Antialiased CNNs [Project Page] [Paper]
Making Convolutional Networks Shift-Invariant Again
Richard Zhang.
To appear in ICML, 2019.
This repository contains examples of anti-aliased convnets. We build off publicly available PyTorch ImageNet and models repositories, with add-ons for antialiasing:
- a low-pass filter layer (called
BlurPoolin the paper), which can be easily plugged into any network - antialiased AlexNet, VGG, ResNet, DenseNet architectures, along with pretrained weights
- benchmarking code and evaluation for shift-invariance (
-esflag)
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.

All material is made available under Creative Commons BY-NC-SA 4.0 license by Adobe Inc. You can use, redistribute, and adapt the material for non-commercial purposes, as long as you give appropriate credit by citing our paper and indicating any changes that you've made.
The repository builds off the PyTorch examples repository and torchvision models repository. It is BSD-style licensed.
- Install PyTorch (pytorch.org)
pip install -r requirements.txt- Download the ImageNet dataset and move validation images to labeled subfolders
- To do this, you can use the following script: https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh
- Run
bash weights/get_antialiased_models.py
We provide models with filter sizes 2,3,5 for AlexNet, VGG16, VGG16bn, ResNet18,34,50, and DenseNet121.
python main.py --data /PTH/TO/ILSVRC2012 -e -f 5 -a alexnet_lpf --resume ./weights/alexnet_lpf5.pth.tar --gpu 0
python main.py --data /PTH/TO/ILSVRC2012 -e -f 5 -a vgg16_lpf --resume ./weights/vgg16_lpf5.pth.tar
python main.py --data /PTH/TO/ILSVRC2012 -e -f 5 -a vgg16_bn_lpf --resume ./weights/vgg16_bn_lpf5.pth.tar
python main.py --data /PTH/TO/ILSVRC2012 -e -f 5 -a resnet18_lpf --resume ./weights/resnet18_lpf5.pth.tar
python main.py --data /PTH/TO/ILSVRC2012 -e -f 5 -a resnet34_lpf --resume ./weights/resnet34_lpf5.pth.tar
python main.py --data /PTH/TO/ILSVRC2012 -e -f 5 -a resnet50_lpf --resume ./weights/resnet50_lpf5.pth.tar
python main.py --data /PTH/TO/ILSVRC2012 -e -f 5 -a densenet121_lpf --resume ./weights/densenet121_lpf5.pth.tarSame as above, but flag -es evaluates the shift-consistency -- how often two random 224x224 crops are classified the same.
python main.py --data /PTH/TO/ILSVRC2012 -es -b 8 -f 5 -a alexnet_lpf --resume ./weights/alexnet_lpf5.pth.tar --gpu 0
python main.py --data /PTH/TO/ILSVRC2012 -es -b 8 -f 5 -a vgg16_lpf --resume ./weights/vgg16_lpf5.pth.tar
python main.py --data /PTH/TO/ILSVRC2012 -es -b 8 -f 5 -a vgg16_bn_lpf --resume ./weights/vgg16_bn_lpf5.pth.tar
python main.py --data /PTH/TO/ILSVRC2012 -es -b 8 -f 5 -a resnet18_lpf --resume ./weights/resnet18_lpf5.pth.tar
python main.py --data /PTH/TO/ILSVRC2012 -es -b 8 -f 5 -a resnet34_lpf --resume ./weights/resnet34_lpf5.pth.tar
python main.py --data /PTH/TO/ILSVRC2012 -es -b 8 -f 5 -a resnet50_lpf --resume ./weights/resnet50_lpf5.pth.tar
python main.py --data /PTH/TO/ILSVRC2012 -es -b 8 -f 5 -a densenet121_lpf --resume ./weights/densenet121_lpf5.pth.tarSome notes:
- These line commands are very similar to the base PyTorch repository. We simply add suffix
_lpfto the architecture and specify-ffor filter size. - Substitute
-f 5and appropriate filepath for different filter sizes. - The example commands use our weights. You can them from your own training session.
