#Novelweb-python-Django
首先来看看目标网站https://book.tianya.cn/
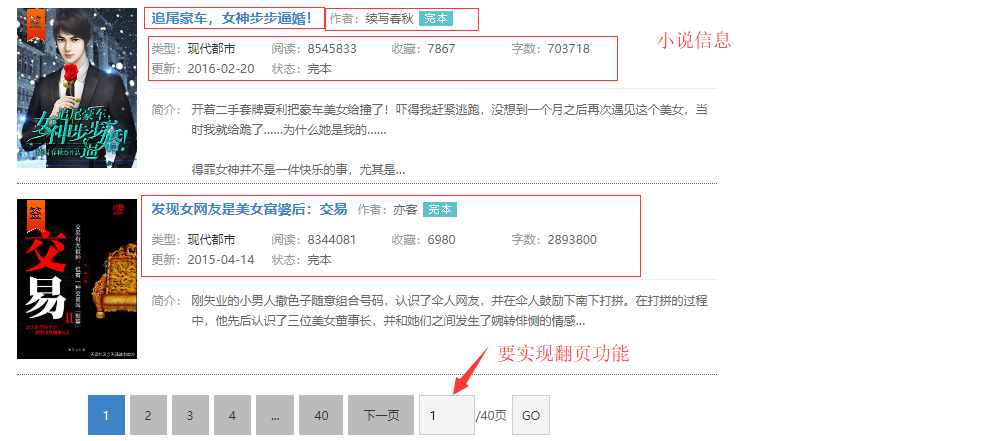
小说信息
小说目录

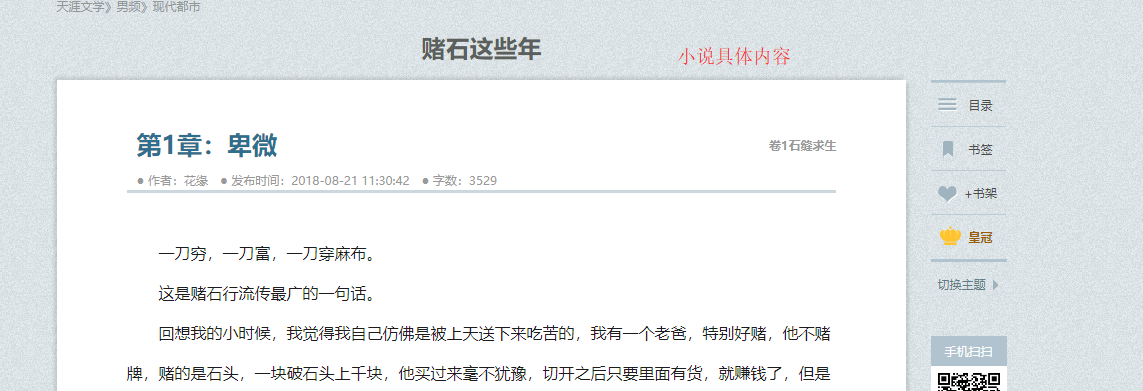
小说详情
框架:Django
数据库:MYSQL
自定义爬虫:装饰器,多线程,selenium,pymysql,pyquery库
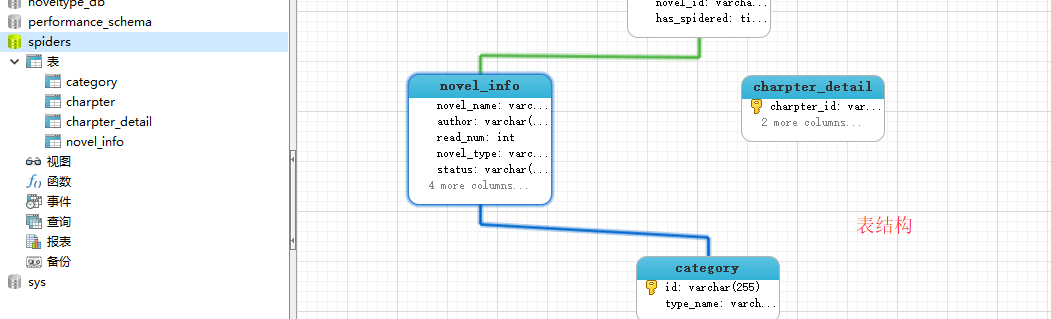
设计时,考虑到的一般是小说的分类,小说章节,小说具体内容,还有小说的分类。对应于Django的model层,有四种。
小说分类
class Category(models.Model):
id = models.CharField(primary_key=True, max_length=255)
type_name = models.CharField(max_length=255)
class Meta:
managed = False
db_table = 'category'小说章节(即目录)
class Charpter(models.Model):
charpter_id = models.CharField(primary_key=True, max_length=255)
charpter_name = models.CharField(max_length=255)
novel = models.ForeignKey('NovelInfo', models.DO_NOTHING)
class Meta:
managed = False
db_table = 'charpter'具体小说内容
class CharpterDetail(models.Model):
charpter_id = models.CharField(primary_key=True, max_length=255)
charpter_content = models.TextField()
charpter_name = models.CharField(max_length=255)
class Meta:
managed = False
db_table = 'charpter_detail'小说相关信息(小说名,作者,阅读数...)
class NovelInfo(models.Model):
novel_name = models.CharField(max_length=255)
author = models.CharField(max_length=255)
read_num = models.IntegerField()
novel_type = models.ForeignKey(Category, models.DO_NOTHING, db_column='novel_type')
status = models.CharField(max_length=255)
id = models.CharField(primary_key=True, max_length=255)
class Meta:
managed = False
db_table = 'novel_info'1.爬取小说相关信息,相关代码位于function/spider/spider_novel_info.py.(下面代码只是小部分代码)
根据目标网站的情况,需要实现翻页功能,根据selenium库的方法,根据情况具体编写的实现功能
def get_next_page(num):
url = 'https://book.tianya.cn/html2/allbooks-cat.aspx?cat_bigid=2&cat_id=25' #科幻小说6/5
browser.get(url)
try:
print('\n\n翻到第%d页' % num)
input = wait.until(EC.presence_of_element_located((By.CLASS_NAME, "page")))
input.clear()
input.send_keys(num)
input.send_keys(Keys.ESCAPE) # 输入回车键
time.sleep(8) #等待数据渲染完成
html = browser.page_source
return html
except TimeoutError as e:
print(e)2.爬取小说的章节信息,相关代码位于function/spider/spider_charpter_info.py.
