с Zipkin.
baseUrl свойство сообщает Spring и Sleuth куда передавать данные. Кроме того, по умолчанию Spring Cloud Sleuth устанавливает все диапазоны как неэкспортируемые (4-ый параметр export = false).
Чтобы установить export в true необходимо установить частоту дискретизации, используя sampler.probability свойство = 100.
Запускем Eureka-Server, mongo, Gallery-Service, User-Service.
Открываем Zipkin
localhost:9411

Вызываем стартовую страницу user-service
localhost:8082
В Zipkin жмем на Find Traces - видим текущий запрос


Теперь из user-service вызываем gallery-service (для примера через RestTemplate)
localhost:8082/data
В Zipkin видим новый запрос

Жмем на него и видим более детальную картину с временем выполнения. Красота.


Теперь можем выборочно посмотреть длительность запроса как на стороне user-service так и на стороне gallery-service.
С помощью такого подхода можно выстроить очень мощный инструмент для мониторинга вашей системы.
В следующих частях нашей статьи мы Sleuth и Zipkin свяжем с ELK.
Теперь попробуем добавить пару тройку сервисов к уже существующему зоопарку и настроим коммуникацию между ними посредством Spring Cloud Stream и Kafka.
У нас будет order-service, который будет публиковать сообщения о заказах в брокер.
Также у нас будет сервис bucket-service, который будет подписан на брокера - он будет брать из брокера сообщения и обрабатывать заказы (добавлять к ним статус checked).
После обработки заказа bucket-service будет слать подтверждение в брокер, а сервис store-service будет получать обработанные ответы и складировать их на складе (выводить в консоль).
Для более подробного ознакомления по Spring Cloud Stream осмелюсь порекомендовать свою статью
https://medium.com/@kirill.sereda/spring-cloud-stream-%D0%BF%D0%BE-%D1%80%D1%83%D1%81%D1%81%D0%BA%D0%B8-570568977e3f
Поехали.
Небольшое введение в Spring Cloud Stream:
В чем заключается вся прелесть и простота Spring Cloud Stream ?
Есть такие понятия, как:
Sink- представляет базовую структуру для создания необходимых привязок (очередь, тема и т.д.) - на принимающей стороне (подписчик),Source- противоположность Sink. Он используется на публикующей стороне (издатель). Source и Sink являются связующими интерфейсами, предоставляемыми Spring Cloud Stream. Мы будем использовать объект класса Source для публикации объекта Message в RabbitMQ.Processor- может использоваться для приложения, имеющего как входящий, так и исходящий канал.
В нашем order-service будет использовать Source интерфейс.
Модель:
@Data
@AllArgsConstructor
public class Order {
private final int id;
private final String type;
private final String name;
}
И простой сервис слой
import com.example.orderservice.model.Order;
import lombok.AllArgsConstructor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.scheduling.annotation.EnableScheduling;
import org.springframework.scheduling.annotation.Scheduled;
@EnableBinding(Source.class)
@EnableScheduling
@AllArgsConstructor
class SenderService {
private final Source source;
@Autowired
private final TicketGenerator ticketGenerator;
@Scheduled(fixedRate = 5000)
private void sendMessage() {
Order editedOrder = ticketGenerator.createOrderForSend();
System.out.println(editedOrder);
source.output().send(MessageBuilder.withPayload(editedOrder).build());
}
}
Здесь формируется произвольный заказ каждые 5 секунд и отправляется в брокер.
Файл настроек application.properties
server.port=8033
spring.cloud.stream.bindings.output.destination=bucket
spring.cloud.stream.bindings.output.group=bucket
Идем дальше. Сделаем bucket-service, который будет принимать заказы (@StreamListener(Processor.INPUT)) и добавлять к ним статус checked и слать измененные заказы в брокер (@SendTo(Processor.OUTPUT)).
Модель
@Data
@AllArgsConstructor
@Document(collection = "orders")
public class Order {
private final int id;
private final String type;
private final String name;
private final String status;
}
