[Paper]
LongProc (Long Procedural Generation) is a benchmark that evaluates long-context LLMs through long procedural generation, which requires models to follow specified procedures and generate structured outputs. See examples tasks below.
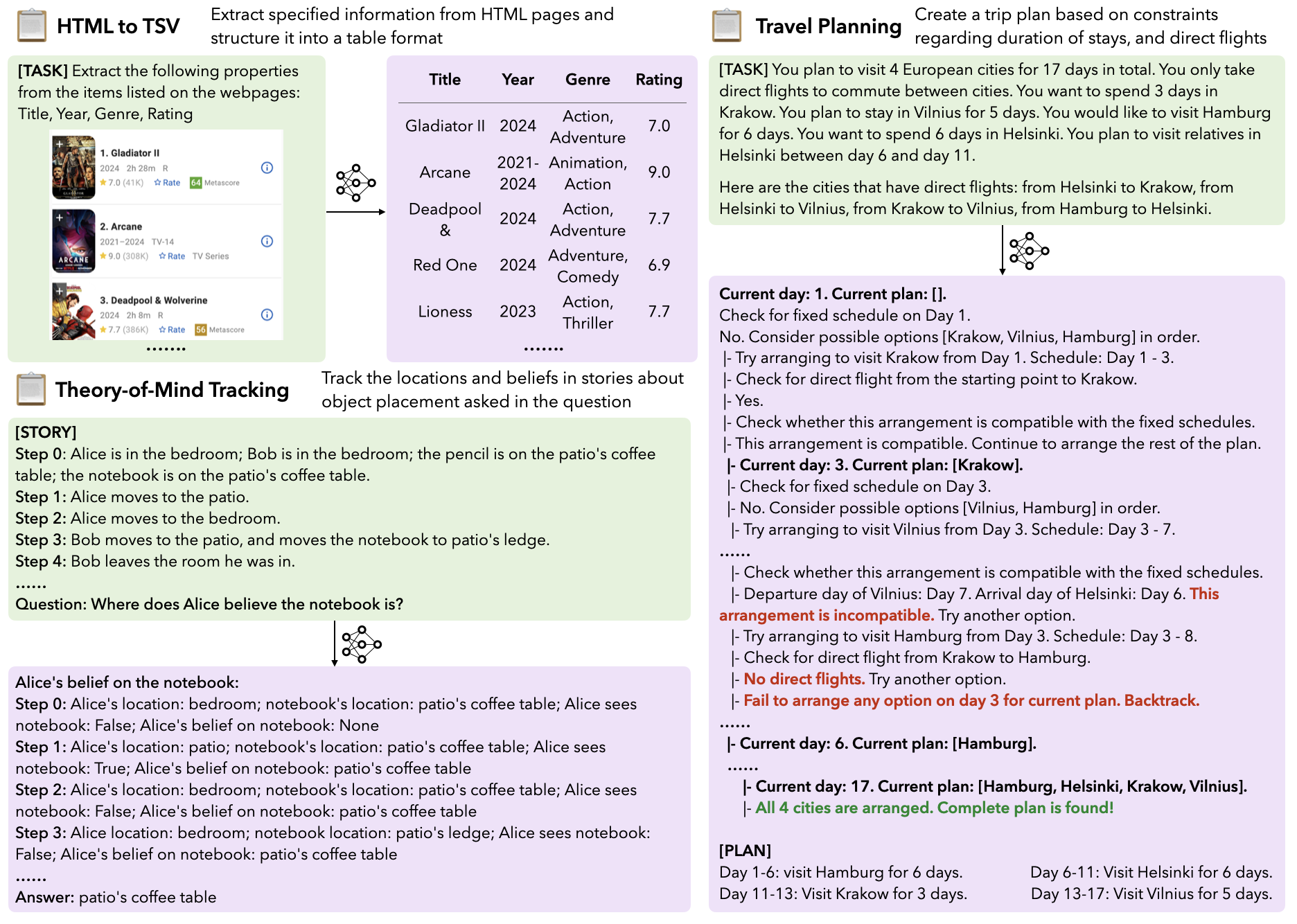
LongProc consists of 6 tasks. Each tasks generally includes three difficulty levels with maximum numbers of output tokens set at 500, 2K, and 8K. The 6 tasks are included as follows:
html_to_tsv(HTML TO TSV): Extract specified information from HTML pages and structure it into a table format (TSV)pseudo_to_code(Pseudocode to Code): Translate pseudocode that is structured line-by-line into corresponding C++ code.path_traversal(Path Traversal): Traverse a route that connects two cities in a graph where each city has only one outgoing connection.tom_tracking(Theory-of-Mind Tracking): Track the locations and beliefs in stories about object placement asked in the question.countdown(Countdown): Search to combine a set of numbers with basic arithmetic operations to reach a target number.travel_planning(Travel Planning): Search to create a trip plan based on constraints regarding duration of stays, and direct flights.
