This project aims to automatically translate and summarize Huggingface's daily papers into Korean using GPT-4o.
Thanks to @AK391 for great work.

Vote: 57
Authors: Kaixiong Gong, Tianshuo Peng, Yibing Wang, Zonghao Guo, Bohao Li, Benyou Wang, Kaituo Feng, Xiangyu Yue
- What's New: Video-R1은 멀티모달 대형 언어 모델(Multimodal Large Language Models; MLLMs)에서 비디오 추론 능력을 강화하기 위한 최초의 시도로, R1 패러다임을 체계적으로 탐구한 결과입니다. 기존의 강화 학습(Quantum Reinforcement Policy Optimization; GRPO)을 비디오 추론에 직접 적용하는 것의 한계를 극복하기 위해 T-GRPO 알고리즘을 제안하여 시계열 정보 활용을 촉진하고, 높은 품질의 비디오 추론 데이터 부족 문제에 대응하여 이미지 기반 추론 데이터를 활용했습니다.
- Technical Details: T-GRPO 알고리즘은 시계열 정보를 명시적으로 활용하도록 모델을 촉진합니다. 훈련 과정에서 시계열 순서와 무작위로 섞인 프레임 시퀀스를 각각 모델에 제시하여 두 집합의 응답을 생성하며, 정렬된 시퀀스에서의 정답 비율이 더 높은 경우에만 긍정적인 보상을 부여합니다. 데이터 부족 문제를 완화하기 위해 Video-R1은 이미지 및 비디오 추론 샘플을 포함한 두 가지 데이터셋, Video-R1-COT-165k와 Video-R1-260k를 구축했습니다.
- Performance Highlights: Video-R1-7B는 비디오 공간 추론 벤치마크인 VSI-Bench에서 35.8%의 정확도를 달성하여 독점 모델인 GPT-4o를 능가했습니다. 이는 강화 학습이 텍스트 도메인에서의 성과를 비디오 도메인에서도 이끌어낼 수 있음을 시사합니다. 6가지 비디오 벤치마크에서 일관되게 유의미한 개선을 보여주며, 특히 시계열 정보의 중요성을 입증했습니다.

Vote: 39
Authors: Zhengxi Lu, Guanjing Xiong, Yaxuan Guo, Liang Liu, Xi Yin, Yuxiang Chai, Hao Wang, Hongsheng Li
- What's New: 이 논문은 GUI 에이전트의 행동 예측을 강화 학습(신경망 강화 학습; RL)을 통해 향상시키는 새로운 접근 방식인 UI-R1를 소개합니다. 이 모델은 그래픽 사용자 인터페이스(GUI)의 행동 예측 작업을 위한 대규모 다중 모달 언어 모델(MLLMs)의 추론 능력을 강화하는 방법을 처음으로 탐구합니다.
- Technical Details: UI-R1 모델은 소수의 데이터셋을 사용하여 데이터 효율적인 학습을 실시하며, 정책 기반 알고리즘인 GRPO(Group Relative Policy Optimization)를 통해 최적화됩니다. 이 모델은 136개의 도전적인 작업에 대한 데이터셋을 사용하여, 모바일 장치에서 일반적으로 발견되는 다섯 가지 액션 타입을 포함합니다. 행동 유형 보상, 행동 인수 보상, 형식 보상으로 구성된 통합된 규칙 기반 보상 함수를 도입하여 모델 성능을 향상합니다.
- Performance Highlights: UI-R1-3B 모델은 인도메인 (ID) BENCHMARK ANDROIDCONTROL에서 행동 유형 정확도가 15% 개선되었으며, 기초 모델(Qwen2.5-VL-3B)과 비교했을 때 기초 정확도가 10.3% 증가했습니다. 또한, OOD GUI 바인딩 벤치마크 ScreenSpot-Pro에서 6.0% 향상된 성능을 보여, 76K 데이터로 학습된 대형 모델과 유사한 성과를 나타냈습니다. 이는 규칙 기반 강화 학습이 GUI에 대한 이해와 제어를 발전시키는 잠재력을 입증합니다.