Здесь мы к существующему заказу будем добавлять статус.
Сервис слой
import com.example.bucketservice.model.Order;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.messaging.Processor;
import org.springframework.integration.annotation.MessageEndpoint;
import org.springframework.messaging.handler.annotation.SendTo;
@EnableBinding(Processor.class)
@MessageEndpoint
public class CheckOrderService {
@StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
Order transform(Order order) {
Order checkedOrder = new Order(order.getId(),
order.getType(),
order.getName(),
"checked");
System.out.println(checkedOrder);
return checkedOrder;
}
}
Файл настроек application.properties
server.port=8044
spring.cloud.stream.bindings.input.destination=bucket
spring.cloud.stream.bindings.input.group=bucket
spring.cloud.stream.bindings.input.binder=kafka
spring.cloud.stream.bindings.output.destination=store
spring.cloud.stream.bindings.output.group=store
spring.cloud.stream.bindings.output.binder=kafka
Обратите внимание, что для order-service (он отправляет сообщение в брокер) указан output.destination
spring.cloud.stream.bindings.output.destination=bucket
а для bucket-service (он читает из брокера сообщение, которое ему послал order-service) указан input.destination
spring.cloud.stream.bindings.input.destination=bucket
и также для отношения bucket-service (он принял сообщение от order-service, зменил его (добавил статус) и отправил сообщение опять в брокер для store-service) и store-service (который читает сообщение из брокера, которое ему послал bucket-service).
Здесь и кроется вся магия Spring Cloud Stream + вспомогательные интерфейсы Sink, Source и Processor.
Как по мне, так это гораздо удобней чем писать (или копипастить) уже написанный код для подключения сервиса к брокеру, будь то RabbitMQ или Kafka. Все очень быстро, красиво и без лишнего кода, который уже спрятан внутри этой реализации.
И наконец store-service.
Модель аналогичная.
Сервис слой.
import com.example.storeservice.model.Order;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.annotation.StreamListener;
import org.springframework.cloud.stream.messaging.Sink;
import org.springframework.integration.annotation.MessageEndpoint;
import org.springframework.stereotype.Service;
import java.util.logging.Logger;
@Service
@EnableBinding(Sink.class)
@MessageEndpoint
public class StoreService {
Logger logger = java.util.logging.Logger.getLogger(StoreService.class.getName());
@StreamListener(Sink.INPUT)
public void logMessage(Order order) {
logger.info("Order processing: " + order);
}
}
Файл настроек application.properties
server.port=8054
spring.cloud.stream.bindings.input.destination=store
spring.cloud.stream.bindings.input.group=store
spring.cloud.stream.kafka.binder.auto-add-partitions=true
spring.cloud.stream.kafka.binder.min-partition-count=4
Запускаем Kafka
- скачать локально
- запустить через docker
В файл /etc/hosts добавить следующую строку (в консоли: gedit /etc/hosts)
127.0.0.1 kafka
В консоли:
docker network create kafka
docker run -d --net=kafka --name=zookeeper -e ZOOKEEPER_CLIENT_PORT=2181 confluentinc/cp-zookeeper:5.0.0
docker run -d --net=kafka --name=kafka -p 9092:9092 -e KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092 -e KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1 confluentinc/cp-kafka:5.0.0
Проверяем
docker images
Стартуем
docker start zookeeper
docker start kafka
Тестируем:
Запускаем store-service, затем bucket-service и затем order-service.
Видим как order-service каждые 5 секунд создает произвольный заказ и отсылает его в очередь.
Затем bucket-service ко всем заказам добавляет статус "checked" и отсылает дальше по цепочке измененный заказ.
И наконец store-service принимает уже измененный заказ и выводит в консоль.
И наконец для RabbitMQ все будет выглядеть аналогичным образом.
Спасибо за внимание!
Буду продолжать данную тему и в будущем разберу и опубликую работу протокола RSocket.