The following commands train antialiased AlexNet, VGG16, VGG16bn, ResNet18,34,50, and Densenet121 models with filter size 5. Output models will be in [[OUT_DIR]]/model_best.pth.tar
python main.py --data /PTH/TO/ILSVRC2012 -f 5 -a alexnet_lpf --out-dir alexnet_lpf5 --gpu 0 --lr .01
python main.py --data /PTH/TO/ILSVRC2012 -f 5 -a vgg16_lpf --out-dir vgg16_lpf5 --lr .01 -b 128 -ba 2
python main.py --data /PTH/TO/ILSVRC2012 -f 5 -a vgg16_bn_lpf --out-dir vgg16_bn_lpf5 --lr .05 -b 128 -ba 2
python main.py --data /PTH/TO/ILSVRC2012 -f 5 -a resnet18_lpf --out-dir resnet18_lpf5
python main.py --data /PTH/TO/ILSVRC2012 -f 5 -a resnet34_lpf --out-dir resnet34_lpf5
python main.py --data /PTH/TO/ILSVRC2012 -f 5 -a resnet50_lpf --out-dir resnet50_lpf5
python main.py --data /PTH/TO/ILSVRC2012 -f 5 -a densenet121_lpf --out-dir densenet121_lpf5 -b 128 -ba 2Some notes:
- As suggested by the official repository, AlexNet and VGG16 require lower learning rates of
0.01(default is0.1). - VGG16_bn also required a slightly lower learning rate of
0.05. - I train AlexNet on a single GPU (the network is fast, so preprocessing becomes the limiting factor if multiple GPUs are used).
- Default batch size is
256. Some extra memory is added for the antialiasing layers, so the default batchsize may no longer fit in memory. To get around this, we simply accumulate gradients over 2 smaller batches-b 128with flag--ba 2. You may find this useful, even for the default models, if you are training with smaller/fewer GPUs. It is not exactly identical to training with a large batch, as the batchnorm statistics will be computed with a smaller batch.
The methodology is simple -- first evaluate with stride 1, and then use our Downsample layer to do the striding.
-
Copy models_lpf/__init__.py into your codebase. This contains the
Downsamplelayer which does blur+subsampling. -
Put the following into your header to get the
Downsampleclass.
from models_lpf import *- Make the following architectural changes.
| Original | Anti-aliased replacement | |
|---|---|---|
| MaxPool --> MaxBlurPool |
[nn.MaxPool2d(kernel_size=2, stride=2),] |
[nn.MaxPool2d(kernel_size=2, stride=1), Downsample(filt_size=M, stride=2, channels=C)] |
| StridedConv --> ConvBlurPool |
[nn.Conv2d(Cin, C, kernel_size=3, stride=2, padding=1), nn.ReLU(inplace=True)] |
[nn.Conv2d(Cin, C, kernel_size=3, stride=1, padding=1), nn.ReLU(inplace=True), Downsample(filt_size=M, stride=2, channels=C)] |
| AvgPool --> BlurPool |
nn.AvgPool2d(kernel_size=2, stride=2) |
Downsample(filt_size=M, stride=2, channels=C) |
We assume blur kernel size M (3 or 5 is typical) and that the tensor has C channels.
Note that this requires computing a layer at stride 1 instead of stride 2, which adds memory and run-time. We typically skip this step for at the highest-resolution (early in the network), to prevent large increases.
