
Open Flux is a fork of the popular Open Source GitOps Toolkit Flux. Now, you might be wondering - since Flux is already open source, why is this fork called Open Flux? The Open in Open Flux refers to the architecture and ecosystem rather than the distribution of the software.
TLDR; Currently, Flux does not support adding custom source types (or transformation types - operations that might transform an artifact before handing it over to a deployer). Open Flux rather transparently adds this extensibility to Flux. In that sense, Open Flux opens up the Flux architecture and ecosystem to custom and community contributed source types (and transformation types).
NOTE: In addition to the concept of sources which produce artifacts and deployers which consume artifacts, we introduced the term transformations to describe general operations that consume and produce artifacts.
As a proof-of-concept, we have implemented a simple custom source using an http file server as source system here.
For an open source project with such a large and active community of developers such as Flux, we believe that opening up the ecosystem has the potential to add significant value. Therefore, we would love to see this idea to be adopted in the upstream Flux project!
NOTE: While we would be absolutely happy to contribute our code, we are of course not bent on our specific implementation.
As mentioned above, the idea of Open Flux is to enable community contributions to the Flux ecosystem. To further support this idea, we provide a library to implement artifact producers as well as a library to implement artifact consumers. So, these libraries can be used to quickly implement custom source and deployment controllers, or they can even be combined to implement custom transformation controllers.
NOTE: Admittedly, both of these libraries are currently still in a quite prototypical state. Usage examples for the producer can be found in our proof-of-concept http source controller here. Usage examples for the consumer can be found in our adjusted kustomize and helm controllers.
If you find the idea introduced above - an extensible Flux ecosystem - interesting (or if you are still wondering what we are even talking about), you can find a rather detailed explanation here. If you are already quite familiar with the current Flux architecture, and you are short on time, we suggest you merely skim through the Flux concepts section.
Overall, the explanation below relies heavily on the already existing Flux documentation (to an extent, where entire phrases were essentially copied).
The current Flux architecture revolves around the concepts of sources and deployers.
In the most generic sense, a source is a custom resource containing a technology specific access description to the contents of a storage (the currently supported source systems are git repositories, oci repositories, s3 buckets, and helm). Since flux is used for GitOps-based kubernetes deployments, the sources usually describe the technical access to kubernetes deployment instructions (currently either in form of plain manifests, kustomize overlays or helm packages).
These sources (or rather technology specific access descriptions) are reconciled by corresponding technology specific source controllers. Thereby, these controllers evaluate the access descriptions in regular intervals to access the storage to search for and download the latest version of the storage content (thus, currently, the latest version of plain manifests, kustomize overlays or helm packages).
As result of a successful reconcilation, the source controllers expose the downloaded content as so-called artifacts. An artifact is essentially an abstraction describing the downloaded content, especially its version and an URL based access to the downloaded content in form of a single blob. So currently, an artifact describes the version of some set of kubernetes manifests, kustomize overlays or helm packages and a URL to download an archive blob of those files.
Since all source controllers uniformly use this artifact abstraction to expose the downloaded content, the artifact abstraction is a common interface for content acquisition.
In the most generic sense, a deployer is a custom resource that references a source (which exposes the latest version of some kind of kubernetes deployment instruction) and describes additional deployment technology specific information about how and where to apply these instructions (the currently supported deployers are kustomization for plain manifest and kustomize overlays and helm for helm charts).
These deployers are reconciled by corresponding deployment technology specific deployment controllers. Thereby, these controllers evaluate the reference and the technology specific description in regular intervals. The reference is essentially only used to get the artifact abstraction which allows the controller to check whether the version of the deployment instructions has changed and therefore, to decide whether it has to download and apply the deployment instructions exposed by the source.
Since all source controllers uniformly use this artifact abstraction to expose the downloaded content, the deployers only have to understand the artifact abstraction in order to be able to use all the aforementioned types of source systems. So, the artifact abstraction serves as interface between sources and deployers.