RSocket - это будущее для взаимодействия компонентов в реактивной микросервисной среде, когда очень важен перфоманс и отказоустойчивость.
Spring + RSocket
Что такое RSocket я рассказал в отдельной статье, т.к. мне кажется что это очень большая тема, на которую я вскоре напишу продолжение (я надеюсь).
build.gradle
plugins {
id 'org.springframework.boot' version '2.2.4.RELEASE'
id 'io.spring.dependency-management' version '1.0.9.RELEASE'
id 'java'
}
group = 'com.example'
version = '0.0.1-SNAPSHOT'
sourceCompatibility = '1.8'
configurations {
compileOnly {
extendsFrom annotationProcessor
}
}
repositories {
mavenCentral()
}
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-webflux'
implementation 'io.rsocket:rsocket-core:0.12.1'
implementation 'io.rsocket:rsocket-transport-netty:0.12.1'
compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
testImplementation 'io.projectreactor:reactor-test'
}
test {
useJUnitPlatform()
}
Server:
Configuration
@Configuration
public class RSocketConfig {
@PostConstruct
public void startServer() {
RSocketFactory.receive()
.acceptor((setupPayload, reactiveSocket) -> Mono.just(new RSocketService()))
.transport(TcpServerTransport.create(8000))
.start()
.block()
.onClose()
.block();
}
}
Сервис, который запускает некоторую логику
@Slf4j
@Component
public class RSocketService extends AbstractRSocket {
@Override
public Mono<Void> fireAndForget(Payload payload) {
System.out.println("fire-and-forget: server received");
return Mono.empty();
}
@Override
public Mono<Payload> requestResponse(Payload payload) {
log.info(payload.getDataUtf8());
return Mono.just(DefaultPayload.create("Connection successful"));
}
@Override
public Flux<Payload> requestStream(Payload payload) {
log.info(payload.getDataUtf8());
return Flux.range(1, 5)
.map(i -> DefaultPayload.create("request-stream: " + i));
// return Flux.just(
// DefaultPayload.create("request-stream-1"),
// DefaultPayload.create("request-stream-2"),
// DefaultPayload.create("request-stream-3"),
// DefaultPayload.create("request-stream-4"));
}
@Override
public Flux<Payload>requestChannel(Publisher<Payload>payloads) {
return Flux.from(payloads).map(Payload::getDataUtf8)
.doOnNext(str ->log.info("Received: " + str))
.map(DefaultPayload::create);
}
}
Client:
Configuration
@Configuration
public class RSocketConfig {
@Bean
public RSocket rSocket(){
return RSocketFactory.connect()
.transport(TcpClientTransport.create("localhost", 8000))
.start()
.block();
}
}
Controller
@Slf4j
@RestController
@RequestMapping("/api")
@RequiredArgsConstructor
public class RSocketController {
private final RSocket rSocket;
@GetMapping("/fire-and-forget")
public Mono<Void> fireAndForget() {
rSocket.fireAndForget(DefaultPayload.create("fire-and-forget!"))
.subscribe(System.out::println);
return Mono.empty();
}
@GetMapping("/request-response")
public Mono<Payload> getRequestResponse() {
return rSocket.requestResponse(DefaultPayload.create("request-response!"))
.doOnNext(System.out::println);
}
@GetMapping("/request-stream")
public Disposable getRequestStream() {
// return rSocket.requestStream(DefaultPayload.create("request-stream!"));
return rSocket.requestStream(DefaultPayload.create("request-stream!"))
.delayElements(Duration.ofMillis(1000))
.subscribe(
payload -> System.out.println(payload.getDataUtf8()),
e -> System.out.println("Error: " + e.toString()),
() -> System.out.println("Completed")
);
}
@GetMapping(value = "channel")
public Flux<String> getChannel() {
return rSocket.requestChannel(Flux.interval(Duration.ofSeconds(2)).map(l -> DefaultPayload.create("ping ")))
.map(Payload::getDataUtf8)
.doOnNext(string ->log.info("Received: " + string))
.take(20);
}
}
Давайте запустим сервер, а затем клиента и попробуем вызвать все конечные точки по очереди.
Перейдите по URL
localhost:8080/api/fire-and-forget
и сможете увидеть в консоли сообщение на сервере. Конечно же, на клиенте ничего нет.

