
🚖 NYC Trips | End-To-End Data Engineering Project
Documentation 🌪️ Get a 5 min overview 🌊 Play with live tool 🔥 Trello Board



Integration , transformation and Modeling with Python
Build a real-time pipeline to transform data using Python
Run, monitor, and orchestrate the data pipeline to a Big Query solution
1️⃣ 🏗️
Languages: Python, SQL
Tools: Google Cloud Platform, Google Storage, Compute Instance, BigQuery, Mage AI
| Easy developer experience This project leverages cloud infrastructure to handle and analyze large volumes of data, utilizing services like Google BigQuery. With a VM-hosted approach, we streamline the efficient execution of data engineering operations at scale. Language of choice Coded in Python to Data Modeling, Data Wrangling & Data Cleaning; SQL for ultimate flexibility at data analysis. Engineering best practices built-in Each step in the pipeline is a standalone file containing modular code that’s reusable and testable with data validations. |
 |
↓
2️⃣ 🔮
TLC Official Data: The New York City Taxi and Limousine Commission (TLC), created in 1971, is the agency responsible for licensing and regulating New York City's Medallion (Yellow) taxi cabs, for-hire vehicles (community-based liveries, black cars and luxury limousines), commuter vans, and paratransit vehicles.
TLC Trip Record Data Yellow and green taxi trip records include fields capturing pick-up and drop-off dates/times, pick-up and drop-off locations, trip distances, itemized fares, rate types, payment types, and driver-reported passenger counts.
More info about dataset can be found here:
Website - https://www.nyc.gov/site/tlc/about/tlc-trip-record-data.page
Data Dictionary - https://www.nyc.gov/assets/tlc/downloads/pdf/data_dictionary_trip_records_yellow.pdf
With instant feedback from the code each time you run it.
| Interactive code Immediately see results from the code’s output with an interactive notebook UI. High-quality Data Each block of code pipeline produces data that can be versioned, partitioned, and cataloged for future use. Collaborate on cloud Develop collaboratively on cloud resources, version control with Git, and test pipelines without waiting for an available shared staging environment. |
 |
↓
3️⃣ 🚀
