超大大文件上传需求:
支持超大文件上传。
支持断点续传,关闭浏览器或刷新浏览器后仍然能够保留进度。
交互友好,能够及时反馈上传的进度;
服务端的安全性,不因上传文件功能导致JVM内存溢出影响其他功能使用;
最大限度利用网络上行带宽,提高上传速度;
设计分析:
对于大文件的处理,无论是用户端还是服务端,如果一次性进行读取发送、接收都是不可取,很容易导致内存问题。所以对于大文件上传,采用切块分段上传从上传的效率来看,利用多线程并发上传能够达到最大效率。
断点续传: 本次最主要的基础功能,在断网或者在暂停的情况下,能够在上传断点中继续上传。
分块上传: 也是归属于断点续传的基础功能之一,前端大文件分块后端组合,断点续传也是重传出错的这个分块
文件秒传: 上传前验证MD5 ,服务端返回一个代表这个文件已经上传了的状态,前端跳过这个文件前端:
webuploader
bootstrap
spark-md5(号称实现了最快的js读取md5值方法)
后端:
JDK 1.8.131
1、spring-boot-starter-web
3、lombok
4、springfox-boot-starter
5、knife4j-spring-boot-starter
6、spring-boot-starter-data-redis
7、spring-boot-starter-actuator (健康监控)
选择redis用于实现断点续传和秒传的功能的校验。当然也可以选择其他数据库。
当前研究了网上和大型互联网公司超大文件上传的案例。实现验证了一种认为是比较优的方案。比较传统的分片上传方式更取巧。
解决了一下问题:
1、分配上传时,会生成多个chunk文件,上传完成需要在推送合并请求
2、对于超大文件读取md5耗时过久问题
1、引入百度Web Uploader组件。(框架已经不怎么维护,存在一定bug,一般推荐使用vue-simple-uploader)
该组件实现了核心的主要功能:
分片、并发
分片与并发结合,将一个大文件分割成多块,并发上传,极大地提高大文件的上传速度。
当网络问题导致传输错误时,只需要重传出错分片,而不是整个文件。另外分片传输能够更加实时的跟踪上传进度。
MD5秒传
当文件体积大、量比较多时,支持上传前做文件md5值验证,一致则可直接跳过。
如果服务端与前端统一修改算法,取段md5,可大大提升验证性能,耗时在20ms左右。
这里偷懒再加上前端水平欠佳,所以偷取了 https://github.com/DaiYuanchuan/tool-upload 的界面。
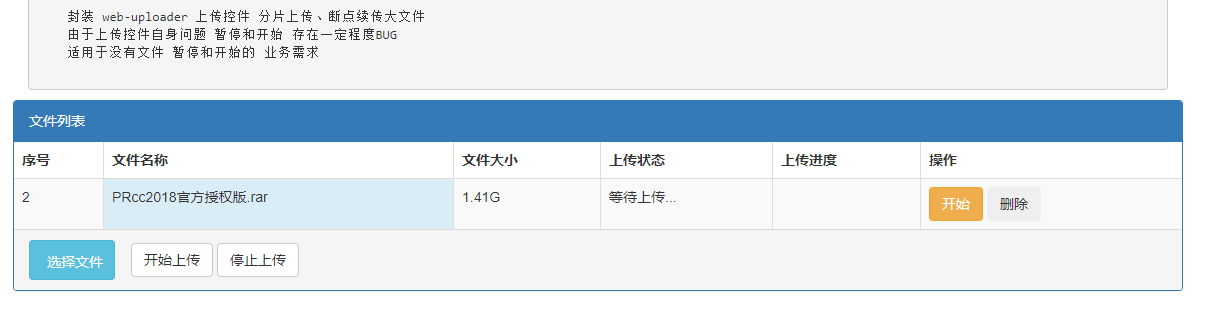
2、如何实现断点续传和秒传时读取超大文件的Md5值耗时过长问题。
Web Uploader 中有提供了方案:如果服务端与前端统一修改算法,取段md5,可大大提升验证性能,耗时在20ms左右。
(new WebUploader.Uploader()).md5File(file, 0, 5242880)
此处取第一个块的计算md5值。
但是这个比较容易被篡改。如果文件末尾在追加数据。那么实际上文件已经不一样。
优化方案:取第一个chunk的数据+最后一个chunk的数据+文件size大小,重新计算出md5。尽可能保证提高被篡改的难度。
当然这个优化方案还是有缺陷的,不能防止别人蓄意伪造修改数据的问题。
可以设计对于小于1G(看实际情况调整大小)的文件以下的文件,不使用抽样方式,全量计算md5值。根据文件大小来设定读取md5值。规避小文件以及文本文件更容易篡改问题。
网上的另一种实现每个块抽取部分数据,最后进行md5计算。思路上差不多。
拓展:通过抽样加快hash的计算速度
方法:抽取文件内一部分字段放入 chunks 数组内,通过减小计算 hash 的文件大小, 来增加hash的计算速度。
缺点:有少许可能照成误差,对于需精确计算hash则不适用,取舍有寸即可!
