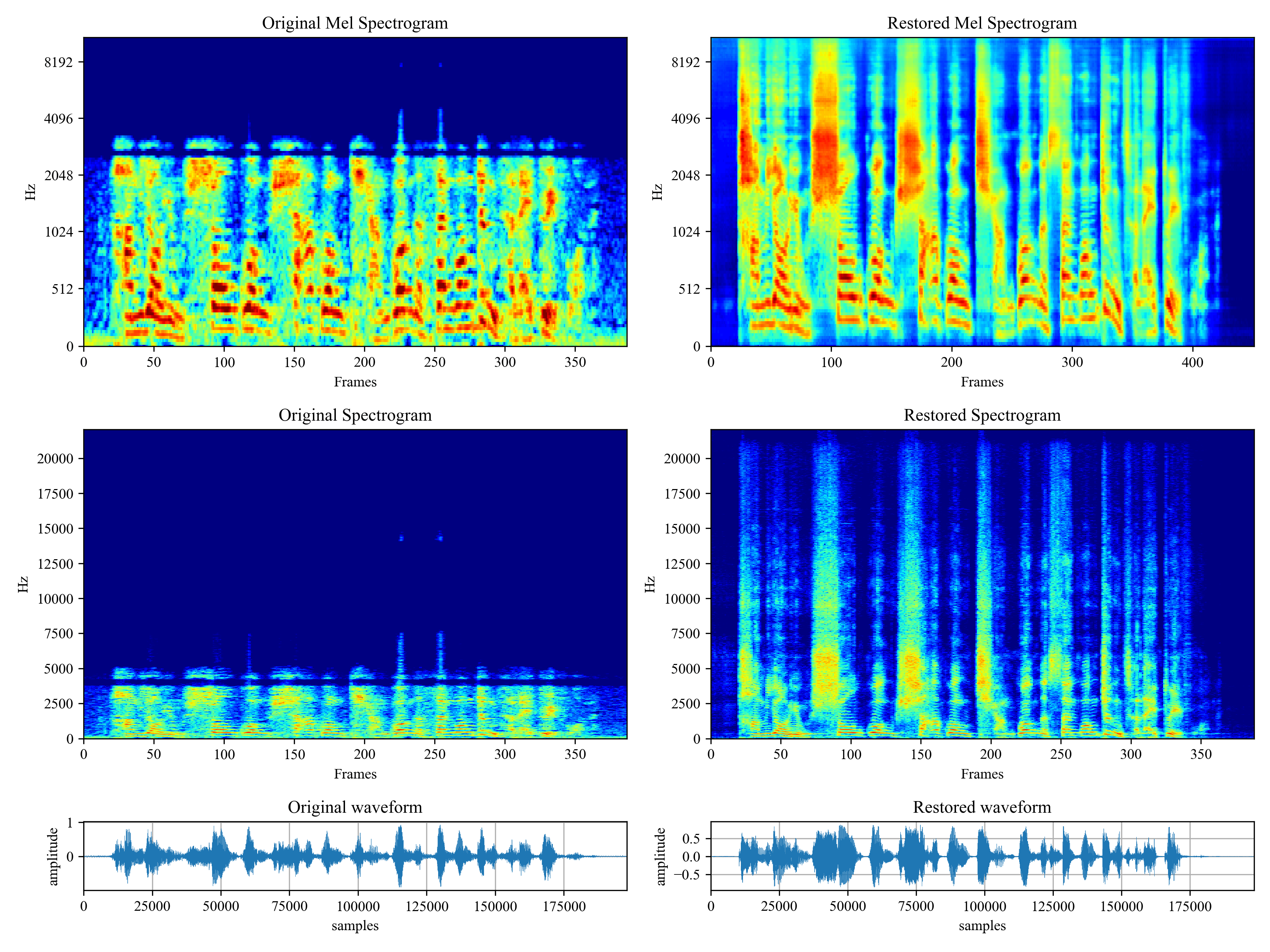
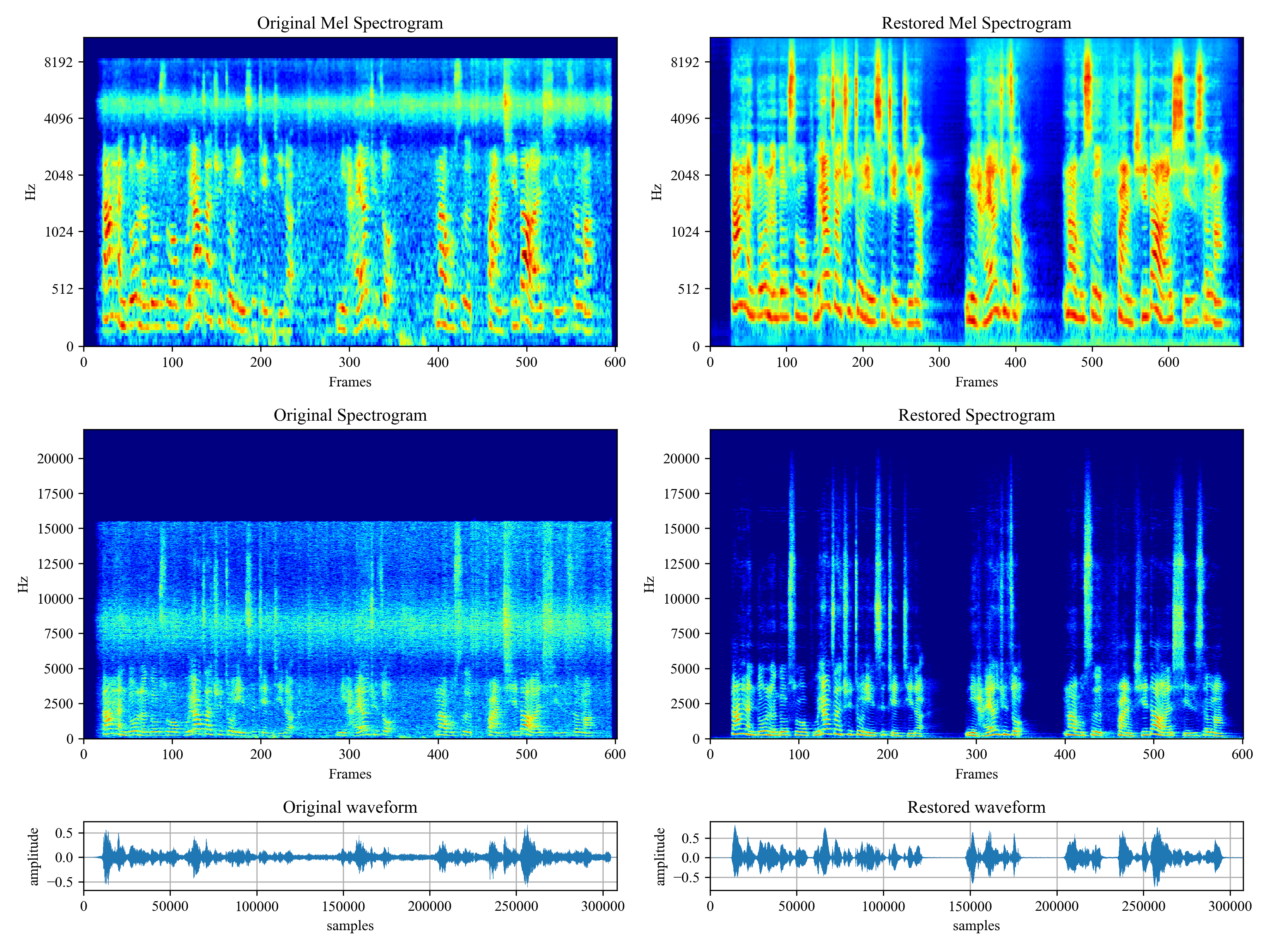
This package provides:
- A pretrained 44.1k universal speaker-independent neural vocoder.
- A pretrained Voicefixer, which is build based on neural vocoder.
Voicefixer aims at the restoration of human speech regardless how serious its degraded. It can handle noise, reveberation, low resolution (2kHz~44.1kHz) and clipping (0.1-1.0 threshold) effect within one model.
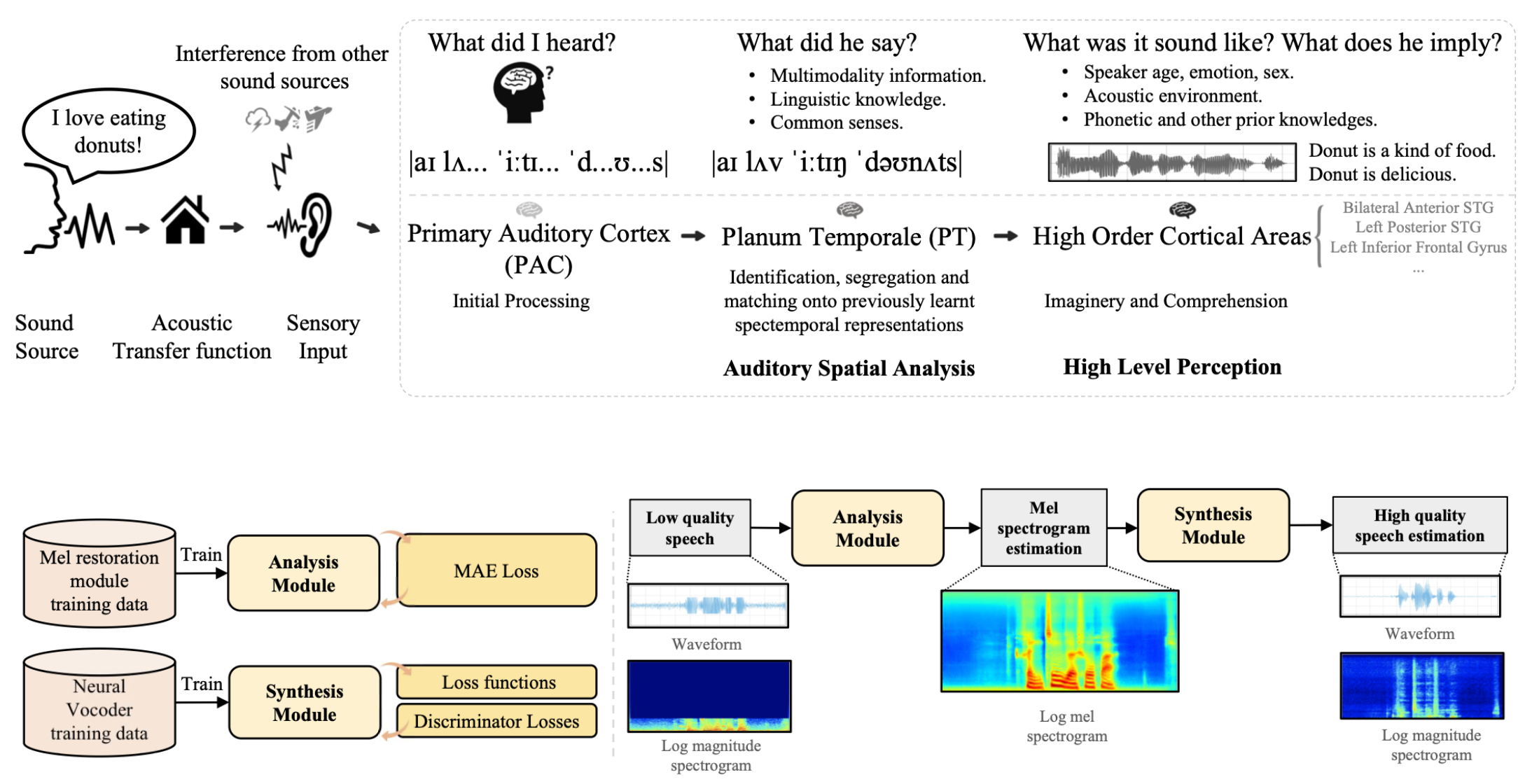
Please visit demo page to view what voicefixer can do.
# Will automatically download model parameters.
from voicefixer import VoiceFixer
from voicefixer import Vocoder
# Initialize model
voicefixer = VoiceFixer()
# Speech restoration
# Mode 0
voicefixer.restore(input="", # input wav file path
output="", # output wav file path
cuda=False, # whether to use gpu acceleration
mode = 0) # You can try out mode 0, 1, 2 to find out the best result
# Mode 1
voicefixer.restore(input="", # input wav file path
output="", # output wav file path
