![]()
Build multimodal AI services via cloud native technologies



![]()
Jina is a MLOps framework that empowers anyone to build multimodal AI services via cloud native technologies. It uplifts a local PoC into a production-ready service. Jina handles the infrastructure complexity, making advanced solution engineering and cloud-native technologies accessible to every developer.
Applications built with Jina enjoy the following features out of the box:
🌌 Universal
- Build applications that deliver fresh insights from multiple data types such as text, image, audio, video, 3D mesh, PDF with LF's DocArray.
- Support all mainstream deep learning frameworks.
- Polyglot gateway that supports gRPC, Websockets, HTTP, GraphQL protocols with TLS.
⚡ Performance
- Intuitive design pattern for high-performance microservices.
- Scaling at ease: set replicas, sharding in one line.
- Duplex streaming between client and server.
- Async and non-blocking data processing over dynamic flows.
☁️ Cloud native
- Seamless Docker container integration: sharing, exploring, sandboxing, versioning and dependency control via Executor Hub.
- Full observability via OpenTelemetry, Prometheus and Grafana.
- Fast deployment to Kubernetes, Docker Compose.
🍱 Ecosystem
- Improved engineering efficiency thanks to the Jina AI ecosystem, so you can focus on innovating with the data applications you build.
- Free CPU/GPU hosting via Jina AI Cloud.

pip install jinaFind more install options on Apple Silicon/Windows.
Document, Executor and Flow are three fundamental concepts in Jina.
- Document is the fundamental data structure.
- Executor is a Python class with functions that use Documents as IO.
- Flow ties Executors together into a pipeline and exposes it with an API gateway.
The full glossary is explained here.

A new project starts from local. With Jina, you can easily leverage existing deep learning stacks, improve the quality and quickly build the POC.
import torch
from jina import DocumentArray
model = torch.nn.Sequential(
torch.nn.Linear(
in_features=128,
out_features=128,
),
torch.nn.ReLU(),
torch.nn.Linear(in_features=128, out_features=32),
)
docs = DocumentArray.from_files('left/*.jpg')
docs.embed(model)Moving to production, Jina enhances the POC with service endpoint, scalability and adds cloud-native features, making it ready for production without refactoring.
from jina import DocumentArray, Executor, requests
from .embedding import model
class MyExec(Executor):
@requests(on='/embed')
async def embed(self, docs: DocumentArray, **kwargs):
docs.embed(model) |
jtype: Flow
with:
port: 12345
executors:
- uses: MyExec
replicas: 2 |
Finally, the project can be easily deployed to the cloud and serve real traffic.
jina cloud deploy ./

Leveraging these three concepts, let's look at a simple example below:
from jina import DocumentArray, Executor, Flow, requests
class MyExec(Executor):
@requests
async def add_text(self, docs: DocumentArray, **kwargs):
for d in docs:
d.text += 'hello, world!'
f = Flow().add(uses=MyExec).add(uses=MyExec)
with f:
r = f.post('/', DocumentArray.empty(2))
print(r.texts)- The first line imports three concepts we just introduced;
MyExecdefines an async functionadd_textthat receivesDocumentArrayfrom network requests and appends"hello, world"to.text;fdefines a Flow streamlined two Executors in a chain;- The
withblock opens the Flow, sends an empty DocumentArray to the Flow, and prints the result.
Running it gives you:

At the last line we see its output ['hello, world!hello, world!', 'hello, world!hello, world!'].
While you could use standard Python with the same number of lines and get the same output, Jina accelerates time to market of your application by making it more scalable and cloud-native. Jina also handles the infrastructure complexity in production and other Day-2 operations so that you can focus on the data application itself.

The example above can be refactored into a Python Executor file and a Flow YAML file:
toy.yml |
executor.py |
|---|---|
jtype: Flow
with:
port: 51000
protocol: grpc
executors:
- uses: MyExec
name: foo
py_modules:
- executor.py
- uses: MyExec
name: bar
py_modules:
- executor.py |
from jina import DocumentArray, Executor, requests
class MyExec(Executor):
@requests
async def add_text(self, docs: DocumentArray, **kwargs):
for d in docs:
d.text += 'hello, world!' |
Run the following command in the terminal:
jina flow --uses toy.yml

