This repository explores various 2D positional encoding strategies for Vision Transformers (ViTs), including:
- No Position
- Learnable
- Sinusoidal (Absolute)
- Relative
- Rotary Position Embedding (RoPe)
The encodings are tested on CIFAR10 and CIFAR100 datasets with a compact ViT architecture (800k parameters).
- Implements 2D positional encodings by splitting dimensions into x and y sequences.
- Handles classification tokens uniquely for each encoding type.
- Provides a compact ViT model with only 800k parameters.
- Comprehensive comparisons across CIFAR10 and CIFAR100 datasets (using a patch size of 4).
Run commands (also available in scripts.sh)
Use the following command to run the model with different positional encodings:
python main.py --dataset cifar10 --pos_embed [TYPE]Replace TYPE with one of the following:
| Positional Encoding Type | Argument |
|---|---|
| No Position | --pos_embed none |
| Learnable | --pos_embed learn |
| Sinusoidal (Absolute) | --pos_embed sinusoidal |
| Relative | --pos_embed relative --max_relative_distance 2 |
| Rotary (RoPe) | --pos_embed rope |
- Use the
--datasetargument to switch between CIFAR10 and CIFAR100. - For relative encoding, adjust the
--max_relative_distanceparameter as needed.
Test set accuracy when ViT is trained using different positional Encoding.
| Positional Encoding Type | CIFAR10 | CIFAR100 |
|---|---|---|
| No Position | 79.63 | 53.25 |
| Learnable | 86.52 | 60.87 |
| Sinusoidal (Absolute) | 86.09 | 59.73 |
| Relative | 90.57 | 65.11 |
| Rotary (Rope) | 88.49 | 62.88 |
Instead of flattening image patches directly, we encode spatial information separately for the x and y axes:
- X-axis encoding applies 1D positional encoding to horizontal sequences.
- Y-axis encoding applies 1D positional encoding to vertical sequences.
Below is a visualization:
- X-axis Encoding
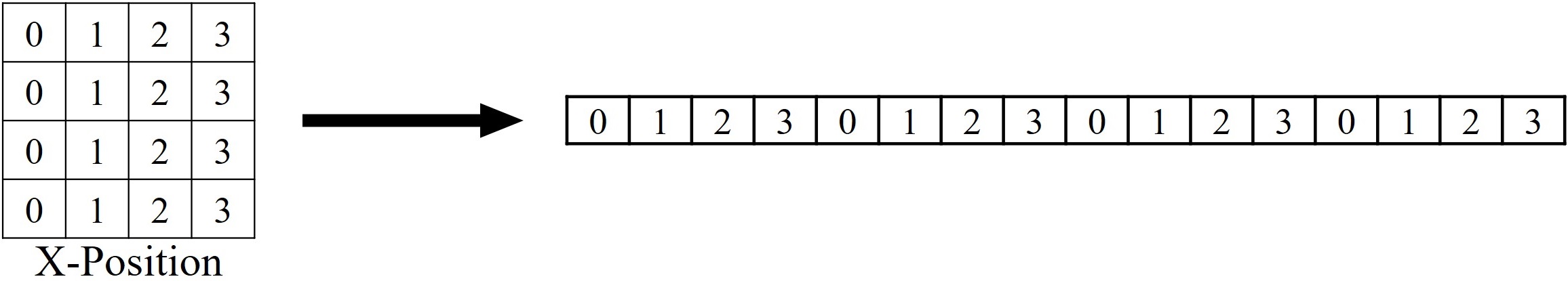
- Y-axis Encoding



The x and y-axis sequences are replicated using get_x_positions and get_y_positions functions from the utils.py file.
The resulting encodings are combined to represent 2D spatial positioning.

Positional encoding techniques handle classification tokens in unique ways:
- No Position: No encoding applied to classification tokens.
- Learnable: Classification token learns its encoding.
- Sinusoidal: Patch tokens receive sinusoidal encoding; classification token learns its own.
- Relative: The classification token is excluded from distance calculations. A fixed index (0) represents its distance in the lookup tables.
- Rotary (RoPe): X and Y positions start at 1 for patch tokens, reserving 0 for the classification token (no rotation applied).
The table below shows additional parameters introduced by different positional encodings:
| Encoding Type | Parameter Description | Count |
|---|---|---|
| No Position | N/A | 0 |
| Learnable | 64 x 128 |
8192 |
| Sinusoidal (Absolute) | No learned parameters | 0 |
| Relative | Derived from max_relative_distance and other factors | 2304 |
| Rotary (RoPe) | No learned parameters | 0 |
Below are the training and architecture configurations:
- Input Size: 3 x 32 x 32
- Patch Size: 4
- Sequence Length: 64
- Embedding Dimension: 128
- Number of Layers: 6
- Number of Attention Heads: 4
- Total Parameters: 820k
Note: This repo is built upon the following GitHub repo: Vision Transformers from Scratch in PyTorch
@article{vaswani2017attention,
title={Attention is all you need},
author={Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, {\L}ukasz and Polosukhin, Illia},
journal={Advances in neural information processing systems},
volume={30},
year={2017}
}
@inproceedings{dosovitskiy2020image,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and others},
booktitle={International Conference on Learning Representations},
year={2020}
}
@article{shaw2018self,
title={Self-attention with relative position representations},
author={Shaw, Peter and Uszkoreit, Jakob and Vaswani, Ashish},
journal={arXiv preprint arXiv:1803.02155},
year={2018}
}
@article{su2024roformer,
title={Roformer: Enhanced transformer with rotary position embedding},
author={Su, Jianlin and Ahmed, Murtadha and Lu, Yu and Pan, Shengfeng and Bo, Wen and Liu, Yunfeng},
journal={Neurocomputing},
volume={568},
pages={127063},
year={2024},
publisher={Elsevier}
}