cuda=False, # whether to use gpu acceleration
mode = 1) # You can try out mode 0, 1, 2 to find out the best result
# Mode 2
voicefixer.restore(input="", # input wav file path
output="", # output wav file path
cuda=False, # whether to use gpu acceleration
mode = 2) # You can try out mode 0, 1, 2 to find out the best result
# Universal speaker independent vocoder
vocoder = Vocoder(sample_rate=44100) # Only 44100 sampling rate is supported.
# Convert mel spectrogram to waveform
wave = vocoder.forward(mel=mel_spec) # This forward function is used in the following oracle function.
# Test vocoder using the mel spectrogram of 'fpath', save output to file out_path
vocoder.oracle(fpath="", # input wav file path
out_path="") # output wav file path- How to use your own vocoder, like pre-trained HiFi-Gan?
First you need to write a following helper function with your model. Similar to the helper function in this repo: https://github.com/haoheliu/voicefixer/blob/main/voicefixer/vocoder/base.py#L35
def convert_mel_to_wav(mel):
"""
:param non normalized mel spectrogram: [batchsize, 1, t-steps, n_mel]
:return: [batchsize, 1, samples]
"""
return wavThen pass this function to voicefixer.restore, for example:
voicefixer.restore(input="", # input wav file path
output="", # output wav file path
cuda=False, # whether to use gpu acceleration
mode = 0,
your_vocoder_func = convert_mel_to_wav)
Note:
- For compatibility, your vocoder should working on 44.1kHz wave with mel frequency bins 128.
- The input mel spectrogram to the helper function should not be normalized by the width of each mel filter.
- Voicefixer training: https://github.com/haoheliu/voicefixer_main.git
- Demo page: https://haoheliu.github.io/demopage-voicefixer/
- If you found this repo helpful, please consider citing
@misc{liu2021voicefixer,
title={VoiceFixer: Toward General Speech Restoration With Neural Vocoder},
author={Haohe Liu and Qiuqiang Kong and Qiao Tian and Yan Zhao and DeLiang Wang and Chuanzeng Huang and Yuxuan Wang},
year={2021},
eprint={2109.13731},
archivePrefix={arXiv},
primaryClass={cs.SD}
}