https://blog.csdn.net/qq_41614928/article/details/113974902
function calMd5(file) {
return new Promise((resolve, reject) => {
let chunkSize = 5 * 1024 * 1024, // Read in chunks of 5MB
chunks = Math.ceil(file.size / chunkSize),
spark = new SparkMD5.ArrayBuffer();
let flag = false;
let fileReader = new FileReader();
fileReader.onload = function (e) {
spark.append(e.target.result);
if (!flag) {
console.log("last chunk");
flag = true;
// 取最后一个chunk
fileReader.readAsArrayBuffer(blobSlice(file.source.getSource(), chunks * chunkSize, file.size));
}
};
fileReader.onerror = function (e) {
console.warn('oops, something went wrong.');
reject(e);
};
console.log("first chunk");
// 取第一个chunk
fileReader.readAsArrayBuffer(blobSlice(file.source.getSource(), 0, chunkSize > file.size ? file.size : chunkSize));
// 增加取得文件大小
spark.append(str2ab("" + file.size));
console.log("file.size==>" + file.size);
//生成最终的md5值
let md5 = spark.end();
console.info('computed hash', md5);
resolve(md5);
});
}
function blobSlice(blob, startByte, endByte) {
if (blob.slice) {
return blob.slice(startByte, endByte);
}
// 兼容firefox
if (blob.mozSlice) {
return blob.mozSlice(startByte, endByte);
}
// 兼容webkit
if (blob.webkitSlice) {
return blob.webkitSlice(startByte, endByte);
}
return null;
}
// 字符串转为ArrayBuffer对象,参数为字符串
function str2ab(str) {
var buf = new ArrayBuffer(str.length * 2); // 每个字符占用2个字节
var bufView = new Uint16Array(buf);
for (var i = 0, strLen = str.length; i < strLen; i++) {
bufView[i] = str.charCodeAt(i);
}
return buf;
}研究阿里云盘实现,从数据观察来看,也是抽样hash值(pre_hash)+size方案(具体实现未知)。所以觉得对于超大文件上传读取整个md5值是不大合理的,因此只能通过抽样生成一个hash值是一个合理的方式。