Vote: 30
Authors: Zhongyuan Wang, Yingqian Min, Lei Fang, Haoxiang Sun, Wayne Xin Zhao, Zhipeng Chen, Ji-Rong Wen, Zheng Liu
- What's New: OlymMATH는 대형 언어 모델(Large Language Models; LLMs)의 수리적 추론 능력을 평가하기 위해 새롭게 설계된 올림피아드 수준의 수학 벤치마크입니다. 200개의 문제로 구성된 이 벤치마크는 수학적 추론 분야에 대한 더욱 도전적이고 엄격한 평가를 목표로 하고 있으며, 영어와 중국어 모두에서 문제를 제공하여 다국어 평가를 지원합니다.
- Technical Details: OlymMATH 벤치마크는 두 개의 기본 난이도 레벨 (AIME-level, Hard)로 나뉘어 있으며, 각 문제는 네 가지 주요 수학 분야(대수학, 기하학, 수론, 조합론)에 걸쳐 있습니다. 모든 문제는 신중하게 인쇄 출판물에서 수집되어 데이터 오염을 최소화합니다. 평가 방식은 MATH 데이터셋과 일관성을 유지하며, 간단한 답변 형식을 통해 모델의 수학적 추론 능력을 검사합니다.
- Performance Highlights: OlymMATH에서 DeepSeek-R1 및 OpenAI의 o3-mini 모델과 같은 최첨단 추론 모델은 OlymMATH-EN-HARD 부분에서 각각 21.2%와 30.3%의 정확도를 기록하며, 이는 현존하는 LLMs가 올림피아드 수준의 수학 문제를 푸는 데 여전히 큰 도전이 있음을 드러냅니다. 실험 결과는 언어가 수리적 추론 성능에 영향을 미칠 수 있음을 시사하며, 영어 기반의 문제에서 대체로 높은 성능을 기록했습니다.
Vote: 25
Authors: Kai Zou, Fan Zhang, Jingwen He, Dian Zheng, Wei-Shi Zheng, Yu Qiao, Ziqi Huang, Hongbo Liu, Yuanhan Zhang, Ziwei Liu, Yinan He
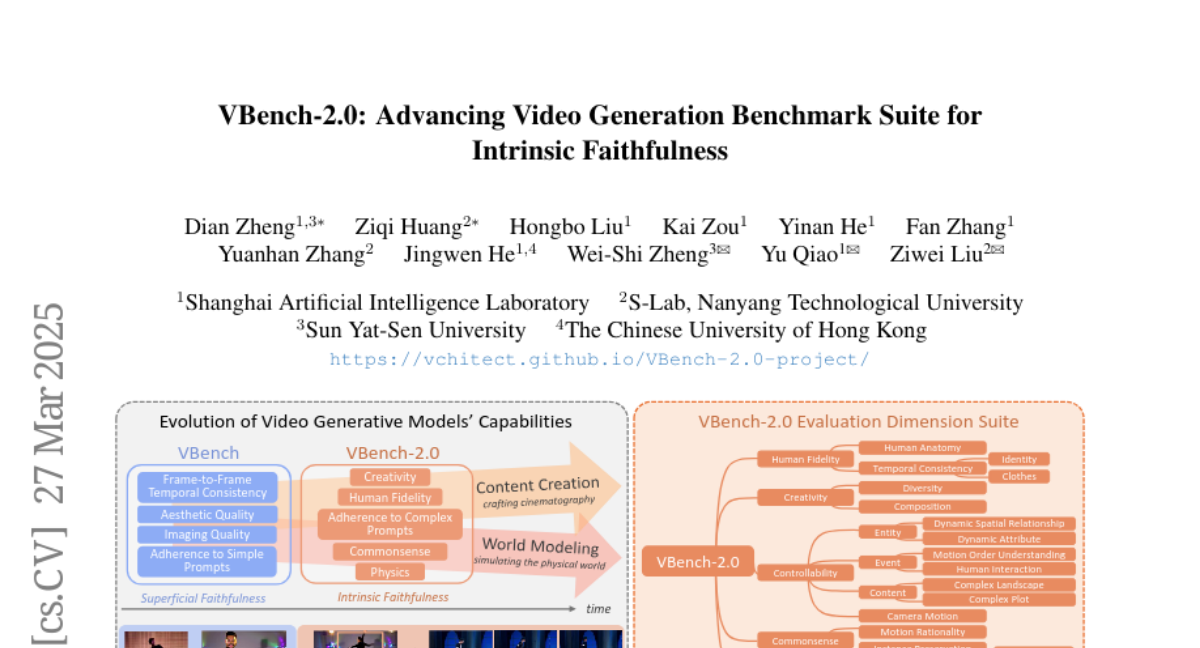
- What's New: VBench-2.0는 비디오 생성 모델의 본질적 충실성을 평가하기 위한 차세대 벤치마크로 도입되었습니다. 기존의 VBench가 슈퍼피셜 충실성에 중점을 두었던 반면, VBench-2.0는 물리 법칙, 상식적 추론, 해부학적 정확성을 포함한 더 깊은 원칙을 준수하는 비디오 생성 모델의 평가를 목표로 합니다.
- Technical Details: VBench-2.0는 인간 충실성(Human Fidelity), 제어 가능성(Controllability), 창의성(Creativity), 물리학(Physics), 상식(Commonsense)의 다섯 가지 주요 차원에서 비디오 생성 모델을 평가합니다. 각 차원은 추가적인 세부 능력으로 나누어져 있으며, 평가의 강건성을 높이기 위해 VLM과 LLM 등 일반 분석 모델을 활용하고, 비디오 생성에 맞춰 제안된 이상 탐지 기법을 통합합니다.
- Performance Highlights: 최신 상태의 비디오 생성 모델인 HunyuanVideo, CogVideoX-1.5, Sora-480p 등에서 VBench-2.0 차원별 평가를 수행한 결과, 일부 모델이 창의성이나 인간 해부학 충실성에서 뛰어난 수준을 보였으나 복잡한 플롯 생성, 단순한 동적 속성 처리, 상식적 추론에서 약점을 노출하였습니다. 이는 향후 연구의 중요한 방향을 시사합니다.

Vote: 22
Authors: Wei Ju, Zhiping Xiao, Yifan Wang, Shichang Zhang, Yiqiao Jin, Ziyue Qiao, Meng Xiao, Qingqing Long, Hanqing Zhao, Xiao Luo, Ye Yuan, Yusheng Zhao, Xian Wu, Jingyang Yuan, Weizhi Zhang, Fan Zhang, Junwei Yang, Philip S. Yu, Ming Zhang, Rongcheng Tu, Dacheng Tao, Binqi Chen, Bohan Wu, Junyu Luo, Yiyang Gu, Chenwu Liu
- What's New: 이 논문은 대형 언어 모델(Large Language Models; LLMs) 에이전트의 방법론, 응용 및 도전에 대한 포괄적인 조사를 제공합니다. LLM 에이전트는 지능형 에이전트 시스템 내에서 역할 정의, 메모리 메커니즘, 계획 역량, 평가 방법론 등을 통합하여 새로운 접근을 시도합니다.
- Technical Details: 이 논문에서는 에이전트 시스템의 구조적 컴포넌트를 '구성', '협력', '진화'의 세 가지 차원으로 분류합니다. 각 차원은 LLM 에이전트의 정의, 협업 메커니즘 및 발전 경로를 다루며, 상호 연결된 시스템으로서의 LLM 에이전트에 대한 통합된 탁시노미를 제공합니다.
- Performance Highlights: 논문에서는 LLM 에이전트가 광범위한 분야에서 다양한 역할을 수행하며 지능적이고 협력적인 문제 해결 능력을 향상시킬 수 있음을 보여줍니다. 그러나 현재 기술에는 확장성, 신뢰성, 평가 기준 등의 도전과제가 남아 있습니다.