为了提高爬取的速度,可以使用selenium的显示等待方式(以下是部分代码)
def click_href(url):
try:
browser.get(url)
wait = WebDriverWait(browser, 20)
# 显示等待,小说页面加载完成
content_click = wait.until(EC.element_to_be_clickable((By.CLASS_NAME,'directory'))).click()
# browser.find_element_by_link_text('目录').click()
time.sleep(4)
contents = wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'contents')))
html = browser.page_source
return html
except:
html = click_href(url)
return html3.爬取小说的具体章节,这是最难得一部分。相关代码位于function/spider/spider_charpter_content.py
由于数据太多,在爬取的过程中,由于网络不佳或其他原因使得一个页面总是无法加载出来,在用显示等待的过程中超时而抛出异常,导致整个程序无法运行,因此在有必要时跳过这个爬取,进行下一个页面的爬取。
解决方法:使用python的装饰器以及多进程来实现规定某函数的运行时间,超时后程序也不会抛出异常,并且可以请求下一个页面。
#装饰器,给get_one_cahrpter_content(url)函数新增功能
def time_limited_pri(time_limited):
def wrapper(func): #接收的参数是函数
def __wrapper(params):
class TimeLimited(Thread): #class中的两个函数是必须的
def __init__(self):
Thread.__init__(self)
def run(self):
func(params)
t = TimeLimited()
t.setDaemon(True) #这个用户线程必须设置在start()前面
t.start()
t.join(timeout=time_limited)
if t.is_alive():
raise Exception('连接超时')
return __wrapper
return wrapper
#获取免费章节的文本内容
@time_limited_pri(15)
def get_one_charpter_content(url):
try:
browser.get(url)
wait = WebDriverWait(browser, 20)
contents = wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'bd')))
# time.sleep(2)
html = browser.page_source
doc = pq(html)
content = doc('.bd').html().replace('<br xmlns="http://www.w3.org/1999/xhtml"/>', '\n\n')
# data['novel_id'] = doc('#main').attr('bookid')
# print(data['novel_id'])
return content
except:
content = get_one_charpter_content(url)
return content4.我总共爬取了8k+本小说,但是只要想爬,就能爬取天涯网的所有免费小说章节。
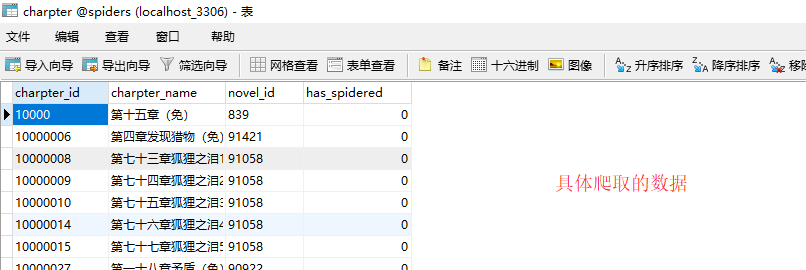
1.数据库的表结构以及爬取的数据图片。
表结构,用外键关联
 其中一张表的信息
其中一张表的信息
由于使用MYSQL的不是Django自带的数据库,那么就要使用pymysql来将爬取的数据插入到数据库中。(下面的代码是如何连接到MYSQL数据的,在test文件中也有相关代码)
import pymysql
#连接到spiders数据库
con = pymysql.connect(host='localhost',
user='xxxx',
password='xxxxx',
port=xxx,db='xxxx'
)
cursor = con.cursor()
#查询语句,查询novel的id(查询指定字段)
sql = 'SELECT * FROM charpter'
cursor.execute(sql) #result是共有多少条结果
result = cursor.fetchall() #数据类型是元组,可迭代类型数据
print(result)2.更新功能,由于有的小说处于连载中,或者过段时间会下架。因此需要经常更新。下面的代码只是一小部分,具体代码位于NovelWeb-python-Django/function/update。
大致思路是,检查这本小说是否需要更新,然后根据在表中的字段,以及has_spiderde字段来什么时候确定爬取的数据,章节名对应的数据是否爬取。如果有对比数据库后发现不存在数据,则删除数据.
#比较两者,更新字段
def compare_two_list(charpter,charpter_detail):
for charpter_id in charpter:
if charpter_id in charpter_detail:
try:
sql = "UPDATE charpter SET has_spidered=%s WHERE charpter_id=%s"
cursor.execute(sql,(1,charpter_id))
con.commit()
print(charpter_id+'的has_spidered章节已经爬取')
except Exception as e:
print('更新失败',e)
con.rollback()
else:
try:
sql = "UPDATE charpter SET has_spidered=%s WHERE charpter_id=%s"
cursor.execute(sql, (0, charpter_id))
con.commit()
print(charpter_id + '的has_spidered章节没有爬取')
except Exception as e:
print('更新失败', e)
con.rollback()在完善Django的其他部分后,也可以加入一些搜索功能,分页功能,第三方登录功能后。这个是属于Django的方面,并不难,稍微研究一下就知道了。最后网站就做好了。
小说首页
随便点击一本小说
小说详情页面
