forked from rasbt/LLMs-from-scratch
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Add chatpgpt-like user interface (rasbt#360)
* Add chatpgpt-like user interface * fixes
- Loading branch information
Showing
9 changed files
with
670 additions
and
2 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,48 @@ | ||
| # Building a User Interface to Interact With the Pretrained LLM | ||
|
|
||
|
|
||
|
|
||
| This bonus folder contains code for running a ChatGPT-like user interface to interact with the pretrained LLMs from chapter 5, as shown below. | ||
|
|
||
|
|
||
|
|
||
| 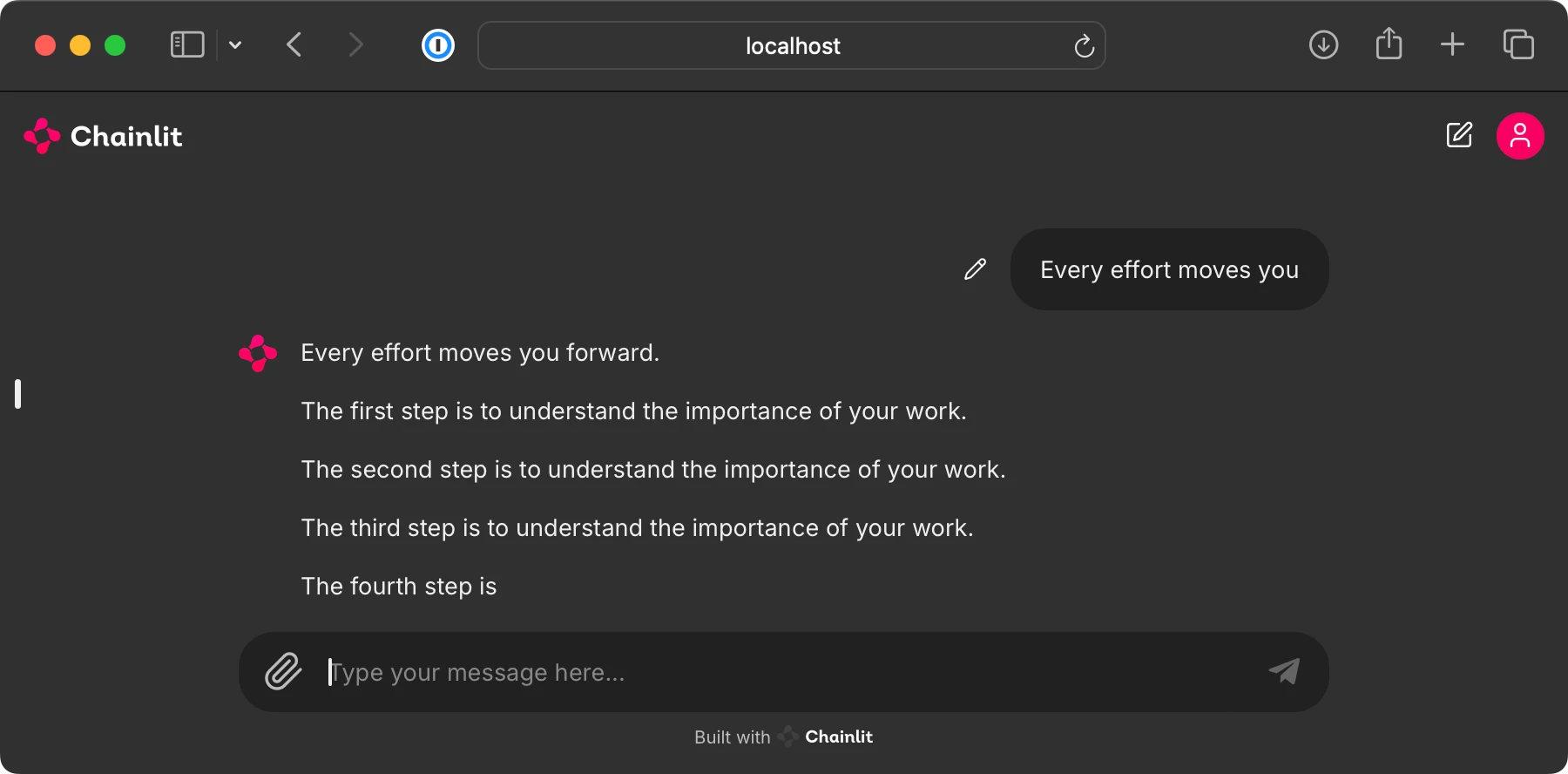 | ||
|
|
||
|
|
||
|
|
||
| To implement this user interface, we use the open-source [Chainlit Python package](https://github.com/Chainlit/chainlit). | ||
|
|
||
| | ||
| ## Step 1: Install dependencies | ||
|
|
||
| First, we install the `chainlit` package via | ||
|
|
||
| ```python | ||
| pip install chainlit | ||
| ``` | ||
|
|
||
| (Alternatively, execute `pip install -r requirements-extra.txt`.) | ||
|
|
||
| | ||
| ## Step 2: Run `app` code | ||
|
|
||
| This folder contains 2 files: | ||
|
|
||
| 1. [`app_orig.py`](app_orig.py): This file loads and uses the original GPT-2 weights from OpenAI. | ||
| 2. [`app_own.py`](app_own.py): This file loads and uses the GPT-2 weights we generated in chapter 5. This requires that you execute the [`../01_main-chapter-code/ch05.ipynb`] file first. | ||
|
|
||
| (Open and inspect these files to learn more.) | ||
|
|
||
| Run one of the following commands from the terminal to start the UI server: | ||
|
|
||
| ```bash | ||
| chainlit run app_orig.py | ||
| ``` | ||
|
|
||
| or | ||
|
|
||
| ```bash | ||
| chainlit run app_own.py | ||
| ``` | ||
|
|
||
| Running one of the commands above should open a new browser tab where you can interact with the model. If the browser tab does not open automatically, inspect the terminal command and copy the local address into your browser address bar (usually, the address is `http://localhost:8000`). |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,83 @@ | ||
| # Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt). | ||
| # Source for "Build a Large Language Model From Scratch" | ||
| # - https://www.manning.com/books/build-a-large-language-model-from-scratch | ||
| # Code: https://github.com/rasbt/LLMs-from-scratch | ||
|
|
||
| import tiktoken | ||
| import torch | ||
| import chainlit | ||
|
|
||
| from previous_chapters import ( | ||
| download_and_load_gpt2, | ||
| generate, | ||
| GPTModel, | ||
| load_weights_into_gpt, | ||
