
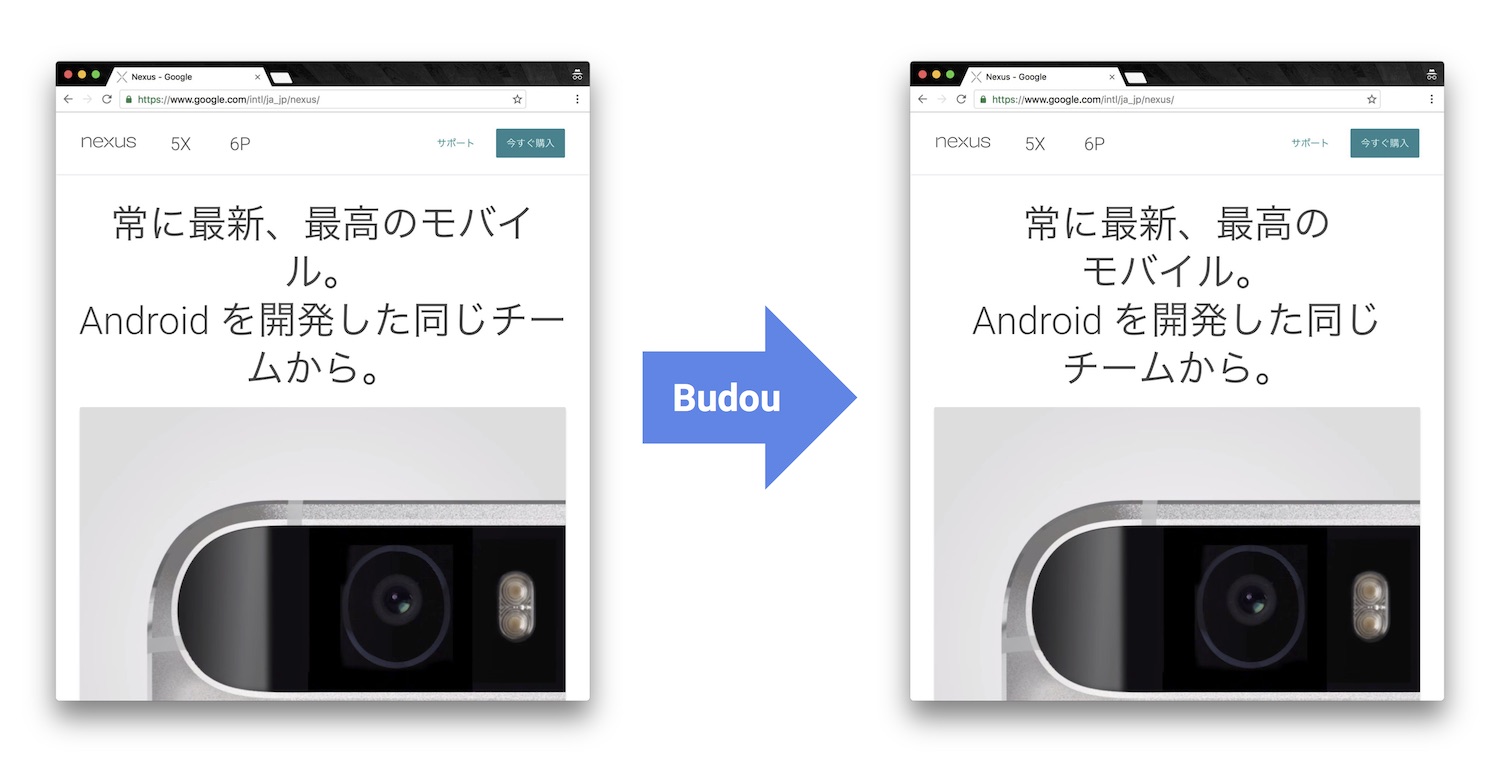
English uses spacing and hyphenation as cues to allow for beautiful and legible line breaks. Certain CJK languages have none of these, and are notoriously more difficult. Breaks occur randomly, usually in the middle of a word. This is a long standing issue in typography on web, and results in degradation of readability.
Budou automatically translates CJK sentences into organized HTML code
with lexical chunks wrapped in non-breaking markup so as to semantically control line breaks.
Budou uses Google Cloud Natural Language API
(NL API) to analyze the input sentence, and it concatenates proper words in
order to produce meaningful chunks utilizing part-of-speech (pos) tagging and
syntactic information.
Processed chunks are wrapped with SPAN tag, so semantic units will no longer
be split at the end of a line by specifying their display property as
inline-block in CSS.
Install the library by running pip install budou.
Also, a credential json file is needed for authorization to NL API.