With the Data Export feature, our dataset goes from Mage to GCP through the Data Exporter feature.
Mage makes it easy for a single developer or small team to scale up and manage thousands of pipelines.
| Fast deploy Mage deployed my data to GCP with only 2 commands using. Scaling made simple Large datasets directly in the data warehouse. Observability Operationalized the pipeline with built-in monitoring, alerting, and observability through an intuitive UI. |
 |
Mage is an open-source data pipeline tool for transforming and integrating data.
The actual project was used the Mage install using pip at the provided VM delivered by GCP.
pip install mage-aiLooking for help? The fastest way to get started is by checking out our documentation here.
Looking for quick examples? Open a demo project right in your browser or check out our guides.
Build & run of pipelines. Demo app.
The live demo is public to everyone.
| 🎶 | Modeling | Manage of data behavior. |
| 📓 | Notebook | Interactive Python code for data pipeline. |
| 🏗️ | Compute Engine | Synchronizing GCP VM to use Mage AI for ETL. |
| 🚰 | Streaming pipelines | Ingest and transform real-time data. |
| ❎ | Data project | Build, run, and manage the data model with SQL at BigQuery. |
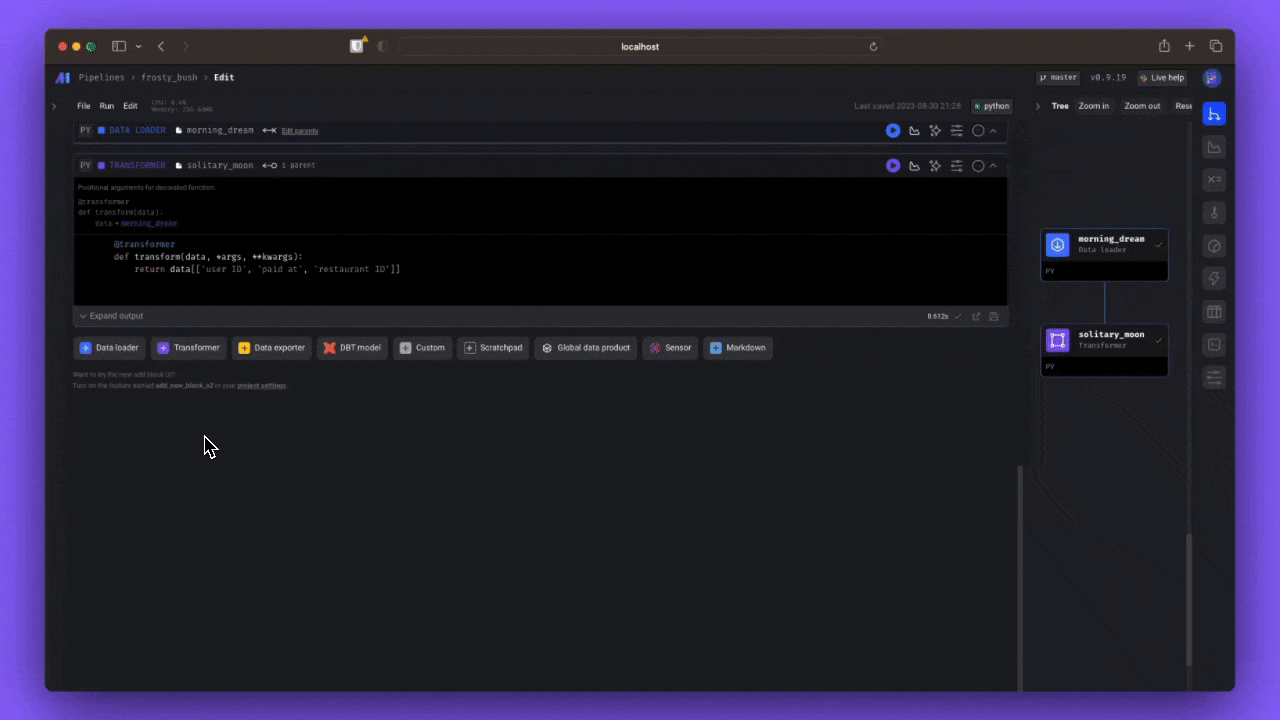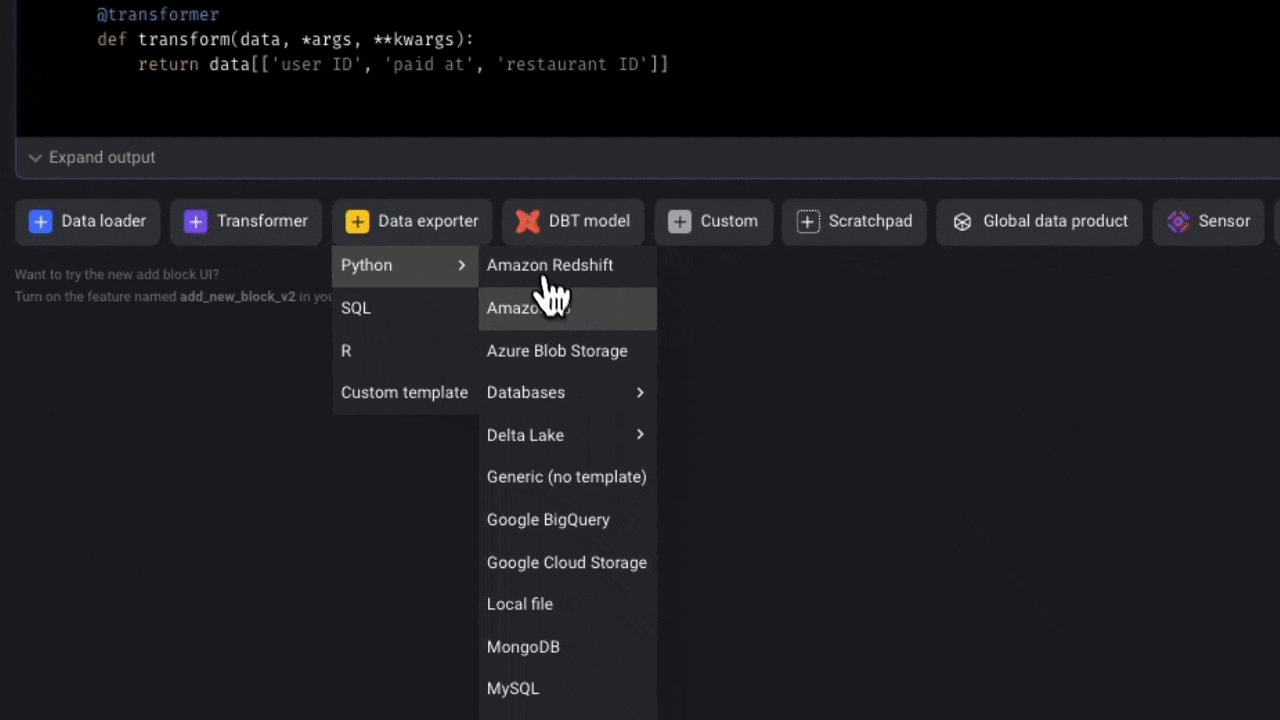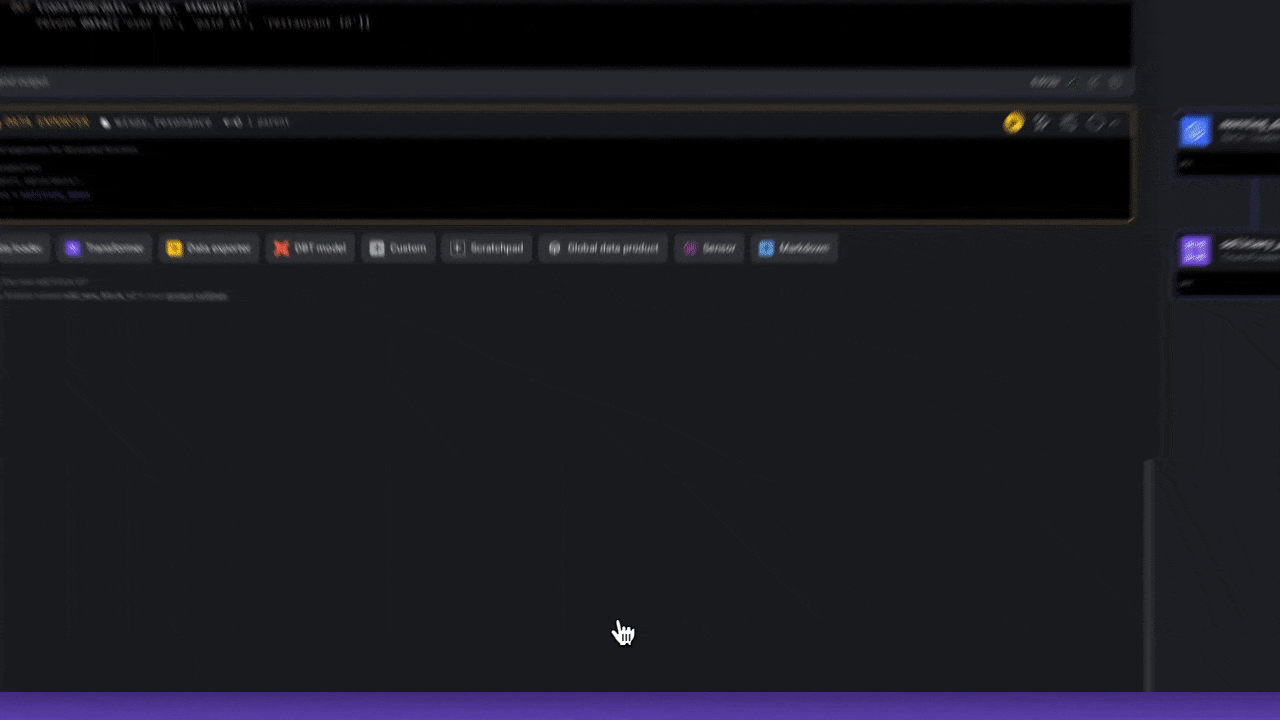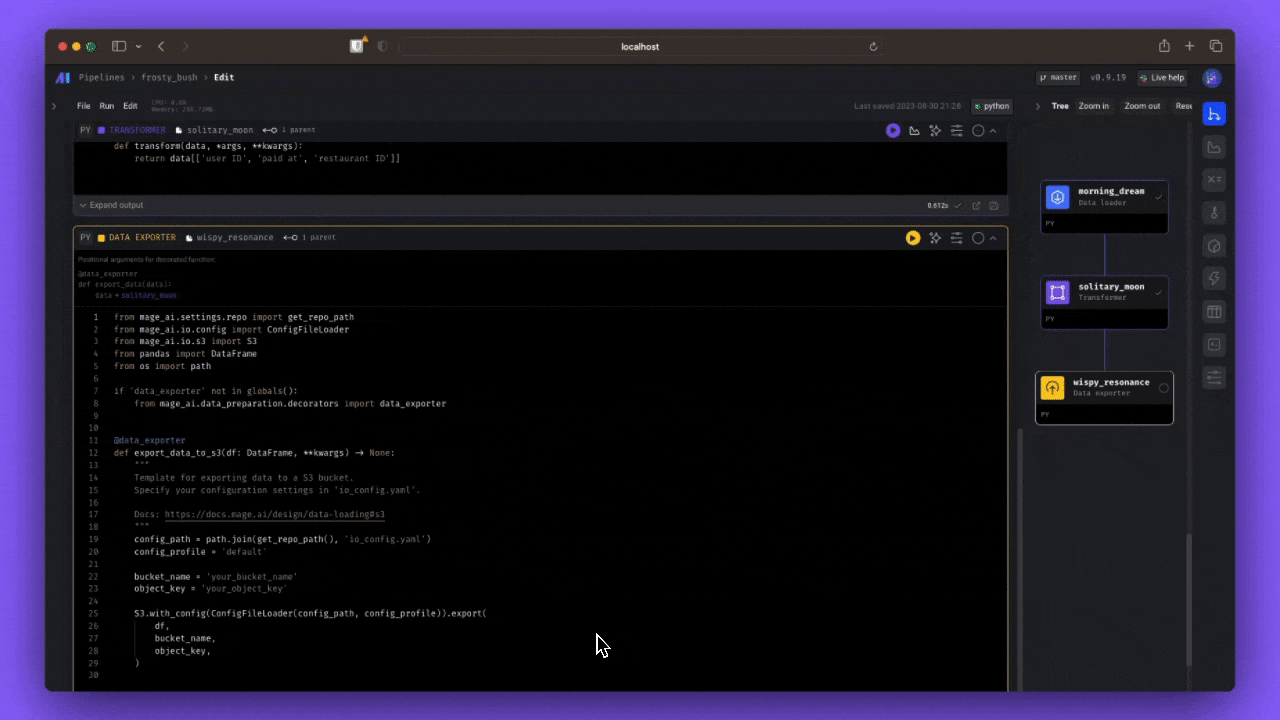
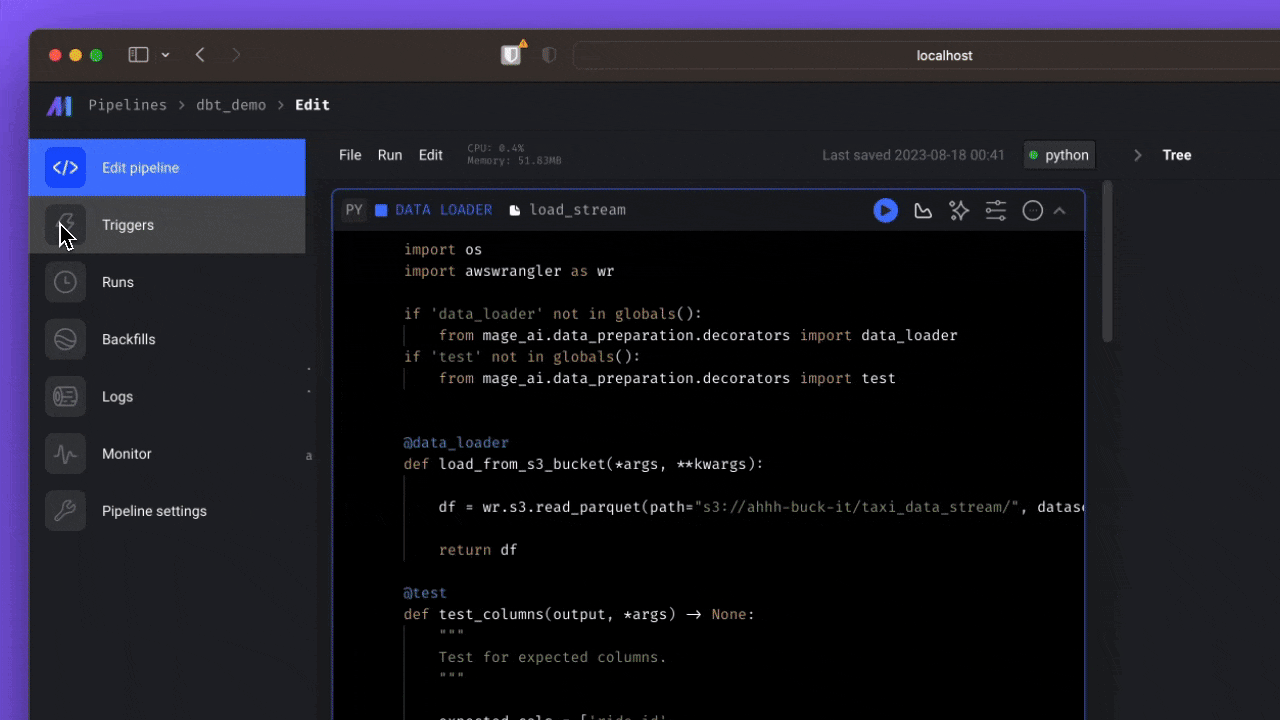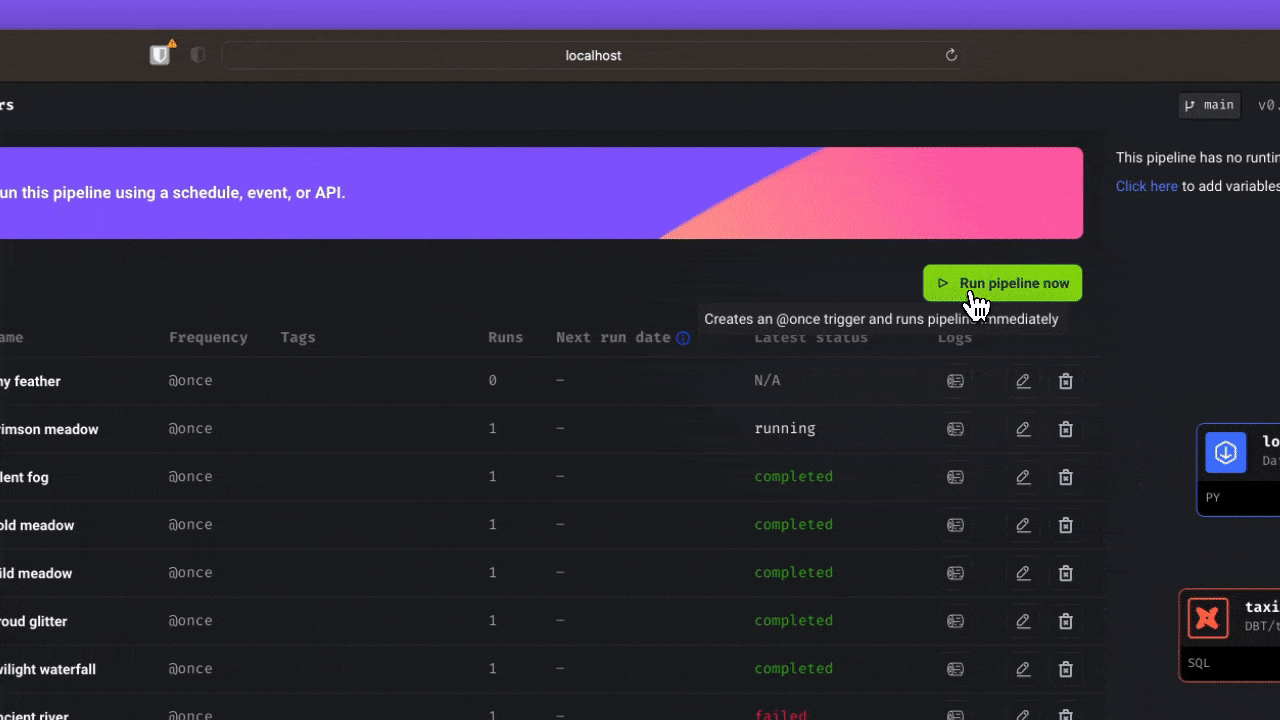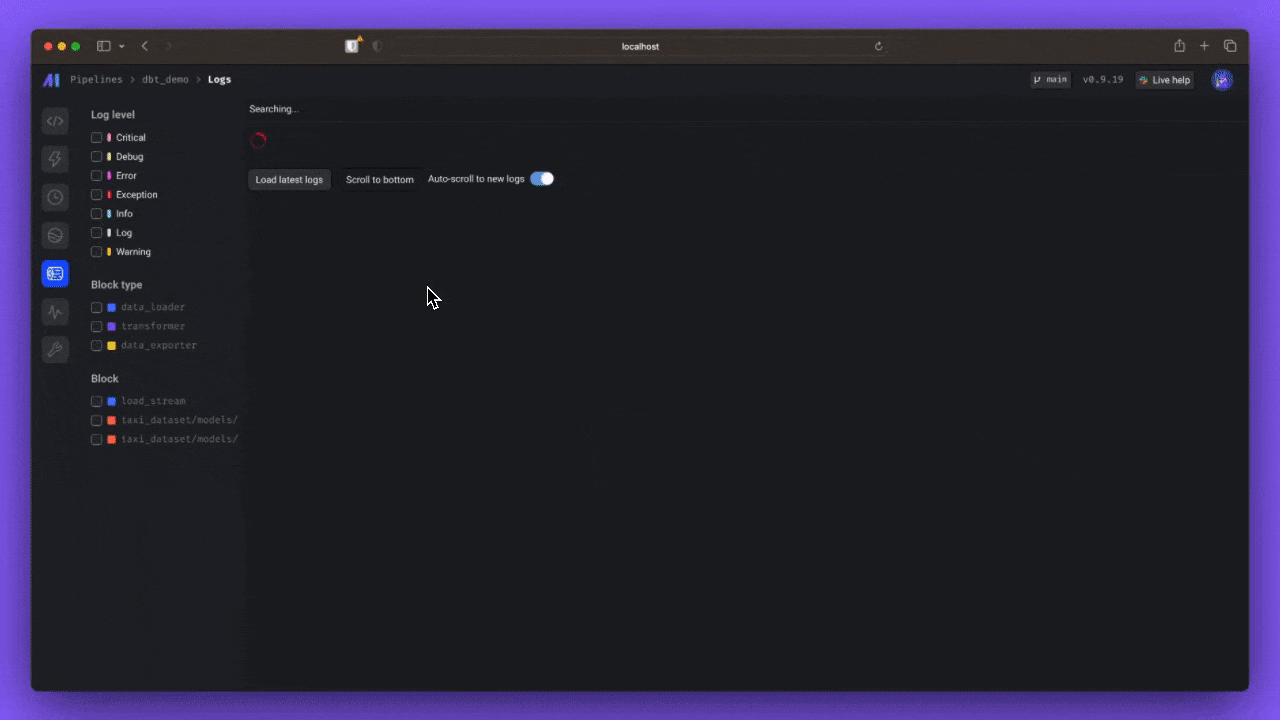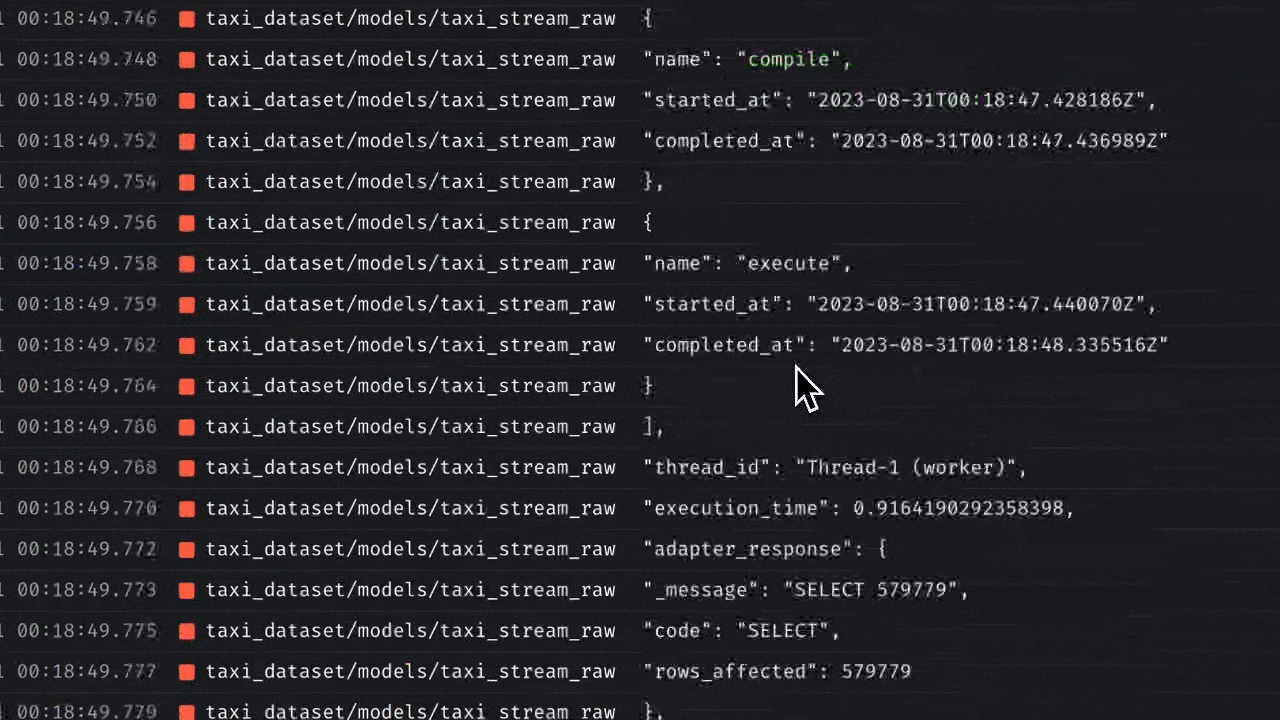
A sample data pipeline defined across 3 files ➝
- Load data ➝
import io import pandas as pd import requests if 'data_loader' not in globals(): from mage_ai.data_preparation.decorators import data_loader if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @data_loader def load_data_from_api(*args, **kwargs): """ Template for loading data from API """ url = 'https://storage.googleapis.com/trips-data-project-borges/yellow_tripdata_2024-01.csv' response = requests.get(url) return pd.read_csv(io.StringIO(response.text), sep=',') @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
- Transform data ➝
