This repository implements a proof of concept conversation orchestrator with a speech-language model (audio-in, text-out). We achieve state-of-the-art 350ms latency with Gazelle.
Current voice orchestrators focus on an end-to-end cascaded system: audio -> transcriber -> LLM -> TTS -> user. Transcription models have to be small, in order to be fast, but as a result are dumb, certainly dumber than a billion parameter LLM.
Tincans' Gazelle was the first open source model and system to implement a streaming joint speech-language approach.
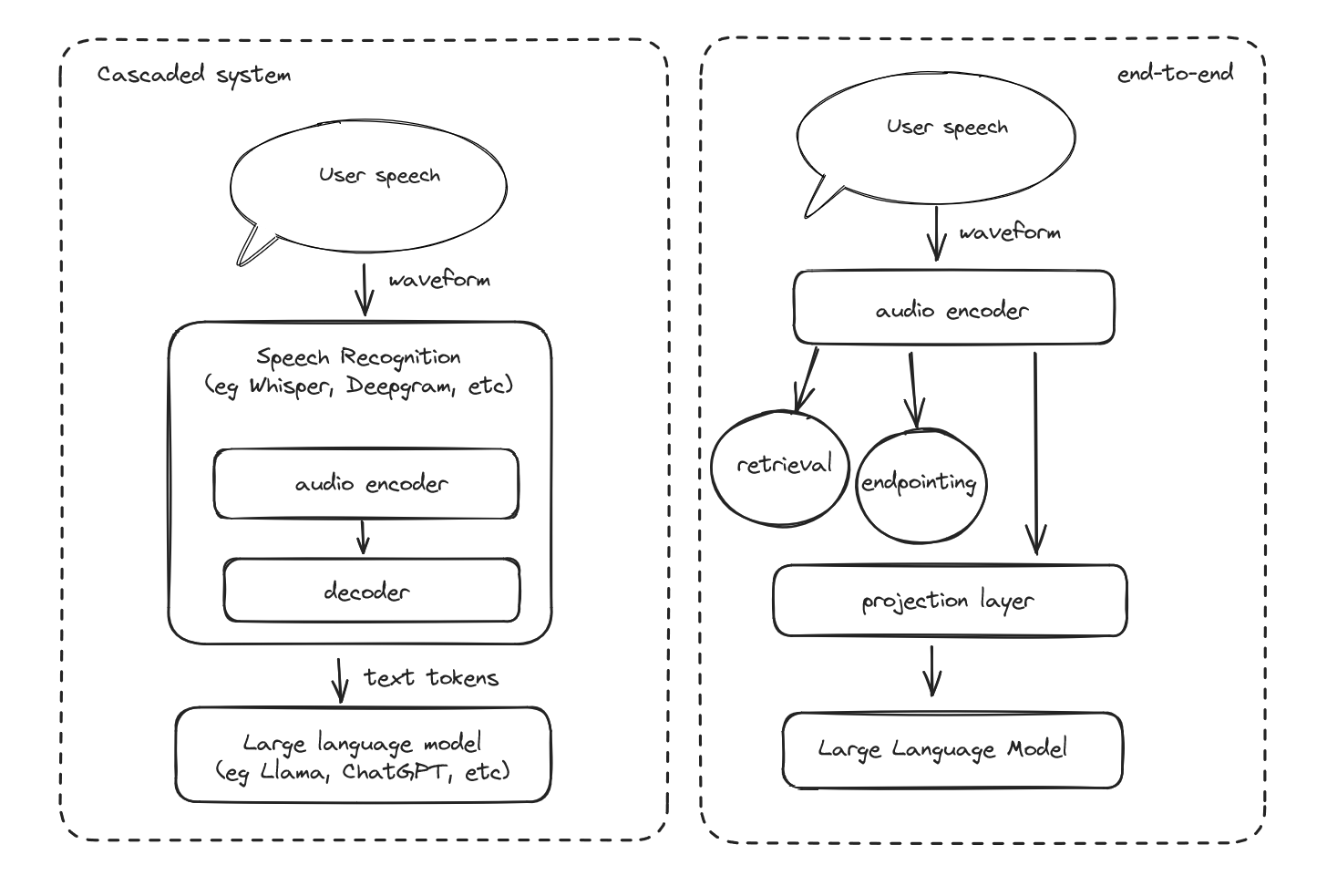
Existing cascaded pipelines are not easy to adapt to a joint speech-language system, which tend to rely on transcription for control flow. This code implements the absolute bare minimum to orchestrate conversation with a joint model. It was coarsely adapted from our internal production cascaded system, largely written in October-November 2023.
We offer this repo as a research artifact to the community and hope that it inspires better research and production directions.
We implement our service in Go. The core challenge is to handle state between the different components of the system concurrently and constantly pass messages around reliably and in low latency, and Go's channels are an excellent match for this. This implementation has extremely low memory and CPU overhead and would easily to scale to thousands of concurrent calls on commodity hardware.
We have a couple main components within the Orchestrator:
- Input: websocket reading b64 encoded audio from the frontend
- VAD / interruption: websocket to a server running Silero VAD.
- SLM: websocket to a server running the Speech Language model. We accumulate streamed tokens until it constitutes a sentence, then stream the completed sentences to the synthesizer.
- Synthesizer: given a stream of input text, stream corresponding audio out. We provide reference implementations for ElevenLabs, PlayHT, and XTTS, and it should be straightforward to implement additional providers.
- Output: websocket which incrementally streams audio back to the user.
Each component has an input and output channel, and we constantly stream messages from one component to the other. Our primary metric is first token latency, as measured by end of user speech to first byte received from TTS.
The frontend uses Taolun, a fork of Vocode's unmaintained React library. We use the same message passing format, but fixed some bugs, improved performance, and added support for business logic that's no longer relevant. Our inference engine is based on GPT-fast and about 50% faster than other opensource implementations.
This release includes some code which was incidentally necessary to work and also may be useful externally:
- PlayHT client built from their protos.
- wav file encoder.
- mulaw implementation, necessary for Twilio usage.
We use Hermit to manage dependencies.