Get the parser by completing authentication with a credential file for NL API, which can be downloaded from Google Cloud Platform by navigating through "API Manager" > "Credentials" > "Create credentials" > "Service account key" > "JSON".
import budou
# Login to Cloud Natural Language API with credentials
parser = budou.authenticate('/path/to/credentials.json')
result = parser.parse(u'今日も元気です', attributes={'class': 'wordwrap'}, language='ja')
print(result['html_code']) # => "<span class="wordwrap">今日も</span><span class="wordwrap">元気です</span>"
print(result['chunks'][0]['word']) # => "今日も"
print(result['chunks'][1]['word']) # => "元気です"Semantic units in the output HTML will not be split at the end of line by
conditioning each SPAN tag with display: inline-block in CSS.
.wordwrap {
display: inline-block;
}
- Japanese
Support for other Asian languages with line break issues, such as Chinese and Thai, will be added as Cloud Natural Language API adds support.
Korean has spaces between chunks, so you can organize line breaking simply by
putting word-break: keep-all in your CSS. No need for Budou :)
Budou is designed to be used mostly in eye-catching sentences such as titles and headings assuming split chunks would be more stood out negatively in larger typography.
Budou supports caching by default in order to save unnecessary requests to NL
API and make the processing faster. If you want to force refresh the cache,
put use_cache=False.
In a standard environment, Budou will create a cache file with python shelve format.
In Google App Engine Python Standard Environment, Budou will use memcache to make the cache available across instances.
Default parser only uses results from Syntactic Analysis for parsing, but you
can also utilize Entity Analysis by specifying use_entity=True.
Entity Analysis will improve the accuracy of parsing for some phrases,
especially proper nouns, so it is recommended to use if your target sentences
include a name of an individual person, place, organization etc.
Please note that Entity Analysis will results in additional pricing because it
requires additional requests to NL API. For more detail about API pricing, please
refer to Pricing | Google Cloud Natural Language API Documentation.
import budou
# Login to Google Cloud Natural Language API with credentials
parser = budou.authenticate('/path/to/credentials.json')
# Without Entity mode (default)
result = parser.parse(u'六本木ヒルズでご飯を食べます。', use_cache=False, language='ja')
print(result['html_code']) # => "<span class="ww">六本木</span><span class="ww">ヒルズに</span><span class="ww">います。</span>"
# With Entity mode
result = parser.parse(u'六本木ヒルズでご飯を食べます。', use_cache=False, language='ja', use_entity=True)
print(result['html_code']) # => "<span class="ww">六本木ヒルズに</span><span class="ww">います。</span>"Some screen reader software read wrapped chunks one by one when Budou is
applied, which may degrades user experience for those who need audio support.
You can attach any attribute to the output chunks to enhance accessibility.
For example, you can make screen readers to read undivided sentences by
combining aria-describedby and aria-label attribute in the output.
Input (your-script.py)
input_text = u'やりたいことのそばにいる'
element_id = 'description'
result = parser.parse(input_text, {'aria-describedby': element_id}, language='ja')Template (your-template.tpl)
<p id="{{element_id}}" aria-label="{{input_text}}">{{result.html_code}}</p>HTML Output (your-output.html)
<p id="description" aria-label="やりたいことのそばにいる">
<span class="ww" aria-describedby="description">やりたい</span>
<span class="ww" aria-describedby="description">ことの</span>
<span class="ww" aria-describedby="description">そばに</span>
<span class="ww" aria-describedby="description">いる</span>
</p>parser.parse() method accepts options below in addition to the input text.
| Option | Type | Default | Description |
|---|---|---|---|
| attributes | dictionary | {'class': 'ww'} |
A key-value mapping for attributes of output SPAN tags. |
| use_cache | boolean | True |
Whether to use caching. |
| language | str | None |
Language of the text. If None is provided, NL API tries to detect from the input text. |
| use_entity | boolean | False |
Whether to use Entity mode. |
Budou is backed up by Google Natural Language API, so cost may be incurred when using that API.
In other languages including Japanese, the default parser uses Syntax Analysis
and incurs cost according to monthly usage.
If you enable Entity mode by specifying use_entity=True, the parser uses both
of Syntax Analysis and Entity Analysis,
which will incur additional cost.
Google Cloud Natural Language API has free quota to start testing the feature at free of cost, but please refer to Google Cloud Natural Language API Pricing Guide for more detailed pricing information.
Shuhei Iitsuka
- Website: https://tushuhei.com
- Twitter: https://twitter.com/tushuhei
This library is authored by a Googler and copyrighted by Google, but is not an official Google product.
Copyright 2017 Google Inc. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.