Language Detection
This is a project on language detection.
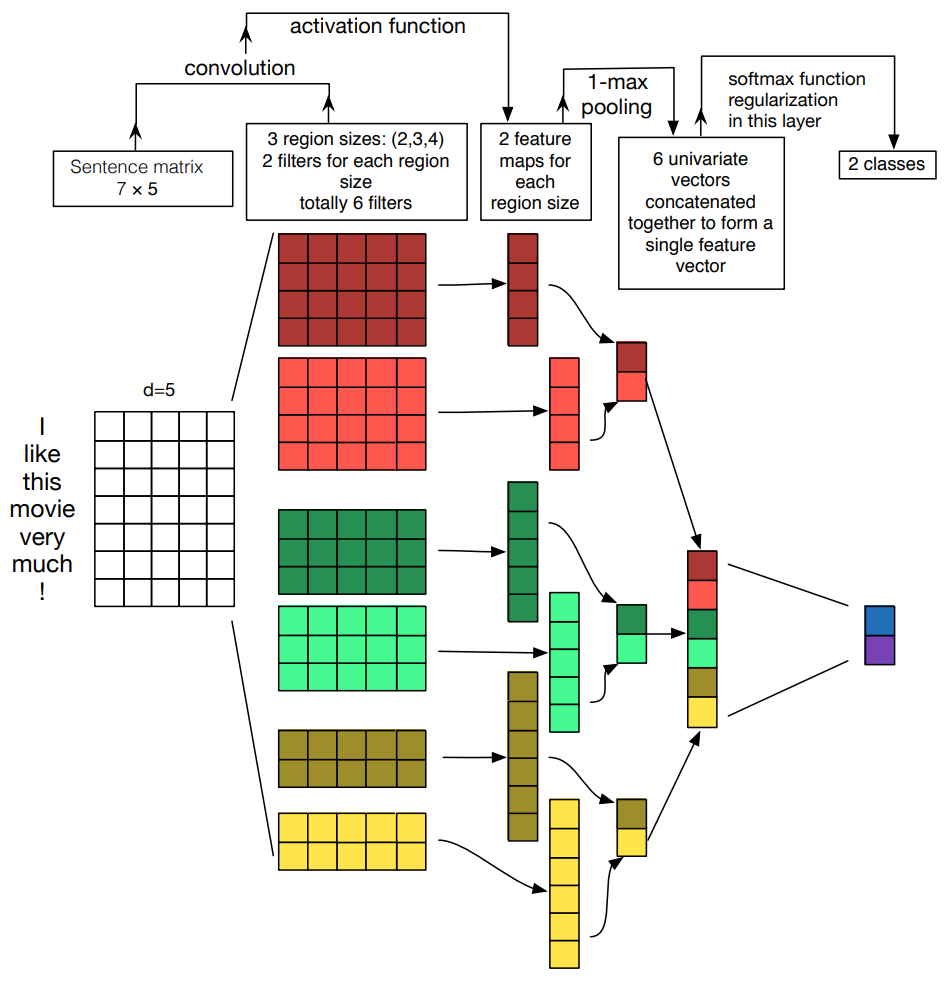
The model is based on the TextCNN [1][2].
- python 3.7
- Pytorch 1.5
- CUDA (Recommended version >=10.0)
- torchtext 0.11.0
We need download Tatoeba dataset as our train data, which includes 403 kinds of language. You can download in data directory:
wget http://downloads.tatoeba.org/exports/sentences.tar.bz2
bunzip2 sentences.tar.bz2
tar xvf sentences.tarFirst, the data should be processed:
python main.py --data_process It will first call data_process.py to split data to train_process.csv and test_process.csv. Before training, the parameters can be adjusted in args.py. Then the model can be trained as follow:
python main.py --train The model will be got in the model Directory and a vocab in the data directory. Training will cost a while, so we can directly use the vocabulary in the data directory and the model in the model directory.
The ability of the model we have trained can be tested by using test_process.csv:
python main.py --testThe model I trained has achieved 95.93% accuracy in the test set (10000 samples are randomly selected by default).
python main.py --test_singleThen you can follow the prompts to enter a single sentence and enjoy it.
At present, it only randomly initializes the word vector. In the future, the word vector trained by FastText [3][4] can be used in this model.
- [1] Chen Y. Convolutional neural network for sentence classification.University of Waterloo, 2015.
- [2] Zhang Y, Wallace B. A sensitivity analysis of (and practitioners' guide to) convolutional neural networks for sentence classification. arXiv preprint arXiv:1510.03820, 2015.
- [3] Joulin A, Grave E, Bojanowski P, et al. Bag of tricks for efficient text classification[J]. arXiv preprint arXiv:1607.01759, 2016.
- [4] Joulin A, Grave E, Bojanowski P, et al. Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759, 2016.