import pandas as pd if 'transformer' not in globals(): from mage_ai.data_preparation.decorators import transformer if 'test' not in globals(): from mage_ai.data_preparation.decorators import test @transformer def transform(df, *args, **kwargs): """ Template code for a transformer block. Add more parameters to this function if this block has multiple parent blocks. There should be one parameter for each output variable from each parent block. Args: data: The output from the upstream parent block args: The output from any additional upstream blocks (if applicable) Returns: Anything (e.g. data frame, dictionary, array, int, str, etc.) """ # Specify your transformation logic here df = df.drop_duplicates().reset_index(drop=True) df['trip_id'] = df.index df['tpep_pickup_datetime'] = pd.to_datetime(df['tpep_pickup_datetime']) df['tpep_dropoff_datetime'] = pd.to_datetime(df['tpep_dropoff_datetime']) datetime_dim = df[['tpep_pickup_datetime','tpep_dropoff_datetime']].reset_index(drop=True) datetime_dim['tpep_pickup_datetime'] = datetime_dim['tpep_pickup_datetime'] datetime_dim['pick_hour'] = datetime_dim['tpep_pickup_datetime'].dt.hour datetime_dim['pick_day'] = datetime_dim['tpep_pickup_datetime'].dt.day datetime_dim['pick_month'] = datetime_dim['tpep_pickup_datetime'].dt.month datetime_dim['pick_year'] = datetime_dim['tpep_pickup_datetime'].dt.year datetime_dim['pick_weekday'] = datetime_dim['tpep_pickup_datetime'].dt.weekday datetime_dim['tpep_dropoff_datetime'] = datetime_dim['tpep_dropoff_datetime'] datetime_dim['drop_hour'] = datetime_dim['tpep_dropoff_datetime'].dt.hour datetime_dim['drop_day'] = datetime_dim['tpep_dropoff_datetime'].dt.day datetime_dim['drop_month'] = datetime_dim['tpep_dropoff_datetime'].dt.month datetime_dim['drop_year'] = datetime_dim['tpep_dropoff_datetime'].dt.year datetime_dim['drop_weekday'] = datetime_dim['tpep_dropoff_datetime'].dt.weekday datetime_dim['datetime_id'] = datetime_dim.index datetime_dim = datetime_dim[['datetime_id', 'tpep_pickup_datetime', 'pick_hour', 'pick_day', 'pick_month', 'pick_year', 'pick_weekday', 'tpep_dropoff_datetime', 'drop_hour', 'drop_day', 'drop_month', 'drop_year', 'drop_weekday']] passenger_count_dim = df[['passenger_count']].reset_index(drop=True) passenger_count_dim['passenger_count_id'] = passenger_count_dim.index passenger_count_dim = passenger_count_dim[['passenger_count_id','passenger_count']] trip_distance_dim = df[['trip_distance']].reset_index(drop=True) trip_distance_dim['trip_distance_id'] = trip_distance_dim.index trip_distance_dim = trip_distance_dim[['trip_distance_id','trip_distance']] rate_code_type = { 1:"Standard rate", 2:"JFK", 3:"Newark", 4:"Nassau or Westchester", 5:"Negotiated fare", 6:"Group ride" } rate_code_dim = df[['RatecodeID']].reset_index(drop=True) rate_code_dim['rate_code_id'] = rate_code_dim.index rate_code_dim['rate_code_name'] = rate_code_dim['RatecodeID'].map(rate_code_type) rate_code_dim = rate_code_dim[['rate_code_id','RatecodeID','rate_code_name']] pickup_location_dim = df[['PULocationID']].reset_index(drop=True) pickup_location_dim['pickup_location_id'] = pickup_location_dim.index dropoff_location_dim = df[['DOLocationID']].reset_index(drop=True) dropoff_location_dim['dropoff_location_id'] = dropoff_location_dim.index payment_type_name = { 1:"Credit card", 2:"Cash", 3:"No charge", 4:"Dispute", 5:"Unknown", 6:"Voided trip" } payment_type_dim = df[['payment_type']].reset_index(drop=True) payment_type_dim['payment_type_id'] = payment_type_dim.index