| text_to_token_ids, | ||
| token_ids_to_text, | ||
| ) | ||
|
|
||
|
|
||
| def get_model_and_tokenizer(): | ||
| """ | ||
| Code to loads a GPT-2 model with pretrained weights from OpenAI. | ||
| The code is similar to chapter 5. | ||
| The model will be downloaded automatically if it doesn't exist in the current folder, yet. | ||
| """ | ||
|
|
||
| CHOOSE_MODEL = "gpt2-small (124M)" # Optionally replace with another model from the model_configs dir below | ||
|
|
||
| BASE_CONFIG = { | ||
| "vocab_size": 50257, # Vocabulary size | ||
| "context_length": 1024, # Context length | ||
| "drop_rate": 0.0, # Dropout rate | ||
| "qkv_bias": True # Query-key-value bias | ||
| } | ||
|
|
||
| model_configs = { | ||
| "gpt2-small (124M)": {"emb_dim": 768, "n_layers": 12, "n_heads": 12}, | ||
| "gpt2-medium (355M)": {"emb_dim": 1024, "n_layers": 24, "n_heads": 16}, | ||
| "gpt2-large (774M)": {"emb_dim": 1280, "n_layers": 36, "n_heads": 20}, | ||
| "gpt2-xl (1558M)": {"emb_dim": 1600, "n_layers": 48, "n_heads": 25}, | ||
| } | ||
|
|
||
| model_size = CHOOSE_MODEL.split(" ")[-1].lstrip("(").rstrip(")") | ||
|
|
||
| BASE_CONFIG.update(model_configs[CHOOSE_MODEL]) | ||
|
|
||
| device = torch.device("cuda" if torch.cuda.is_available() else "cpu") | ||
|
|
||
| settings, params = download_and_load_gpt2(model_size=model_size, models_dir="gpt2") | ||
|
|
||
| gpt = GPTModel(BASE_CONFIG) | ||
| load_weights_into_gpt(gpt, params) | ||
| gpt.to(device) | ||
| gpt.eval() | ||
|
|
||
| tokenizer = tiktoken.get_encoding("gpt2") | ||
|
|
||
| return tokenizer, gpt, BASE_CONFIG | ||
|
|
||
|
|
||
| # Obtain the necessary tokenizer and model files for the chainlit function below | ||
| tokenizer, model, model_config = get_model_and_tokenizer() | ||
|
|
||
|
|
||
| @chainlit.on_message | ||
| async def main(message: chainlit.Message): | ||
| """ | ||
| The main Chainlit function. | ||
| """ | ||
| token_ids = generate( | ||
| model=model, | ||
| idx=text_to_token_ids(message.content, tokenizer), # The user text is provided via as `message.content` | ||
| max_new_tokens=50, | ||
| context_size=model_config["context_length"], | ||
| top_k=1, | ||
| temperature=0.0 | ||
| ) | ||
|
|
||
| text = token_ids_to_text(token_ids, tokenizer) | ||
|
|
||
| await chainlit.Message( | ||
| content=f"{text}", # This returns the model response to the interface | ||
| ).send() |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,76 @@ | ||
| # Copyright (c) Sebastian Raschka under Apache License 2.0 (see LICENSE.txt). | ||