Перейдите по URL
localhost:8080/api/request-response
и увидите сообщеньку "Connection successful". Ура!

На сервере

На клиенте

Мы отправили запрос и получили ответ.
Перейдите по URL
localhost:8080/api/request-stream
В модели request/stream подписчик отправляет запрос и издатель начнет отправлять ответ в неограниченном окличестве (но мы ограничились 5 элементами).
Сервер

Клиент

####Channel
Перейдите по URL
localhost:8080/api/channel
и в браузере в реальном времени мы увидим как сообщения приходят в течение 1 секунды (мы эмулировали эту ситуацию как канал связи между сервисами)

Клиент

Сервер

Модель channel обеспечивает двунаправленную связь: сообщения будут непрерывно передаваться от потребителя к издателю, а затем от издателя к потребителю.
А теперь давайте сделаем 2 простых приложения: client-service будет запрашивать данные у movie-service.
Movie-service:
application.properties файл
spring.rsocket.server.port=7000
spring.data.mongodb.uri=mongodb://localhost:27017/moviedb
Запускаем MongoDB в докере.
Если у вас установлен докер, давайте начнем (если не установлен, то обязательно сделайте это)
docker pull mongo
Докер скачает последнюю версию монг с docker-hub
Проверяем вот так
docker images
В результате мы увидим все текущие загруженные вами images (на данный момент у вас должно быть только один image, при условии, что вы ранее не использовали Docker)
Старт Mongo:
По умолчанию используется порт 27017
docker run mongo
или вы можете явно указать порт
docker run mongo --port 27017
Откройте новую консоль и там
mongo
Ну все, красавцы, теперь вы находитесь в оболочке Монго :)
Если вы используете Mac OS, вам нужно написать:
docker exec -it mongo bash
(or instead mongo you need to write container ID)
Затем напишите
mongo
При условии, что вы запустили movie-service (он настроен с MongoDB на порт 27017), вы можете написать в оболочке Mongo
use moviedb
где moviedb - это имя базы данных (см. файл application.properties)
Затем выполните в нем
show collections
и вы увидите объект movie (см. класс Movie)
Затем
db.moviedb.find()
И вы получите все данные (6 объектов), которые были созданы по умолчанию при запуске приложения.
Если вы хотите запустить второй Mongo на другом порту (вообще не проблема)
docker run mongo - port 27018
Откройте новую консоль, напишите
mongo
И снова красавцы, вы уже в другой монге :) Едем дальше.
Мы будем использовать базу данных MongoDB в контейнере Docker на порту 27017.
Основной класс будет иметь следующую форму (здесь мы запустим 6 фильмов в нашей базе данных при запуске приложения)
@SpringBootApplication
public class MovieServiceApplication {
public static void main(String[] args) {
SpringApplication.run(MovieServiceApplication.class, args);
}
// This code creates a Flux of four sample Persons objects, saves them to the DB. Then, queries all the Persons from the DB and print them to the console.
@Bean
CommandLineRunner run(MovieRepository movieRepository) {
return args -> {
movieRepository.deleteAll()
.thenMany(Flux.just(
new Movie("1", "Lion King", "130"),
new Movie("2", "Saw", "200"),
new Movie("3", "Home Alone", "150"),
new Movie("4", "Home Alone 2", "180"),
new Movie("5", "Interstellar", "300"),
new Movie("6", "Prometheus", "80")
)
.flatMap(movieRepository::save))
.thenMany(movieRepository.findAll())
.subscribe(System.out::println);
};
}
}
Репозиторий:
@Repository
public interface MovieRepository extends ReactiveMongoRepository<Movie, String> {
}
Вы также можете наследовать ReactiveMongoRepository.
Если вы посмотрите на интерфейс ReactiveMongoRepository, то увидите, что нам возвращаются объекты, заключенные в классы Mono и Flux. Это означает, что при обращении в базу данных мы не сразу получим результат. Вместо этого мы получаем поток данных Publisher, из которого можно получить данные, как только они будут готовы, или, скорее, он передаст их нам, как только они будут готовы.
Model:
@Data
@Builder
@AllArgsConstructor