Vote: 19
Authors: Bo Zhang, Shitian Zhao, Qi Qin, Zhen Li, Peng Gao, Yu Qiao, Qilong Wu, Kaipeng Zhang, Dongyang Liu, Ming Li, Xinyue Li, Hongsheng Li, Bin Fu
- What's New: LeX-Art는 고품질 텍스트-이미지 합성을 위한 포괄적인 프레임워크로, 텍스트 생성의 표현력과 렌더링 충실도 사이의 격차를 체계적으로 메우는 것을 목표로 합니다. LeX-10K라는 10,000개의 고해상도 이미지 데이터셋을 구축하여 텍스트 속성과 복잡한 레이아웃을 제어할 수 있습니다.
- Technical Details: LeX-Art는 데이터 중심의 접근 방식을 채택하여 DeepSeek-R1 기반 고품질 데이터 합성 파이프라인을 설계하였습니다. 또한 LeX-Enhancer라는 강력한 프롬프트 강화 모델을 개발하고, LeX-FLUX와 LeX-Lumina라는 두 가지 텍스트-이미지 모델을 훈련하여 텍스트 렌더링 성능을 극대화했습니다. 평가를 위해 LeX-Bench라는 벤치마크를 도입했습니다.
- Performance Highlights: 실험에서는 LeX-Lumina가 CreateBench에서 79.81%의 PNED 향상을, LeX-FLUX가 색상, 위치, 글꼴 정확도에서 각각 +3.18%, +4.45%, +3.81%로 기본 모델을 능가하는 성과를 보여줬습니다.
ReaRAG: Knowledge-guided Reasoning Enhances Factuality of Large Reasoning Models with Iterative Retrieval Augmented Generation

Vote: 16
Authors: Lei Hou, Jiajie Zhang, Zhicheng Lee, Shulin Cao, Xiaoyin Che, Jinxin Liu, Weichuan Liu, Juanzi Li
- What's New: ReaRAG는 대규모 추론 모델(Large Reasoning Models; LRMs)의 사실성을 향상시키기 위한 모델로, 반복 검색 증강 생성(Retrieval-Augmented Generation; RAG)을 통해 지식 기반의 추론 체인을 생성하여, 과도한 반복 없이 다양한 쿼리를 탐색할 수 있도록 합니다.
- Technical Details: ReaRAG는 지정된 최대 추론 체인 길이를 갖춘 새로운 데이터 생성 프레임워크와 사고-행동-관찰(Thought-Action-Observation) 패러다임을 사용하여, 반사적 추론(reflective reasoning)을 도입했습니다. 추론 체인은 사고, 행동, 관찰의 단계로 구성되며, 모델은 외부 지식을 활용하여 추론 궤적을 인식하고 재조정합니다.
- Performance Highlights: ReaRAG는 MuSiQue, HotpotQA, IIRC와 같은 여러 멀티홉 QA 벤치마크에서 기존의 방법들보다 유의미한 성능 향상을 나타냈습니다. MuSiQue에서는 14.5%의 ACCL 지표 개선을 보였고, HotpotQA에서는 6.5%의 ACCL 지표 향상을 기록했습니다. 이는 ReaRAG가 멀티홉 추론에서 특히 강한 능력을 보여주는 결과입니다.

Vote: 15
Authors: Shashidhar Reddy Javaji, Meikang Qiu, Yangyang Yu, Xiao-yang Liu, Yueru He, Koduvayur Subbalakshmi, Sophia Ananiadou, Zining Zhu, Qianqian Xie, Jian-Yun Nie, Haohang Li, Yupeng Cao, Jimin Huang
- What's New: FINAUDIO는 금융 도메인에서의 오디오 대형 언어 모델(Audio Large Language Models; AudioLLMs)을 평가하기 위한 최초의 벤치마크입니다. 이는 금융 분석과 투자 결정에 중요한 수익 발표 회의와 CEO 연설 등의 오디오 데이터를 다룹니다. 세 가지 주요 작업을 정의하여 금융 오디오에서의 AudioLLMs의 능력을 평가합니다: 1) 짧은 금융 오디오에서 자동 음성 인식(ASR), 2) 긴 금융 오디오에서의 ASR, 3) 긴 금융 오디오의 요약 작업입니다.
- Technical Details: FINAUDIO 벤치마크는 짧은 오디오 클립과 긴 오디오 녹음을 포함한 5개의 데이터셋으로 구성되어 있으며, 총 400시간 이상의 금융 오디오 데이터를 다룹니다. 7개의 대표적 AudioLLMs를 평가하여 금융 도메인에서의 한계점을 도출하고 개선 방향성을 제시합니다. 특히, 이 벤치마크를 위해 FinAudioSum이라는 새로운 요약 데이터셋을 개발하였습니다.
- Performance Highlights: 평가 결과, Whisper-v3는 모든 ASR 데이터셋에서 가장 낮은 오류율(WER)을 기록하였으며, Gemini 모델도 상대적으로 우수한 성능을 보였습니다. SALMONN 모델은 전반적으로 높은 오류율을 나타내어 성능이 떨어졌습니다. 요약 작업에서는 Gemini-1.5-flash 모델이 가장 높은 ROUGE-L 및 BERTScore를 기록했으나, 전반적인 요약 품질은 ASR 성능에 의존적입니다. 띄어쓰기 오류나 금융 전문 용어의 오타가 여전히 과제로 남아 있습니다.