The server is successfully started, and you can now use a client to query it.
from jina import Client, Document
c = Client(host='grpc://0.0.0.0:51000')
c.post('/', Document())This simple refactoring allows developers to write an application in the client-server style. The separation of Flow YAML and Executor Python file does not only make the project more maintainable but also brings scalability and concurrency to the next level:
- The data flow on the server is non-blocking and async. New request is handled immediately when an Executor is free, regardless if previous request is still being processed.
- Scalability can be easily achieved by the keywords
replicasandneedsin YAML/Python. Load-balancing is automatically added when necessary to ensure the maximum throughput.
toy.yml |
Flowchart |
|---|---|
jtype: Flow
with:
port: 51000
protocol: grpc
executors:
- uses: MyExec
name: foo
py_modules:
- executor.py
replicas: 2
- uses: MyExec
name: bar
py_modules:
- executor.py
replicas: 3
needs: gateway
- needs: [foo, bar]
name: baz |
|

- You now have an API gateway that supports gRPC (default), Websockets, and HTTP protocols with TLS.
- The communication between clients and the API gateway is duplex.
- The API gateway allows you to route request to a specific Executor while other parts of the Flow are still busy, via
.post(..., target_executor=...)

Without having to worry about dependencies, you can easily share your Executors with others; or use public/private Executors in your project thanks to Executor Hub.
To create an Executor:
jina hub new To push it to Executor Hub:
jina hub push .To use a Hub Executor in your Flow:
| Docker container | Sandbox | Source | |
|---|---|---|---|
| YAML | uses: jinaai+docker://<username>/MyExecutor |
uses: jinaai+sandbox://<username>/MyExecutor |
uses: jinaai://<username>/MyExecutor |
| Python | .add(uses='jinaai+docker://<username>/MyExecutor') |
.add(uses='jinaai+sandbox://<username>/MyExecutor') |
.add(uses='jinaai://<username>/MyExecutor') |
Behind this smooth experience is advanced management of Executors:
- Automated builds on the cloud
- Store, deploy, and deliver Executors cost-efficiently;
- Automatically resolve version conflicts and dependencies;
- Instant delivery of any Executor via Sandbox without pulling anything to local.