@Document(collection = "movies")
public class Movie {
@Id
private String id;
private String name;
private String price;
}
и
public class RequestMovie {
private String name;
public RequestMovie() {
}
public RequestMovie(String name){
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
Controller:
@RestController
@RequestMapping("/")
public class MovieController {
private MovieRepository movieRepository;
public MovieController(MovieRepository movieRepository) {
this.movieRepository = movieRepository;
}
@MessageMapping("request-response")
Mono<Movie> getMovieByName(Movie movie) {
return movieRepository.findById(movie.getId());
}
@MessageMapping("request-stream")
Flux<Movie> getAllMovies() {
return movieRepository.findAll();
}
@MessageMapping("fire-forget")
Mono<Void> addMovie(Movie movie) {
movieRepository.save(movie);
return Mono.empty();
}
}
Наш сервер, связанный с Spring Boot, может просто настроить конечную точку с помощью аннотации @MessageMapping. Другими словами, нет необходимости наследовать и реализовывать класс AbstractRSocket. Однако тип возврата должен быть четко определен в соответствии с моделью связи RSocket!
Если вы используете метод Request-Response, аналогичный HTTP, данные ответа, которые должны быть доставлены, должны быть единым объектом! Т.е. тип возвращаемого значения должен быть Mono.
Если вы используете метод Request-Stream, данные ответа должны быть Flux, потому что данные ответа - это один или несколько потоковых данных!
request-response: Сервер использует аннотацию @MessageMapping для настройки конечной точки. Тип возврата был Mono. Клиент использует внедрение зависимостей через RSocketRequester.
request-stream: Поскольку вам необходимо передать более одного потока данных, вы должны использовать Flux.
fire-forget: Здесь сервер обрабатывает только запросы, полученные от клиентов, и не отвечает ни на какие данные. Так что здесь нам надо просто вернуть Mono.empty().
Client-service
Model - идентична серверу.
Сделаем конфиг для RSocket.
@Slf4j
@Configuration
public class RSocketConfiguration {
@Bean
RSocketRequester rSocketRequester(RSocketStrategies strategies) {
InetSocketAddress address = new InetSocketAddress("localhost", 7000);
return RSocketRequester.builder()
.rsocketFactory(factory -> factory
.dataMimeType(MimeTypeUtils.ALL_VALUE)
.frameDecoder(PayloadDecoder.ZERO_COPY))
.rsocketStrategies(strategies)
.connect(TcpClientTransport.create(address))
.retry()
.block();
}
}
Мы также можем зарегистрировать RSocketRequester здесь
@Bean
public Mono<RSocketRequester> rSocketRequester(Mono<RSocket> rSocket, RSocketStrategies strategies) {
return rSocket
.map(socket -> RSocketRequester.wrap(socket, MimeTypeUtils.parseMimeType("application/cbor"), strategies))
.cache();
}
но для простоты мы будем использовать его стандартную реализацию, предоставленную из коробки.
Bean-компонент RSocketRequester должен быть определен с использованием метода компоновщика или RSocketRequester.
Однако используемый метод зависит от версии загрузки Spring Boot. Метод RSocketRequester.create(), используемый в ранних версиях Spring Boot 2.2.0.M2, исчез :(
Controller:
@RestController
@RequiredArgsConstructor
@RequestMapping("/api")
public class ClientController {
private final RSocketRequester requester;
@GetMapping("/movie/{id}")
Mono<Movie> findMovieById(@PathVariable String id) {
return this.requester
.route("request-response")
// .data(DefaultPayload.create(""))
.data(new RequestMovie(id))
.retrieveMono(Movie.class);
}
@GetMapping("/showAllMovies")
Flux<Movie> findAllMovies() {
return this.requester
.route("request-stream")
.retrieveFlux(Movie.class);
}
@PostMapping("/addMovie/{id}/{name}/{price}")
Mono<Void> addMovie(@PathVariable String id,
@PathVariable String name,
@PathVariable String price) {
return this.requester
.route("fire-forget")
.data(new Movie(id, name, price))
.send();
}
}
findMovieById: Объявите маршрут, определенный @MessageMapping на сервере RSocket, в .route().