Vote: 15
Authors: Jinjie Ni, Yujie Liu, Yuqiang Li, Dongzhan Zhou, Wanli Ouyang, Erik Cambria, Shixiang Tang, Tong Xie, Ben Gao, Zonglin Yang
- What's New: ResearchBench는 LLMs (Large Language Models)의 과학적 발견 능력을 평가하기 위한 대규모 벤치마크로, 영감 획득(inspiration retrieval), 가설 작성(hypothesis composition), 그리고 가설 순위 결정(hypothesis ranking)의 세 가지 핵심 작업에 초점을 맞추고 있습니다. 과학 논문으로부터 연구 질문(research questions), 배경 조사(background surveys), 영감(inspirations), 가설(hypotheses)을 추출하는 자동화된 프레임워크를 개발하였으며, 데이터 오염을 방지하기 위해 2024년 발표된 논문만을 사용했습니다.
- Technical Details: ResearchBench는 12개 학문 분야의 논문에서 영감을 추출하기 위한 자동화된 에이전트 프레임워크(agentic framework)를 기반으로 하고 있으며, 물리, 화학, 천문학, 재료 과학 분야의 전문가 5명을 초청하여 검증을 받았습니다. LLM의 훈련 데이터 오염을 방지하기 위해 2024년 발표된 논문을 선택했으며, 이는 최신 논문을 지속적으로 반영하여 데이터 중복을 피할 수 있도록 설계되었습니다.
- Performance Highlights: LLMs는 영감 획득, 가설 작성 및 가설 순위 결정 작업에서 고성능을 보였으며, 특히 새로운 지식 연관성을 효과적으로 찾아내는 능력을 보여주었습니다. 영감 획득 작업에서 GPT-4o는 첫 번째 라운드에서 80% 이상의 정확도를 기록했으며, 최종 라운드에서는 45% 이상의 정확도를 유지했습니다. 이 실험은 LLMs가 현재 과학적 발견을 위한 '연구 가설 광산(research hypothesis mines)'으로 활용될 수 있다는 가능성을 제시하며, 이는 자율적인 과학적 발견을 촉진하는 데 기여할 수 있습니다.

Vote: 14
Authors: Wenqi Zhang, Yongliang Shen, Hang Zhang, Weiming Lu, Guiyang Hou, Xu Huixin, Mengna Wang, Xin Li, Yueting Zhuang, Zhe Zheng, Peng Li, Gangao Liu, Yiwei Jiang
- What's New: Embodied-Reasoner는 최신 심층 사고 모델을 확장하여 체화 상호작용 검색 작업에 적용하는 혁신적인 접근법을 제시합니다. 기존의 수학적 추론이 주로 논리적 귀결에 의존하는 반면, 체화 시나리오는 공간적 이해, 시간적 추론, 상호작용 이력에 기초한 지속적인 자기 성찰을 요구합니다.
- Technical Details: Embodied-Reasoner는 6만 4천개의 상호작용 이미지를 포함하는 일관된 관찰-사고-행동 경로를 9.3k개 생성하여 다양한 사고 프로세스를 학습합니다. 체화 모델을 위한 데이터 엔진을 개발하여 다섯 가지 사고 패턴(상황 분석, 과제 계획, 공간적 추론, 자기 성찰, 검증)을 생성하며, 3단계 학습 파이프라인(모방 학습, 거절 샘플링을 통한 탐색, 반영 튜닝을 통한 자기 수정)을 적용합니다.
- Performance Highlights: 본 모델은 AI2-THOR 시뮬레이터에서 OpenAI o1, o3-mini, Claude-3.7-Sonnet-thinking보다 각각 성공률에서 +9%, 탐색 효율에서 +12%를 초과합니다. 특히 복잡한 복합 작업에서 성공률이 두 번째 모델보다 39.9% 더 높습니다. 이러한 실험 결과는 체화된 상호작용 시나리오에서의 강력한 추론 능력을 입증합니다.

Vote: 12
Authors: Sheng Xu, Chaonan Ji, Liefeng Bo, Peng Zhang, Jinwei Qi, Bang Zhang
- What's New: ChatAnyone는 하이어라키컬 모션 디퓨전 모델(Hierarchical Motion Diffusion Model)을 통해 실시간으로 스타일화된 초상화 비디오를 생성하는 혁신적인 프레임워크를 제안합니다. 이는 얼굴에서 상반신까지의 다양한 표정과 스타일 조절이 가능한 인터랙티브한 비디오 채팅을 실현합니다.
- Technical Details: ChatAnyone의 프레임워크는 두 단계로 구성됩니다. 첫 번째 단계는 오디오 입력을 기반으로 하여 명시적(explicit) 및 암묵적(implicit) 모션 표현을 고려하는 효율적인 하이어라키컬 모션 디퓨전 모델을 사용합니다. 이를 통해 머리와 몸의 동작을 동기화하여 다양한 얼굴 표정을 생성합니다. 두 번째 단계에서는 손 동작을 포함한 상반신 초상화 비디오를 생성합니다. 얼굴 및 상반신 모션을 명시적 랜드마크와 암묵적 옵셋을 결합하여 풍부하고 현실적인 영상을 제작합니다. 최대 512×768 해상도에서 30fps로 실시간 인터랙티브 비디오 채팅을 지원합니다.
- Performance Highlights: 제안된 방법은 풍부한 표정 표현과 자연스러운 상반신 움직임을 갖춘 초상화 비디오를 생성하는 능력을 실험적으로 입증했습니다. 이는 디지털 인간 상호작용에서 몰입감 있고 생생한 체험을 제공할 수 있으며, 실시간 비디오 채팅에서 4090 GPU를 사용하여 30fps의 효율적인 추론 속도를 달성하면서 높은 성능과 효율성을 강조합니다.