This is a great concept!
Based on the introduced concept, potentially, the following 3 scenarios seem to have useful applications:
-
Additional types of sources can be added (as long as they produce artifacts that can be consumed by any kind of deployer).
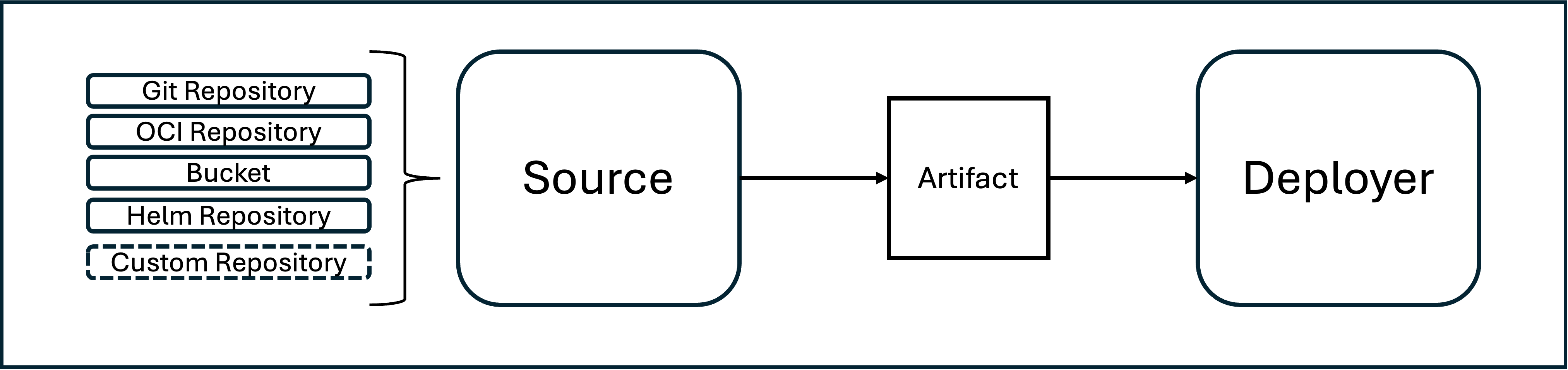
-
Additional types of deployers can be added (as long as they consume artifacts produced by any kind of source).
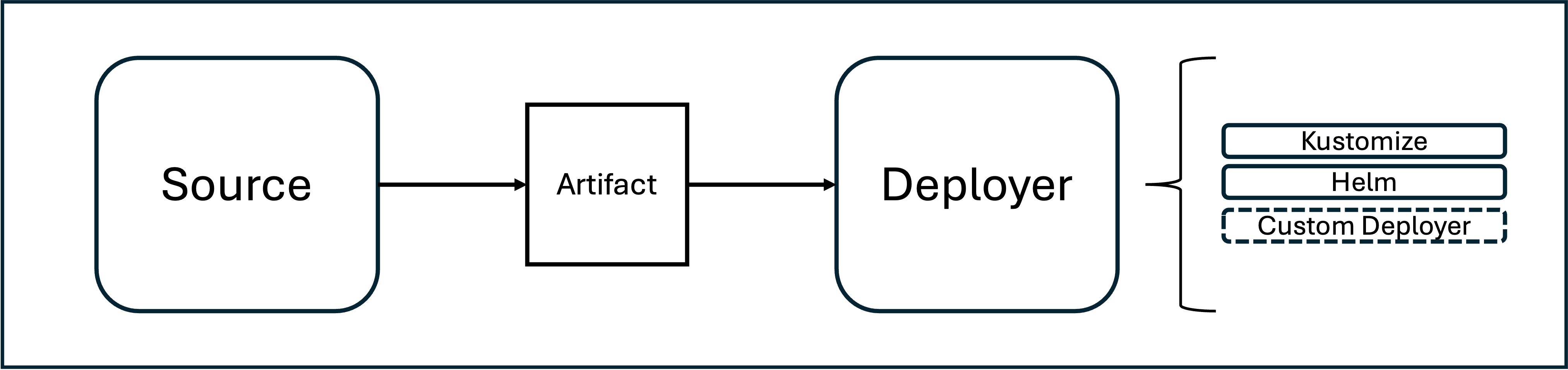
-
Additional transformations can be added (as long as they consume artifacts produced by any kind of source OR other transformation (= artifact producers) and produce artifacts that can be consumed by any kind of deployer OR other transformation (= artifact consumers)).




Due to the current flux implementation, it is only possible to add additional types of deployers (2).
In the current flux implementation, the source controllers expose the storage content by writing the artifact into the source's status (as it can be seen here).
While the source interface used in the controllers to get the artifact abstraction still gives the impression as if the controllers are based on the abstraction, architecturally, that is not actually the case.
The deployment controllers (or in general, artifact consumers) are forced to establish watches for each source type (thus, each kubernetes custom resource representing a type of source system) in order to subscribe to potential updates to the artifact (as can be seen here).
In order to know whether an object (or rather a struct type) implements a specific interface, such as the source interface, the controller has to know the struct type itself. Therefore, a static dependency to each source type is required.
This leads to an overall architecture with point-to-point connections as shown below.