Если передается id фильма, выполняется поиск id фильма. Здесь клиент передает id фильма и возвращенные данные преобразуются в Mono с использованием метода retrieveMono().
showAllMovies: Клиенту должен получить данные во FLux.
addMovie: Метод send() возвращает Mono.
###WebSocket
Давайте на скорую руку сделаем простую приложеньку client-server с использованием WebSocket.
Клиент в 2 потока отправляет сообщеньки на сервер и сервер отвечает клиенту :) Красота!
Поехали.
Клиент:
application.yml
server:
port: 8081
И зафигачим все в одном классе для простоты (краткость - сестра таланта). Это шутка, за такое по рукам можно получить :)
@SpringBootApplication
@Slf4j
public class WebsocketClientApplication {
public static void main(String[] args) {
SpringApplication.run(WebsocketClientApplication.class, args);
}
@Value("${app.client.url:http://localhost:8080/ws/test}")
private String serverURI;
Mono<Void> wsConnectNetty() {
WebSocketClient client = new ReactorNettyWebSocketClient();
return client.execute(
URI.create(serverURI),
session -> session
.receive()
.map(WebSocketMessage::getPayloadAsText)
.take(8)
.doOnNext(number ->
log.info("Session id: " + session.getId() + " execute: " + number)
)
.flatMap(txt ->
session.send(
Mono.just(session.textMessage(txt))
)
)
.doOnSubscribe(subscriber ->
log.info("Session id: " + session.getId() + " open connection")
)
.doFinally(signalType -> {
session.close();
log.info("Session id: " + session.getId() + " close connection");
})
.then()
);
}
// для тестов
@Bean
ApplicationRunner appRunner() {
return args -> {
final CountDownLatch latch = new CountDownLatch(2);
Flux.merge(
Flux.range(0, 2)
.subscribeOn(Schedulers.single())
.map(n -> wsConnectNetty()
.doOnTerminate(latch::countDown))
.parallel()
)
.subscribe();
latch.await(20, TimeUnit.SECONDS);
};
}
}
ReactorNettyWebSocketClient - это реализация WebSocketClient для использования с Reactor Netty.
Здесь
URI.create(serverURI)
происходит подключение клиента к серверу WebSocket через URL-адрес: как только он подключается к серверу - устанавливает сеанс между ними.
Метод receive() получает поток входящих сообщений, которые впоследствии преобразуются в строки.
Сервер:
@Component
@Slf4j
public class MyWebSocketHandler {
@Bean
WebSocketHandlerAdapter webSocketHandlerAdapter() {
return new WebSocketHandlerAdapter();
}
WebSocketHandler webSocketHandler() {
return session ->
session.send(
Flux.interval(Duration.ofSeconds(1))
.map(Object::toString)
.map(session::textMessage)
).and(session.receive()
.map(WebSocketMessage::getPayloadAsText)
.doOnNext(msg -> log.info("Result: " + msg))
);
}
@Bean
HandlerMapping webSocketURLMapping() {
SimpleUrlHandlerMapping mapping = new SimpleUrlHandlerMapping();
mapping.setUrlMap(Collections.singletonMap("/ws/test", webSocketHandler()));
mapping.setCorsConfigurations(Collections.singletonMap("*", new CorsConfiguration().applyPermitDefaultValues())); // for CORS
mapping.setOrder(Ordered.HIGHEST_PRECEDENCE);
return mapping;
}
}
Здесь бин
webSocketHandlerAdapter()
для обработки "рукопожатия" через WebSocket, обновления и других деталей подключения.
Метод map "превращает" его в текстовое сообщение для отправки обратно клиенту.
Это приведет к потоку, который передается в качестве аргумента методу session.send(), который передается пользователю.
.map(Object::toString)
Это аналог
n -> n.toString()
Затем вызывается метод session.receive(), который возвращает поток сообщений веб-сокета.
Поток отображается через метод WebsocketMessage::getPayloadAsText, который дает нам сообщение полезной нагрузки.
Также здесь вы сможете найти другие примеры (например пользователь указывает свой адрес электронной почты и затем почта будет сохранена в БД и отображается на UI, реактивный сетевой чат, и простое взаимодействие клиент-сервера с помощью WebSocket) взаимодействия с WebSocket, как с помощью реактивного стиля так и нет. https://github.com/ksereda/WebSocket