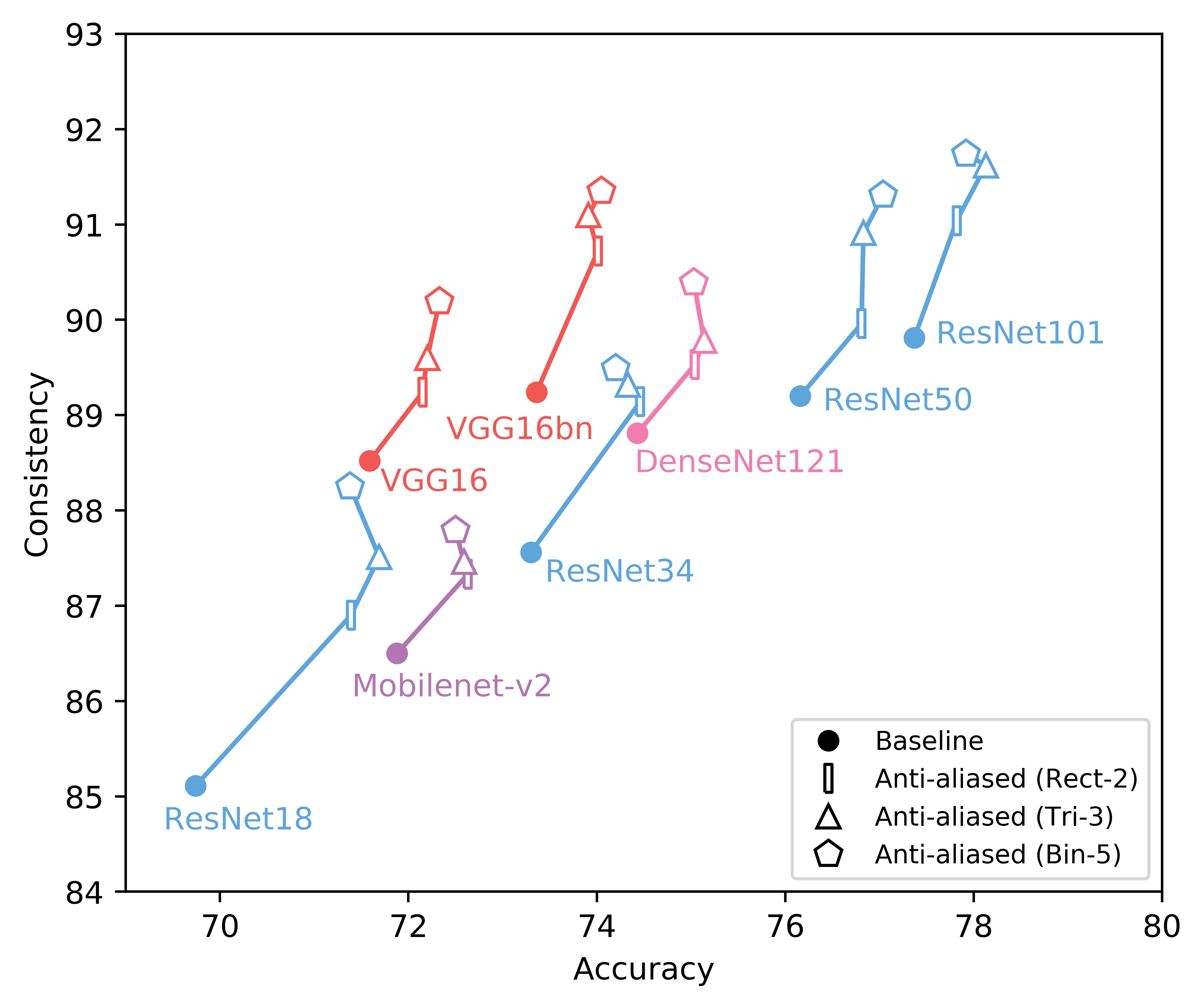
We show consistency (y-axis) vs accuracy(x-axis) for various networks. Up and to the right is good.
We italicize a variant if it is not on the Pareto front -- that is, it is strictly dominated in both aspects by another variant. We bold a variant if it is on the Pareto front. We bold highest values per column.
Achieving better consistency, while maintaining or improving accuracy, is an open problem. We invite you to participate!
Note that the current arxiv paper is slightly out of date; we will update soon.