Using Kubernetes becomes easy:
jina export kubernetes flow.yml ./my-k8s
kubectl apply -R -f my-k8sUsing Docker Compose becomes easy:
jina export docker-compose flow.yml docker-compose.yml
docker-compose upTracing and monitoring with OpenTelemetry is straightforward:
from jina import Executor, requests, DocumentArray
class MyExec(Executor):
@requests
def encode(self, docs: DocumentArray, **kwargs):
with self.tracer.start_as_current_span(
'encode', context=tracing_context
) as span:
with self.monitor(
'preprocessing_seconds', 'Time preprocessing the requests'
):
docs.tensors = preprocessing(docs)
with self.monitor(
'model_inference_seconds', 'Time doing inference the requests'
):
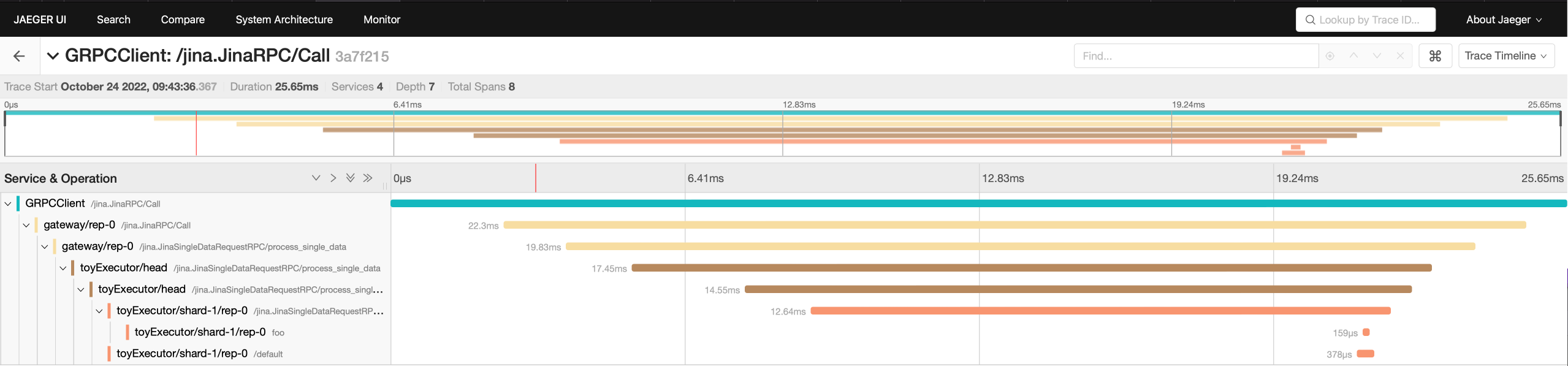
docs.embedding = model_inference(docs.tensors)You can integrate Jaeger or any other distributed tracing tools to collect and visualize request-level and application level service operation attributes. This helps you analyze request-response lifecycle, application behavior and performance.
To use Grafana, download this JSON and import it into Grafana:
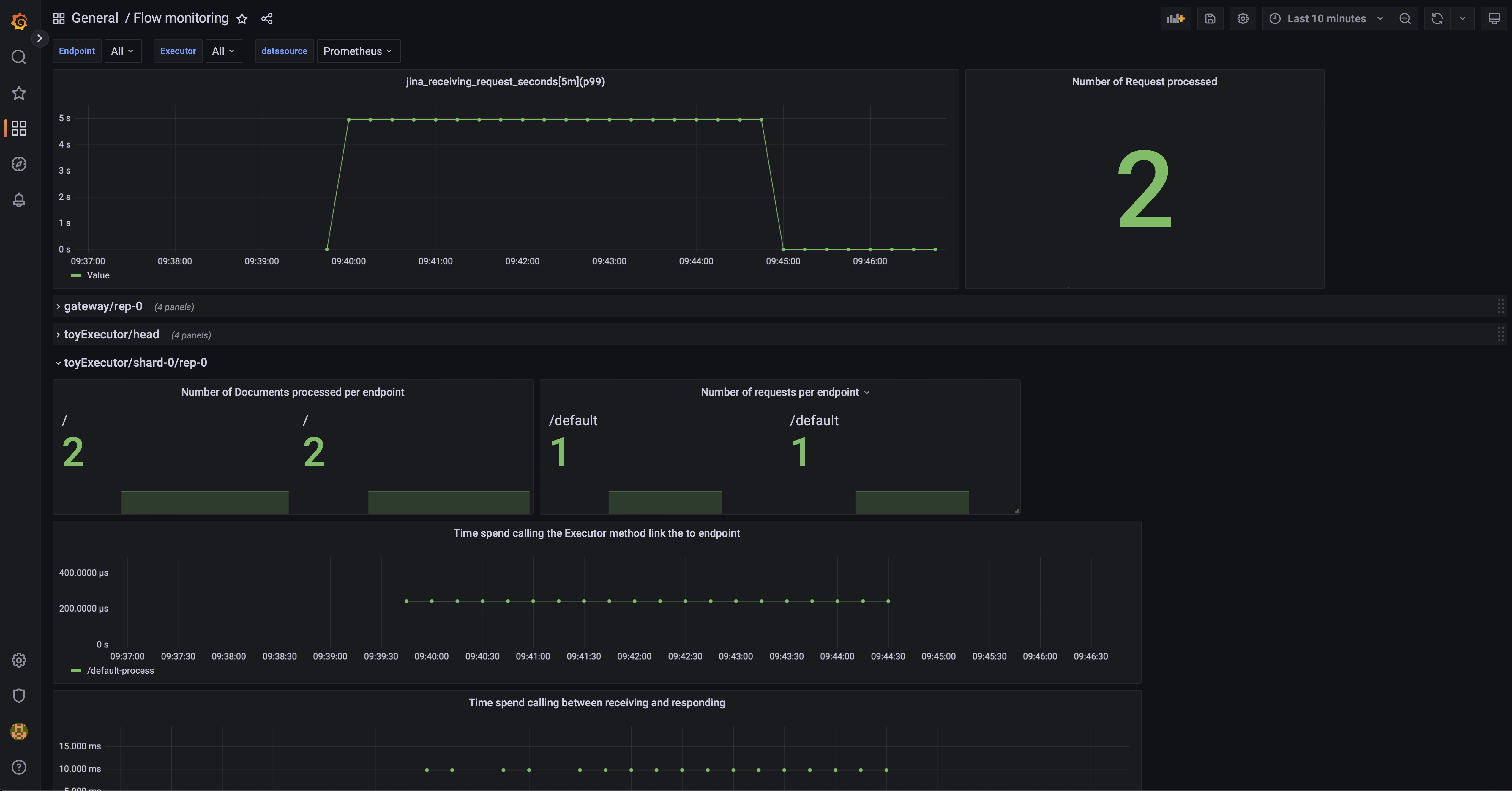
To trace requests with Jaeger:
What cloud-native technology is still challenging to you? Tell us, we will handle the complexity and make it easy for you.
- Join our Slack community and chat with other community members about ideas.
- Join our Engineering All Hands meet-up to discuss your use case and learn Jina's new features.
- When? The second Tuesday of every month
- Where? Zoom (see our public events calendar/.ical) and live stream on YouTube
- Subscribe to the latest video tutorials on our YouTube channel
Jina is backed by Jina AI and licensed under Apache-2.0.