Vote: 12
Authors: Chang Xu, Bo Zhang, Qi Qin, Xiangyang Zhu, Ruoyi Du, Bin Fu, Wenhai Wang, Xiaohong Liu, Conghui He, Xinyue Li, Manyuan Zhang, Hongsheng Li, Victor Perez, Erwann Millon, Peng Gao, Dongyang Liu, Yu Qiao, Le Zhuo, Will Beddow, Zhen Li, Jiakang Yuan, Yiting Lu, Yi Xin
- What's New: Lumina-Image 2.0는 Lumina-Next 대비 높은 성능을 달성한 최신 텍스트-이미지 생성(Generative) 모델입니다. 이 모델은 통합 아키텍처(Unified Architecture)를 채택하여, 텍스트와 이미지 토큰을 공동 시퀀스로 처리하고 자연스러운 크로스 모달 상호작용을 가능하게 합니다. 또한, 고품질 캡션을 제공하는 통합 캡셔너(Unified Captioner; UniCap)를 도입하여 빠른 수렴 속도를 달성하고 프롬프트 준수성을 강화했습니다.
- Technical Details: Lumina-Image 2.0은 통합 Next-DiT 모델을 통해 이미지와 텍스트 토큰을 완전한 엔드-투-엔드 방식으로 처리합니다. 또한, 다중 단계의 점진적 훈련 전략을 개발하여 효율성을 높였습니다. 이 모델은 공공의 벤치마크와 텍스트-이미지 아레나에서 높은 성능을 보여주며, 성능 향상을 위해 UniCap을 사용하여 고품질 텍스트-이미지 쌍을 생성합니다. 최적화 과정에서는 삼단계의 진보적 훈련을 통해 고해상도 이미지를 생성하는 데 초점을 맞췄습니다.
- Performance Highlights: Lumina-Image 2.0은 2.6B 파라미터로 GenEval, DPG와 같은 벤치마크에서 높은 성능을 보였다. DPG 기준 성능이 87.2에 도달했으며 다양한 온라인 테스트에서도 GPT-4와 비교할 만한 뛰어난 성과를 보였습니다. 각종 최적화 기법을 통해 효율성을 제고하였습니다.

Vote: 10
Authors: Han Hu, Shuyang Gu, Jianning Pei
- What's New: 이 논문은 확산 모델(Diffusion Models)의 샘플링 효율성을 높이기 위한 최적의 단계 크기(Optimal Stepsize)를 찾아내는 새로운 방법을 제안합니다. 기존의 단계 크기 조정 방법이 경험적이거나 이론적 보장이 부족했던 반면, 이 논문은 동적 프로그래밍 프레임워크를 통해 이론적으로 최적의 스케줄을 추출하는 방식을 도입합니다.
- Technical Details: 제안된 방법은 단계 크기 최적화를 동적 프로그래밍 문제로 재구성하여 전역 오류를 최소화합니다. 이 방식은 다양한 모델 아키텍처와 ODE 솔버, 노이즈 스케줄에서도 일관된 성능을 보이며, 텍스트-이미지 및 텍스트-비디오 확산 파이프라인에 10배 가속도를 제공하면서도 성능을 99.4% 유지합니다.
- Performance Highlights: GenEval 벤치마크에서 제안된 방법을 사용하여 텍스트-이미지 생성은 거의 성능 저하 없이 10배의 가속도를 달성하였습니다. 또한, 다양한 노이즈 스케줄과 솔버에서 2.65 PSNR의 평균적인 향상을 보였습니다.

Vote: 9
Authors: Fengqi Dai, Donglin Wang, Nong Sang, Siteng Huang, Pengxiang Ding, Zhengrong Zuo, Minghui Lin, Cunxiang Wang, Xiang Wang, Shu Wang, Yishan Wang
- What's New: 이 논문은 물리 인지(Physics Cognition)를 비디오 생성에 적용한 최신 연구를 정리하고, 연구 흐름을 '기본적인 스키마 지각', '물리적 지식의 수동적 인지', '세계 시뮬레이션을 위한 능동적 인지' 세 가지 범주로 정리해 제시합니다. 이는 특히 강력한 비디오 생성 모델이 시각적 사실성 뿐만 아니라 물리적 정확성을 어떻게 구현할 수 있는지에 대한 지도적 틀을 제공하고자 합니다.
- Technical Details: 본 설문에서 다루는 주요 기술은 기본 스키마 지갈(Basic Schematic Perception), 물리적 지식의 수동적 인지(Passive Cognition), 물리 시뮬레이션을 활용한 생성(Physics Simulation-based Generation)으로 나뉩니다. 특히 물리 시뮬레이션 기반 생성은 물리 엔진과 물리 시뮬레이터를 결합해 도달 가능한 정밀한 상호작용 시나리오를 다루며, MPM(Material Point Method)과 같은 grid 기반의 라그랑주-오일러 방법 등이 사용됩니다. 마지막으로 LLMs(Large Language Models)를 활용한 물리 시뮬레이션이 각광받고 있어 복잡한 물리적 정보와 자료 기반의 사전 없이도 의미있는 생성이 가능해졌습니다.
- Performance Highlights: 현재의 비디오 생성 모델은 인상적인 시각적 사실성을 구현하나, '물리적 말도 안됨(Physical Absurdity)' 문제로 인해, 뉴턴 역학, 모멘텀 보존 법칙 등 기본 물리 법칙을 자주 위반합니다. 예를 들어, 몇몇 최첨단 영상 생성 모델들은 여전히 티 타임랩스에서 아이스크림이 온도가 상승하며 변형되는 과정을 다루는 데에 어려움을 겪고 있습니다. 이 같은 모순은 비디오 생성 모델의 물리 인지 모델링 능력에 본질적인 한계를 드러내며, 이는 향후 연구 발전에 중요한 방향성을 제공합니다.