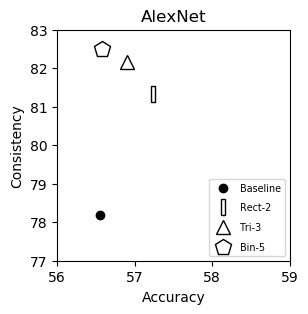
AlexNet (plot)
{kind=link}
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 56.55 | 78.18 |
| Rect-2 | 57.24 | 81.33 |
| Tri-3 | 56.90 | 82.15 |
| Bin-5 | 56.58 | 82.51 |
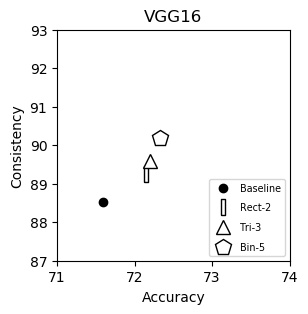
VGG16 (plot)
{kind=link}
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 71.59 | 88.52 |
| Rect-2 | 72.15 | 89.24 |
| Tri-3 | 72.20 | 89.60 |
| Bin-5 | 72.33 | 90.19 |
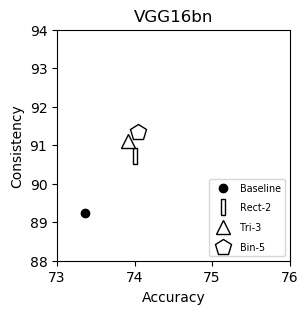
VGG16bn (plot)
{kind=link}
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 73.36 | 89.24 |
| Rect-2 | 74.01 | 90.72 |
| Tri-3 | 73.91 | 91.10 |
| Bin-5 | 74.05 | 91.35 |
ResNet18 (plot)
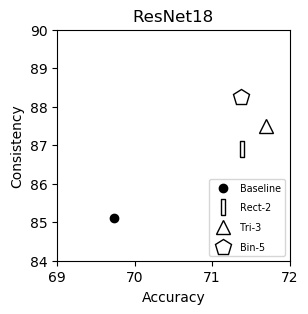{kind=link}
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 69.74 | 85.11 |
| Rect-2 | 71.39 | 86.90 |
| Tri-3 | 71.69 | 87.51 |
| Bin-5 | 71.38 | 88.25 |
ResNet34 (plot)
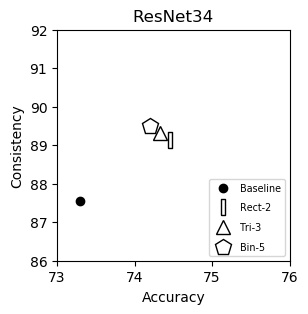{kind=link}
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 73.30 | 87.56 |
| Rect-2 | 74.46 | 89.14 |
| Tri-3 | 74.33 | 89.32 |
| Bin-5 | 74.20 | 89.49 |
ResNet50 (plot)
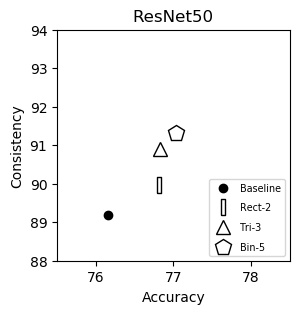{kind=link}
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 76.16 | 89.20 |
| Rect-2 | 76.81 | 89.96 |
| Tri-3 | 76.83 | 90.91 |
| Bin-5 | 77.04 | 91.31 |
DenseNet121 (plot)
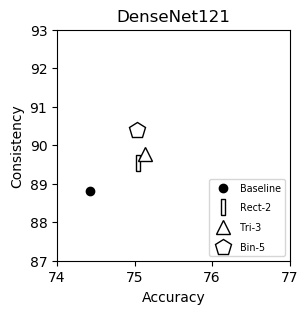{kind=link}
| Accuracy | Consistency | |
|---|---|---|
| Baseline | 74.43 | 88.81 |
| Rect-2 | 75.04 | 89.53 |
| Tri-3 | 75.14 | 89.78 |
| Bin-5 | 75.03 | 90.39 |
This repository is built off the PyTorch ImageNet training and torchvision models repositories.
If you find this useful for your research, please consider citing this bibtex. Please contact Richard Zhang <rizhang at adobe dot com> with any comments or feedback.