So in its current form - with the above described implementation and architecture - flux is closed for extension of sources and transformations.
To enable the flexibility required to add further sources and transformations as well as deployers, it is crucial to provide an architecture in which the deployment controller code does not require knowledge about the complete set of potential sources.
To open flux's implementation and architecture for extension, open flux moves the artifact abstraction from the status of each source custom resource to an independent custom resource called artifact.

Thereby, open flux is able to resolve the previously shown point-to-point connection between the sources and the deployment controllers (or in general, artifact consumers).

NOTE: If you happen to look at the code within the open flux repositories, you might notice that this is not actually how it currently looks like. We want to keep open flux in sync with flux and therefore, decided to keep the changes to a minimum. Thus, while we adjusted the kustomization and the helm controllers to work with the artifact custom resource, we decided to keep the point-to-point connection to the existing source types for now. Otherwise, we would have had to adjust each source controller to produce an artifact custom resource instead of writing the artifact into the status.
The deployment controllers (or in general, artifact consumers) are no longer forced to watch each source type (thus, each kubernetes custom resource representing a type of source system) in order to subscribe to potential updates to the artifact. Instead, the deployment controllers merely have to watch the custom resources of type artifact, which are produced by source controllers for corresponding source custom resources (instead of writing the artifact information into their status).
As mentioned before - an artifact consumer (such as a deployer) is a custom resource that references an artifact producer custom resource (such as a source) and describes additional deployment technology (or transformation) specific information about how and where to apply these instructions.
So, even though the artifact consumers (such as the deployment controllers for kustomize or helm) watch the artifact custom resource, the artifact consumers will still primarily reference the artifact producer custom resource (such as the sources for git or oci) and not the artifact custom resource maintained by the artifact producer (although that is also possible, as shown below). The very existence of the artifact custom resource is still supposed to be rather transparent from a user interface perspective (or at least as transparent as the artifact was as a status property).
Consequently, based on the source reference within an artifact consumer custom resource (such as a kustomization), the open flux implementation of the artifact consumer controllers (such as the kustomize controller) has to find the corresponding artifact custom resource WITHOUT introducing a dependency to the struct type of the artifact producer type (such as the git repository struct type).
To solve this problem, we introduced an owner reference index mapping artifact producers (such as the git source) to their maintained artifacts.

NOTE: The code responsible for setting up that index can be found in the setup function of our artifact producer controller library here.
The index key attributes are the attributes contained in the source reference of an artifact consumer custom resource. Within the reconcile method, the artifact consumer controller obviously has access to this artifact consumer object containing the source reference (as this is the object being reconciled by this controller). Thus, the artifact consumer controller can use the source reference of the currently reconciled artifact consumer object to get the corresponding artifact object from the index.
The artifact itself is also added as a key to the owner reference index. We thought that artifact consumers should also be able to reference an artifact directly within the source reference. Thus, this allows to consult the index using the source reference independent of whether the source reference actually references a source object or the artifact itself. This enables to have manually maintained artifacts (for example, for testing purposes).
NOTE: As already mentioned at the top of this page, we put all the coding required to implement such artifact consumers (such as the kustomize or the helm) into a library. Currently, that library is available as a package within the artifact repository. Among other things, this library provides a convenient
Setup()function that does all the configurations required for a controller such a deployment controller (or as mentioned above, a transformation controller) such as setting up the correct indizes and watches with the correct event handlers.Furthermore, we also put all the coding required to implement artifact producers (such as the git repository controller or our custom http source controller) into a library. Currently, that library is available here. Among other things, this repository provides convenient functions to set up a controller manager with an artifact server that does all the maintenance of the downloaded content blobs and the creation of the artifact custom resource.
We used our library to adjust the current flux kustomize and helm controllers. But as we want to keep open flux in sync with flux, we decided to keep the changes to a minimum. Thus, while we adjusted the kustomize and the helm controllers to work with the artifact custom resource, we decided to keep the point-to-point connection to the existing source types for now. Otherwise, we would have had to adjust each source controller to produce an artifact custom resource instead of writing the artifact into the status. But this behaviour is hidden behind a setup function and therefore, completely transparent to the user of the library. Thus, once the existing flux source types produce artifacts, we can switch to uniformly watching artifacts without impacting users of the library.
The open flux project transparently enhances flux with the ability to be extended with arbitrary source types and additional transformation types.