Vote: 6
Authors: Ningyu Zhang, Haoming Xu, Huajun Chen, Ziyan Jiang, Ningyuan Zhao, Yi Zhong, Shuxun Wang, Yanqiu Zhao, Shumin Deng
- What's New: ZJUKLAB 팀은 SemEval-2025 Task 4에서 민감한 콘텐츠를 언러닝 (Unlearning)하는 방법으로 모델 병합 (Model Merging), 특히 TIES-Merging을 활용하여 민감한 정보의 과도 혹은 불완전한 제거 문제를 해결하는 시스템을 제안했습니다. 이 시스템은 26개 팀 중 2위에 오르며 Task Aggregate 점수에서 0.944, 전반적인 Aggregate에서 0.487을 기록했습니다.
- Technical Details: ZJUKLAB의 언러닝 시스템은 두 단계로 구성되어 있습니다. 첫 번째는 훈련 단계로, 낮은 랭크 적응 (Low-Rank Adaptation; LoRA) 기반으로 두 가지 상반된 하이퍼파라미터 조합을 훈련하여 각각 과도한 제거와 불완전한 제거 특성을 가지는 별도의 모델을 만듭니다. 두 번째는 병합 단계로, TIES-Merging을 통해 이 두 모델을 조합하여 균형 잡힌 제거를 달성합니다. 이를 위해 Negative Preference Optimization (NPO), Gradient Descent on Retain Set (GDR), Kullback-Leibler Divergence Minimization on Retain Set (KLR)을 사용하여 적절한 관련 데이터를 최적화합니다.
- Performance Highlights: ZJUKLAB 팀의 7B 모델은 온라인 평가에서 0.487의 Aggregate 점수를 기록하며 26개 팀 중 2위에 올랐으며, 로컬 평가에서는 거의 완벽한 결과를 나타내어 MIA 점수에서 0.501을, Aggregate 점수에서 0.806을 기록했습니다. 이러한 성과는 두 모델의 강점을 적절히 결합하여 민감 정보를 효과적으로 제거할 수 있음을 보여줍니다.

Vote: 6
Authors: Bohan Wang, Feng Cheng, Qi Zhao, Ziyan Yang, Lu Jiang, Xingyu Ni, Ziyu Wang
- What's New: 이 논문은 합성 비디오(Synthetic Video)를 사용하여 영상 생성 모델의 물리적 충실도(Physical Fidelity)를 향상시키는 방법을 탐구한 첫 번째 연구 중 하나입니다. 합성 데이터의 물리적 특성이 모델에 전달되어 언제 의도치 않은 아티팩트(Artifacts)를 줄이는 방법도 도입했습니다.
- Technical Details: 연구진은 합성 데이터를 큐레이션하고 통합하여 물리적 현실감을 모델에 전달하는 방법을 제안합니다. 모델 수준에서는 SimDrop 방법을 제안하여 합성 데이터로 훈련된 모델이 불필요한 렌더링 아티팩트를 제거하도록 지원합니다. 또한 3D 일관성 및 인간 자세 무결성을 평가기준으로 사용하여 모델의 물리적 충실도를 점검합니다.
- Performance Highlights: 모델 실험 결과, 대형 카메라 움직임에 따른 3D 일관성이 개선되었고, 영상 생성 모델에서 사람이나 동물과 같은 객체가 배경과 선명하게 분리된 레이어를 생성할 수 있음을 보여주었습니다. 본 연구의 접근 방식은 현재의 영상 생성 모델에서 발견되는 물리적인 부족함을 보완할 수 있는 가능성을 제시했습니다.

Vote: 5
Authors: Achuta Kadambi, Suya You, Zhiwen Fan, Zhangyang Wang, Yijia Weng, Zhen Wang, Shijie Zhou, Hui Ren, Leonidas Guibas, Dejia Xu, Shuwang Zhang
- What's New: Feature4X는 다양한 가우시안 기능 필드(Gaussian Feature Fields)를 활용하여 단일 단안 비디오(monocular video)를 4D AI 시스템으로 확장할 수 있는 프레임워크입니다. 이 시스템은 사용자가 생성한 콘텐츠에서 2D 비전 모델의 기능을 4D로 확장하여 시각적 질문 응답(VQA), 장면 편집 등을 가능하게 합니다.
- Technical Details: 핵심적인 기술은 동적인 최적화 전략을 통해 여러 모델을 단일 표현 방식으로 통합하며, 가우시안 스플래팅(Gaussian Splatting)을 사용해 단안 비디오 모델의 기능을 명시적 4D 기능 필드로 증류 및 확장합니다. 이는 시공간적으로 인식할 수 있는 대화형 4D 장면을 가능하게 합니다.
- Performance Highlights: Feature4X는 학습 데이터 주석과 학습 오버헤드를 최소화하여 여러 다운스트림 작업에 사용할 수 있는 효율적이고 확장 가능한 4D 기능 필드를 제공합니다. 또한, GPT-4o 기반 에이전트를 통합하여 자연어 상호작용과 자율적 작업 조정이 가능하며, 4D 장면에 대한 동적 상호작용을 지원합니다.