| # Source for "Build a Large Language Model From Scratch" | ||
| # - https://www.manning.com/books/build-a-large-language-model-from-scratch | ||
| # Code: https://github.com/rasbt/LLMs-from-scratch | ||
|
|
||
| from pathlib import Path | ||
| import sys | ||
|
|
||
| import tiktoken | ||
| import torch | ||
| import chainlit | ||
|
|
||
| from previous_chapters import ( | ||
| generate, | ||
| GPTModel, | ||
| text_to_token_ids, | ||
| token_ids_to_text, | ||
| ) | ||
|
|
||
|
|
||
| def get_model_and_tokenizer(): | ||
| """ | ||
| Code to loads a GPT-2 model with pretrained weights generated in chapter 5. | ||
| This requires that you run the code in chapter 5 first, which generates the necessary model.pth file. | ||
| """ | ||
|
|
||
| GPT_CONFIG_124M = { | ||
| "vocab_size": 50257, # Vocabulary size | ||
| "context_length": 256, # Shortened context length (orig: 1024) | ||
| "emb_dim": 768, # Embedding dimension | ||
| "n_heads": 12, # Number of attention heads | ||
| "n_layers": 12, # Number of layers | ||
| "drop_rate": 0.1, # Dropout rate | ||
| "qkv_bias": False # Query-key-value bias | ||
| } | ||
|
|
||
| device = torch.device("cuda" if torch.cuda.is_available() else "cpu") | ||
|
|
||
| tokenizer = tiktoken.get_encoding("gpt2") | ||
|
|
||
| model_path = Path("..") / "01_main-chapter-code" / "model.pth" | ||
| if not model_path.exists(): | ||
| print(f"Could not find the {model_path} file. Please run the chapter 5 code (ch05.ipynb) to generate the model.pth file.") | ||
| sys.exit() | ||
|
|
||
| checkpoint = torch.load("model.pth", weights_only=True) | ||
| model = GPTModel(GPT_CONFIG_124M) | ||
| model.load_state_dict(checkpoint) | ||
| model.to(device) | ||
|
|
||
| return tokenizer, model, GPT_CONFIG_124M | ||
|
|
||
|
|
||
| # Obtain the necessary tokenizer and model files for the chainlit function below | ||
| tokenizer, model, model_config = get_model_and_tokenizer() | ||
|
|
||
|
|
||
| @chainlit.on_message | ||
| async def main(message: chainlit.Message): | ||
| """ | ||
| The main Chainlit function. | ||
| """ | ||
| token_ids = generate( | ||
| model=model, | ||
| idx=text_to_token_ids(message.content, tokenizer), # The user text is provided via as `message.content` | ||
| max_new_tokens=50, | ||
| context_size=model_config["context_length"], | ||
| top_k=1, | ||
| temperature=0.0 | ||
| ) | ||
|
|
||
| text = token_ids_to_text(token_ids, tokenizer) | ||
|
|
||
| await chainlit.Message( | ||
| content=f"{text}", # This returns the model response to the interface | ||
| ).send() |
Oops, something went wrong.