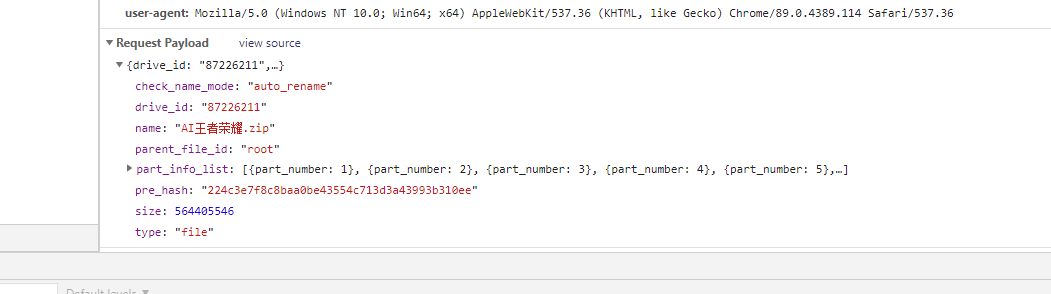
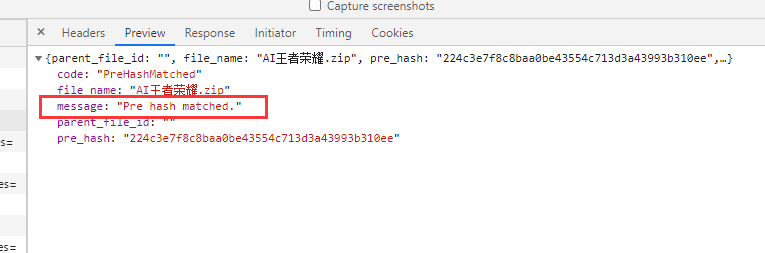
3、实现秒传判断,断点续传方案
-- 前端点击上传,在真正文件上传前,会先调用checkFileMd5附带计算好的md5值,传递给后端校验
-- 后端拿到md5值,去redis查询。
如果不存在,则通知前端需要全部上传。(全量上传)
如果存在,则检测是否已经上传完整。如果未上传完整,则计算出未上传的块,通知给前端。(断点续传)
如果存在,且已上传完整,则通知前端已上传。(秒传)
/**
* 秒传判断,断点判断
*
* @param md5 文件md5值
* @return ResponseEntity<FileUploadStatusVO> 上传情况
*/
@PostMapping(value = "/checkFileMd5")
@ResponseBody
public ResponseEntity<FileUploadStatusVO> checkFileMd5(String md5) throws IOException {
FileUploadStatusVO fileUploadStatusVO = new FileUploadStatusVO();
Object processingObj = hashOperations.get(Constants.FILE_UPLOAD_STATUS, md5);
// 文件未上传过
if (Objects.isNull(processingObj)) {
fileUploadStatusVO.setStatus(ResultStatusEnum.NO_HAVE);
return ResponseEntity.ok(fileUploadStatusVO);
}
String processingStr = processingObj.toString();
boolean processing = Boolean.parseBoolean(processingStr);
String filePath = (String) valueOperations.get(Constants.FILE_MD5_KEY + md5);
//文件已存在,秒传操作
if (processing) {
fileUploadStatusVO.setStatus(ResultStatusEnum.IS_HAVE);
fileUploadStatusVO.setFilePath(filePath);
return ResponseEntity.ok(fileUploadStatusVO);
}
//文件上传未完整
List<Integer> missChunkList = new ArrayList<>();
log.info("filePath == > {}", filePath);
byte[] completeList = Files.readAllBytes(Paths.get(filePath));
for (int i = 0; i < completeList.length; i++) {
if (completeList[i] != Byte.MAX_VALUE) {
missChunkList.add(i);
}
}
log.info("missChunkList===>{}", missChunkList.size());
fileUploadStatusVO.setStatus(ResultStatusEnum.ING_HAVE);
fileUploadStatusVO.setMissChunks(missChunkList);