Vote: 4
Authors: Subarna Saha, Alif Al Hasan, Tarannum Shaila Zaman, Mia Mohammad Imran
- What's New: LLPut는 버그 보고서(Bug Report)에서 실패 유발 입력(failure-inducing inputs)을 생성하기 위한 자동화된 추출 기술로서, 대형 언어 모델(Large Language Models; LLMs)의 성능을 평가하는 새로운 접근법을 제안합니다. 이 연구는 LLaMA, Qwen, Qwen-Coder 등의 공개 소스 생성형 LLM을 버그 보고서에서 관련 입력을 추출하는 데 얼마나 효과적인지를 분석한 최초의 체계적인 평가입니다.
- Technical Details: LLPut 방법론은 데이터셋 준비와 다양한 LLM 적용 두 가지 주요 구성 요소로 구성됩니다. 먼저 버그 보고서를 수집하고 주석을 다는 것으로 시작하여 LLaMA, Qwen, Qwen-Coder 모델을 적용해 성능을 평가합니다. 평가 지표로는 BLEU 스코어(Bilingual Evaluation Understudy)를 사용하여 NLP 기반 BERT 모델과 비교하여 LLM이 추출한 입력 명령어의 정확성을 평가했습니다.
- Performance Highlights: 실험 결과에서 Qwen 모델은 BLEU-2 점수 기준 62.62%가 0.5 이상으로 가장 높은 정확성을 기록했습니다. BERT 모델은 상대적으로 저조한 성능을 보였으며, LLaMA와 Qwen-Coder는 Qwen과 비슷한 수준의 성능을 보였습니다. 특히, Qwen은 인간 주석자와의 정확한 일치가 가장 많은 81개의 사례를 보였습니다.

Vote: 3
Authors: Alexander Swerdlow, Katerina Fragkiadaki, Siddharth Gandhi, Deepak Pathak, Mihir Prabhudesai
- What's New: UniDisc는 텍스트와 이미지 도메인 모두에서 연속적 기법의 한계를 극복하고자 하는 새로운 통합 멀티모달 생성 모델로, 임의의 텍스트 및 이미지 생성을 가능하게 합니다. 이 연구는 연속적 잡음 보다는 이산적 잡음을 사용하여 연속적 디퓨전(continuous diffusion) 모델의 한계를 개선합니다.
- Technical Details: UniDisc 모델은 이산적 디퓨전(discrete diffusion) 기법을 사용해 텍스트 및 이미지에 대해 공동 토크나이징을 수행하며, Clasifier-Free Guidance(CFG)를 통해 품질과 다양성 사이에 균형을 도모합니다. 학습은 1.4B 파라미터 대형 모델로, 웹 규모의 데이터셋을 활용하여 두 단계의 전처리(pre-training)와 고화질 미세 조정(fine-tuning)을 통해 진행됩니다.
- Performance Highlights: UniDisc는 다양한 멀티모달 생성 및 검색 작업에서 기존의 AR 모델보다 뛰어난 성능을 보여주었으며, 특히 조건적 생성에서는 더 높은 FID 및 CLIP 점수를 기록하였습니다. 또한 UniDisc는 결합된 이미지-텍스트 문맥에서 인페인팅(inpainting) 능력을 보여, 유사한 잠재 모델을 초월하는 기능을 입증합니다.

Vote: 3
Authors: Pier Luigi Dovesi, Linus Härenstam-Nielsen, Marc Botet Colomer, Gianluca Villani, Jussi Karlgren, Daniel Cremers, Federico Tombari, Reza Qorbani, Theodoros Panagiotakopoulos, Matteo Poggi, Mattia Segu
- What's New: 논문에서는 라벨링되지 않은 클래스를 텍스트 쿼리를 통해 픽셀을 분류하는 개방형 어휘 시맨틱 세분화 모델에서 도메인 시프트를 효과적으로 극복할 수 있는 새로운 트레이닝 없는 적응 프레임워크인 Semantic Library Adaptation (SemLA)을 소개합니다. SemLA는 CLIP 임베딩으로 인덱싱된 LoRA 기반 어댑터 라이브러리를 사용하여 테스트 중 필요한 어댑터를 동적으로 결합하여 모델을 즉시 도메인에 맞게 조정합니다.
- Technical Details: SemLA는 CAT-Seg 아키텍처를 기반으로 하며, 이 아키텍처에 Low-Rank Adaptation (LoRA)을 통합하여 각 선형 레이어에 학습 가능한 저계급 행렬을 추가하여 원래의 가중치를 변경하지 않고 도메인 특정 튜닝을 가능하게 합니다. 로라 어댑터는 도메인 혼합 단계에서 선택 및 결합되며, 이는 각 테스트 이미지에 대해 독립적으로 수행됩니다. 결합된 어댑터는 여러 도메인의 지식을 통합하고, 이는 테스트 이미지와의 관련성에 따라 가중됩니다.
- Performance Highlights: 20개의 도메인 벤치마크 실험 결과, SemLA는 제로샷과 단순 어댑터 결합 방식에 비해 뛰어난 적응성과 성능을 보여주었습니다. 특정 상황에서 SemLA는 단일 어댑터 성능을 넘어서기도 했으며, 특히 ACDC 안개 및 야간 데이터셋에서 두드러졌습니다. 이는 LoRA 시너지가 개별 어댑터를 넘어서는 경우를 나타냅니다.