Please install the necessary packages with pip install -r requirements.txt.
We provide easily understandable examples for loading data and evaluating the results in example_usage.py. The example uses gpt-4o-mini API, please install openai and setup your OPENAI_API_KEY if you would like to run the example.
python example_usage.py --dataset path_traversal_0.5k
# dataset names are specified as [task_name]_[length]Call load_longproc_data in longproc.longproc_data. The function returns:
- A list of data points, each is a dict with
input_prompt(a string of the prompt)reference_output(the ground truth procedure trace), anditem(some meta info for the data point). - The corresponding evaluation function for the task. A evaluation function (e.g.
eval_path_traversalinlongproc.longproc_data), will take in the prediction (a string) and the data point, and returns: 1) metrics, and 2) additional information such as parsed outputs or brief descriptions of the errors.
With the code for loading data and evaluating predictions above you should be able to flexibly use your own codebase for running experiments.
In addition, we recommend using the HELMET codebase for more convenient evaluation. Please refer to the LongProc Addon of HELMET for evaluating LongProc.
For questions, feel free to open issues or email [email protected].
# Dataset
@article{ye25longproc,
title={LongProc: Benchmarking Long-Context Language Models on Long Procedural Generation},
author={Ye, Xi and Yin, Fangcong and He, Yinghui and Zhang, Joie and Howard, Yen and Gao, Tianyu and Durrett, Greg and Chen, Danqi},
journal={arXiv preprint},
year={2025}
}
# Running evaluation with HELMET
@misc{yen2024helmet,
title={HELMET: How to Evaluate Long-Context Language Models Effectively and Thoroughly},
author={Howard Yen and Tianyu Gao and Minmin Hou and Ke Ding and Daniel Fleischer and Peter Izsak and Moshe Wasserblat and Danqi Chen},
year={2024},
eprint={2410.02694},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2410.02694},
}Our benchmarks adapts several existing datasets. Please also cite the original datasets, listed below:
@article{arborist,
author = {Li, Xiang and Zhou, Xiangyu and Dong, Rui and Zhang, Yihong and Wang, Xinyu},
title = {Efficient Bottom-Up Synthesis for Programs with Local Variables},
year = {2024},
issue_date = {January 2024},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
volume = {8},
number = {POPL},
url = {https://doi.org/10.1145/3632894},
doi = {10.1145/3632894},
journal = {Proc. ACM Program. Lang.},
month = jan,
articleno = {52},
numpages = {29},
keywords = {Observational Equivalence, Program Synthesis, Web Automation}
}
@inproceedings{spoc,
author = {Kulal, Sumith and Pasupat, Panupong and Chandra, Kartik and Lee, Mina and Padon, Oded and Aiken, Alex and Liang, Percy S},
booktitle = {Proceedings of the Conference on Advances in Neural Information Processing Systems (NeurIPS)},
title = {{SPoC: Search-based Pseudocode to Code}},
}
@inproceedings{
gandhi2024stream,
title={{Stream of Search (SoS): Learning to Search in Language}},
author={Kanishk Gandhi and Denise H J Lee and Gabriel Grand and Muxin Liu and Winson Cheng and Archit Sharma and Noah Goodman},
booktitle={First Conference on Language Modeling},
year={2024},
}
@article{natplan,
title={{NATURAL PLAN: Benchmarking LLMs on Natural Language Planning}},
author={Zheng, Huaixiu Steven and Mishra, Swaroop and Zhang, Hugh and Chen, Xinyun and Chen, Minmin and Nova, Azade and Hou, Le and Cheng, Heng-Tze and Le, Quoc V and Chi, Ed H and others},
journal={arXiv preprint arXiv:2406.04520},
year={2024}
}