return ResponseEntity.ok(fileUploadStatusVO);
}4、实现分块文件保存,并记录上传块信息
1、使用java的RandomAccessFile类,该类能随机读写文件。
上传文件先写入temp文件中,temp文件格式:【文件名_temp】。可认为是上传的临时文件。
2、每个块写入成功后,会写入大小为Byte.MAX_VALUE的数据写入【文件名.conf】文件中,用于记录上传进度。
一个Byte写入,则byte的索引就代表是第几个chunk,byte值127就代表该chunk为上传完成。
3、每个块上传完成后,都会检索conf文件中chunks长度的块是否都填充了Byte.MAX_VALUE。都填充了,说明文件已经上传完成。
全部上传完成重命名文件为上传的文件名称,即去掉_temp的后缀。
4、最后更新redis数据和删除conf文件。
RandomAccessFile详解:
RandomAccessFile既可以读取文件内容,也可以向文件输出数据。同时,RandomAccessFile支持“随机访问”的方式,程序快可以直接跳转到文件的任意地方来读写数据。
由于RandomAccessFile可以自由访问文件的任意位置,所以如果需要访问文件的部分内容,而不是把文件从头读到尾,使用RandomAccessFile将是更好的选择。
与OutputStream、Writer等输出流不同的是,RandomAccessFile允许自由定义文件记录指针,RandomAccessFile可以不从开始的地方开始输出,因此RandomAccessFile可以向已存在的文件后追加内容。如果程序需要向已存在的文件后追加内容,则应该使用RandomAccessFile。
RandomAccessFile的方法虽然多,但它有一个最大的局限,就是只能读写文件,不能读写其他IO节点。
RandomAccessFile的一个重要使用场景就是网络请求中的多线程下载及断点续传。
@Override
public void uploadFile(MultipartFileParam multipartFileParam) throws IOException {
String fileName = multipartFileParam.getName();
String uploadDirPath = finalDirPath + multipartFileParam.getMd5();
String tempFileName = fileName + Constants.FILE_NAME_TMP_SUFFIX;
File tmpDir = new File(uploadDirPath);
File tmpFile = new File(uploadDirPath, tempFileName);
if (!tmpDir.exists()) {
boolean mkdirs = tmpDir.mkdirs();
if (!mkdirs) {
log.error("目录创建失败");
}
}
File confFile = new File(uploadDirPath, multipartFileParam.getName() + Constants.FILE_NAME_CONF_SUFFIX);
// 上传分块文件
uploadChunkFileByRandomAccessFile(multipartFileParam, tmpFile);
//标记上传进度
tagChunkUpload(multipartFileParam, confFile);
//检测是否全部上传完成
boolean isComplete = isUploadComplete(confFile);