Vote: 1
Authors: Meet Soni, Sirisha Rambhatla, Achint Soni
- What's New: LOCATEdit는 그래프 라플라시안 최적화를 사용하여 지역화된 텍스트 기반 이미지 편집(Text-Guided Image Editing)을 위한 크로스 어텐션(Cross Attention) 맵을 개선하는 혁신적인 접근 방식을 제안합니다. 이를 통해 기존 기법들이 가진 공간적 일관성 부족 문제를 해결하고, 구조적 손실 없이 지정된 항목에 대한 수정만을 허용합니다.
- Technical Details: LOCATEdit는 CASA 그래프를 도입하여 이미지 패치를 노드로, 패치 간 관계를 가중치로 표현하여 크로스 및 셀프 어텐션(Self-Attention) 관계를 모델링합니다. 여기서 그래프 라플라시안 정규화(regulation)을 적용하여 공간적 일관성을 유지하며, 주어진 텍스트에 기반한 변경 사항을 이미지의 전체적 구조를 유지하면서도 정확히 표현합니다.
- Performance Highlights: LOCATEdit는 PIE-Bench에서 기존의 상태-of-the-art 기법들보다 뛰어난 성능을 보여주었습니다. 편집이 의도한 영역에 국한됨으로써 PSNR, LPIPS, MSE, SSIM 등의 다양한 평가 지표에서 높은 수치를 기록하였고, CLIP 유사성 평가에서도 우수한 결과를 얻었습니다.
Vote: 1
Authors: Andrea Vedaldi, Zihang Lai
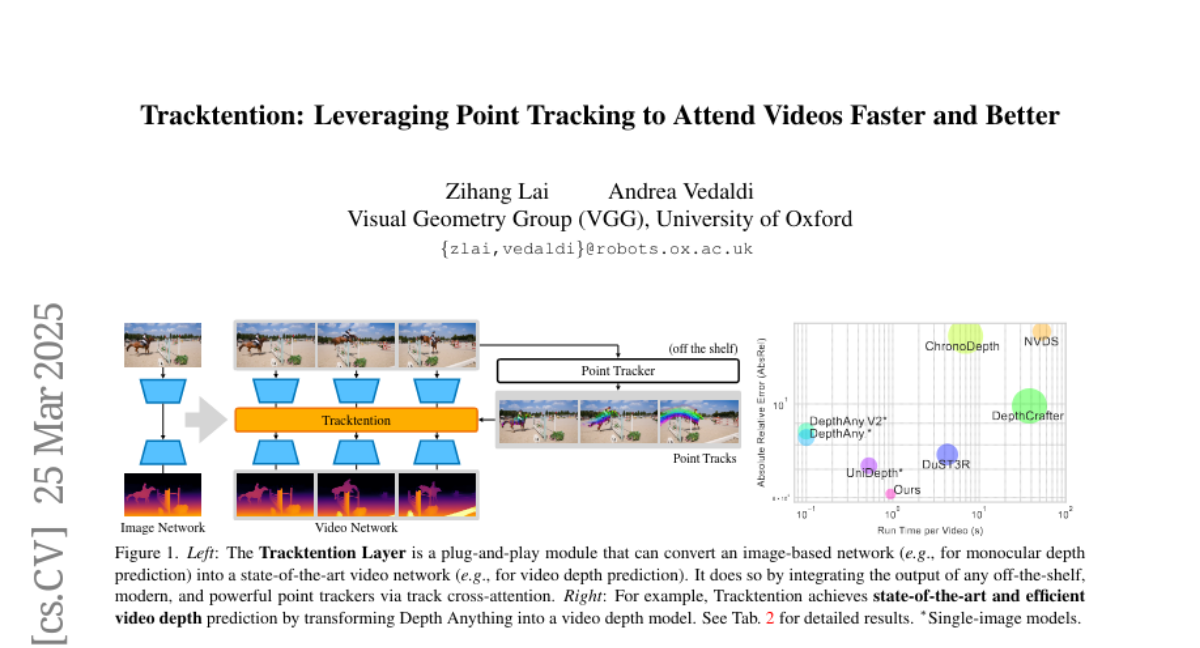
- What's New: Tracktention은 비디오 예측 속도와 품질을 향상시키기 위해 포인트 트래킹(Point Tracking)을 활용한 새로운 레이어입니다. 이는 이미지 네트워크(Image Network)를 최첨단 비디오 네트워크(Video Network)로 변환하여 복잡한 객체의 운동을 효과적으로 처리하도록 돕습니다.
- Technical Details: Tracktention 레이어는 비디오 프레임 간의 포인트 트랙(Point Tracks)을 활용하여 모션 정보를 명시적으로 통합합니다. 트랙 크로스-어텐션(Track Cross-Attention)을 통해 출력 정보를 강화하고 있어, 비전 트랜스포머(Vision Transformers)에 최소한의 수정으로 이식 가능합니다. 기본적으로, 이는 이미지 네트워크를 비디오 네트워크로 업그레이드하여 시간적 일관성을 개선합니다.
- Performance Highlights: DepthCrafter와 같은 기존 모델보다 적은 파라미터(140M)를 사용하면서, Tracktention으로 업그레이드된 모델이 비디오 깊이 예측 및 색상화에서 뛰어난 시간적 일관성과 정확성을 보여줍니다. 이는 시간적 아티팩트를 줄이면서 향상된 특징 표현을 유지합니다. 실험 결과는 포인트 트래커와의 시너지로 현재 비디오 기반 모델을 능가하며, 미래의 포인트 트래커 개선의 잠재적 이점을 제시합니다.
This project is licensed under the CC BY-NC 4.0 license.
If this work is helpful, please kindly cite as:
@misc{daily_papers,
title = {Huggingface Daily Papers},
author = {AK391},
howpublished = {\url{https://huggingface.co/papers}},
year = {2023}
}
@misc{daily_papers_ko,
title = {Automatically translate and summarize huggingface's daily papers into korean},
author = {l-yohai},
howpublished = {\url{https://github.com/l-yohai/daily_papers_ko}},
year = {2023}
}