if (isComplete) {
//全部上传完成重命名文件
renameFile(tmpFile, fileName);
}
// 更新上传结果
updateUploadResult(multipartFileParam, isComplete);
// 删除conf文件
if (isComplete) {
confFile.delete();
}
}
private void uploadChunkFileByRandomAccessFile(MultipartFileParam multipartFileParam, File tmpFile) throws IOException {
try (RandomAccessFile accessTmpFile = new RandomAccessFile(tmpFile, "rw")) {
long offset = chunkSize * multipartFileParam.getChunk();
// 定位到该分片的偏移量
accessTmpFile.seek(offset);
// 写入该分片数据
accessTmpFile.write(multipartFileParam.getFile().getBytes());
}
}
private void updateUploadResult(MultipartFileParam multipartFileParam, boolean isComplete) {
log.info("isComplete ===>{}", isComplete);
String md5 = multipartFileParam.getMd5();
String name = multipartFileParam.getName();
String fileMd5Key = Constants.FILE_MD5_KEY + md5;
if (isComplete) {
hashOperations.put(Constants.FILE_UPLOAD_STATUS, md5, true);
valueOperations.set(fileMd5Key, finalDirPath + md5 + "/" + name);
} else {
if (!hashOperations.hasKey(Constants.FILE_UPLOAD_STATUS, md5)) {
hashOperations.put(Constants.FILE_UPLOAD_STATUS, md5, false);
}
if (valueOperations.get(fileMd5Key) == null) {
valueOperations.set(fileMd5Key, finalDirPath + md5 + "/" + name + Constants.FILE_NAME_CONF_SUFFIX);
}
}
}
private void tagChunkUpload(MultipartFileParam multipartFileParam, File confFile) throws IOException {
try (RandomAccessFile accessConfFile = new RandomAccessFile(confFile, "rw")) {
// 把该分段标记为 true 表示完成
accessConfFile.setLength(multipartFileParam.getChunks());
accessConfFile.seek(multipartFileParam.getChunk());
accessConfFile.write(Byte.MAX_VALUE);
}
}
private boolean isUploadComplete(File confFile) throws IOException {
// completeList 检查是否全部完成,如果数组里是否全部都是(全部分片都成功上传)
byte[] completeList = Files.readAllBytes(confFile.toPath());
for (byte chunkComplete : completeList) {
if (chunkComplete != Byte.MAX_VALUE) {
return false;
}
}
return true;
}
private boolean renameFile(File toBeRenamed, String toFileNewName) {
// 检查要重命名的文件是否存在,是否是文件
if (!toBeRenamed.exists() || toBeRenamed.isDirectory()) {
log.info("File does not exist: {}", toBeRenamed.getName());
return false;
}
File newFile = new File(toBeRenamed.getParent() + File.separatorChar + toFileNewName);
// 修改文件名
return toBeRenamed.renameTo(newFile);
}5、说下redis的设计
Hash:是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。
这里实现可以看成是一个名称为FILE_UPLOAD_STATUS对象,里面存储的key为文件md5值,value为是否上传成功的值。
用户点击上传时候,会先check文件是否已经上传完成。则会通过前端传入的md5值,去redis查询。
匹配key,如果不存在,则需要全量上传。
匹配key,value为true,则提示用户文件秒传成功。
匹配key,value为false,则需要去查询哪些chunk文件未上传,再通知给前端。
因此需要知道该文件上传进度的文件conf的路径,才能读取上传进度。
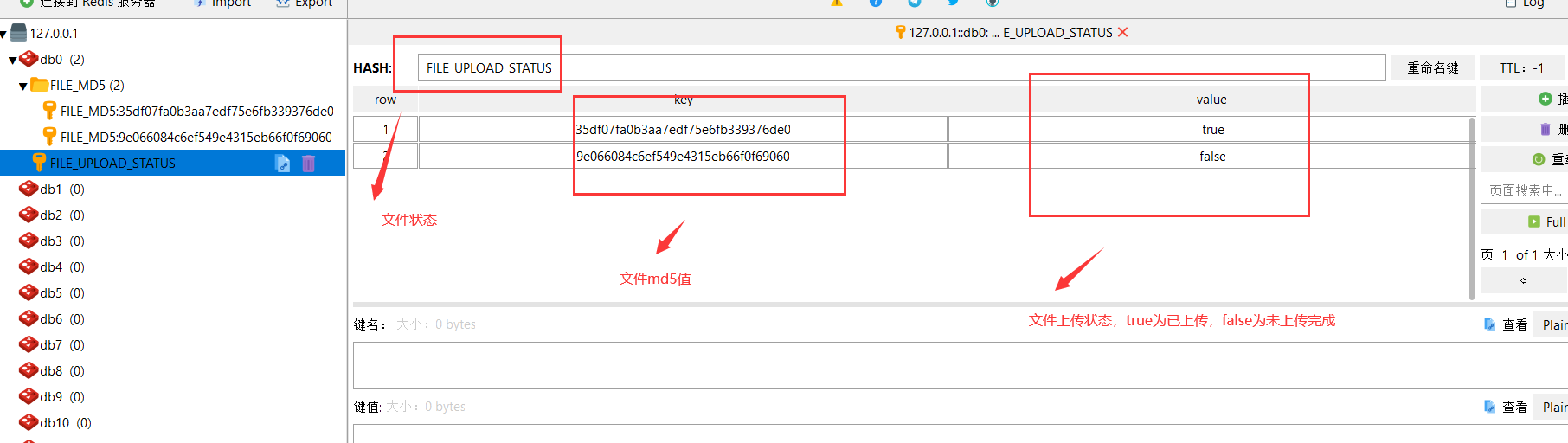
设计保存md5与conf文件路径对应。因此使用Redis 字符串(String)即可。
同时方便查询检索效率,增加以 FILE_MD5:为前缀,评接MD5值为Redis String的名称。value为存储上传文件的进度的路径。
这样即可实现通过md5值查找到对应文件上传进度的文件。用于筛选出未上传的chunk数组,传递给前端。前端根据匹配未上传的chunks来实现续传。
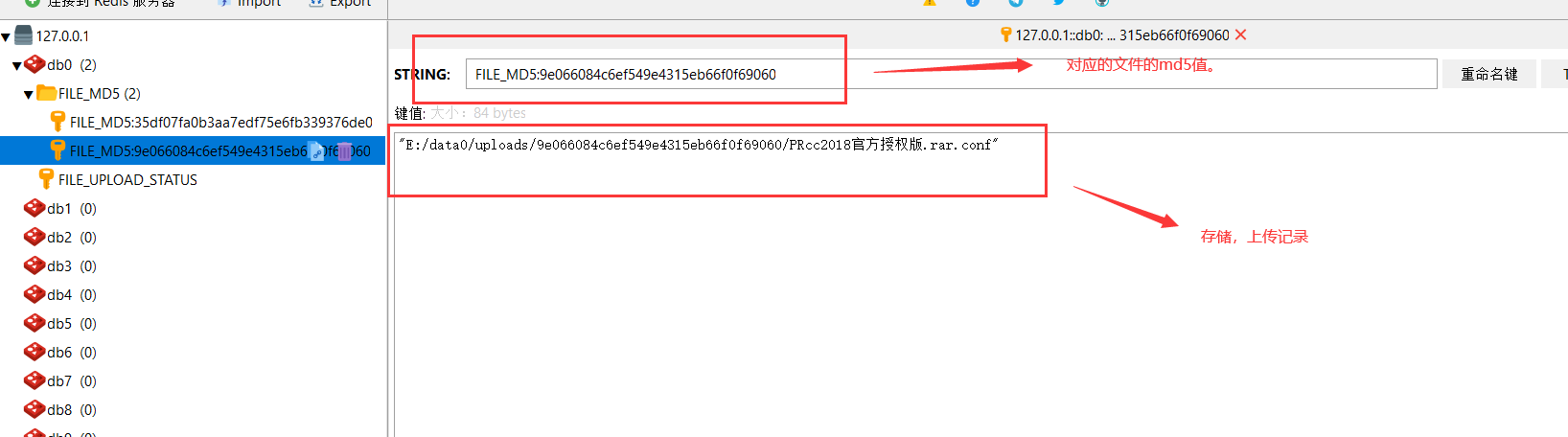
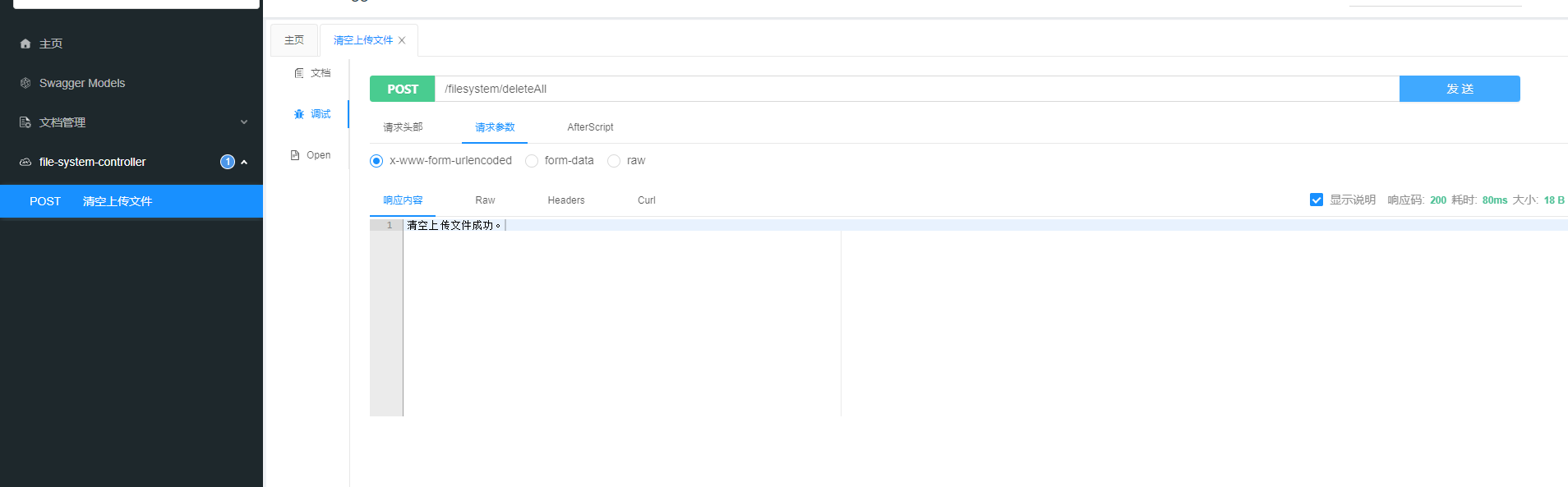
5、为了方便测试过程清理数据,引入了swagger2,用于快速删除数据。
含用于清空redis和上传的文件。
心得:
1、对于超大且不易被篡改的文件,要实现断点续传和秒传,可以使用读取部分文件内容+文件大小生成md5值。从而减少js对超大文件读取md5值耗时过长问题。
2、使用一个小文本文件记录上传进度是一种非常高效的处理方案,比分块存储后再请求合并方式效率高。
本文源码: https://github.com/lqnasa/springboot-filesystem
参考文档
https://github.com/DaiYuanchuan/tool-upload
vue学习