payment_type_dim['payment_type_name'] = payment_type_dim['payment_type'].map(payment_type_name) payment_type_dim = payment_type_dim[['payment_type_id','payment_type','payment_type_name']] fact_table = df.merge(passenger_count_dim, left_on='trip_id', right_on='passenger_count_id') \ .merge(trip_distance_dim, left_on='trip_id', right_on='trip_distance_id') \ .merge(rate_code_dim, left_on='trip_id', right_on='rate_code_id') \ .merge(pickup_location_dim, left_on='trip_id', right_on='pickup_location_id') \ .merge(dropoff_location_dim, left_on='trip_id', right_on='dropoff_location_id')\ .merge(datetime_dim, left_on='trip_id', right_on='datetime_id') \ .merge(payment_type_dim, left_on='trip_id', right_on='payment_type_id') \ [['trip_id','VendorID', 'datetime_id', 'passenger_count_id', 'trip_distance_id', 'rate_code_id', 'store_and_fwd_flag', 'pickup_location_id', 'dropoff_location_id', 'payment_type_id', 'fare_amount', 'extra', 'mta_tax', 'tip_amount', 'tolls_amount', 'improvement_surcharge', 'total_amount']] return { 'datetime_dim': datetime_dim.to_dict(orient='dict'), 'passenger_count_dim': passenger_count_dim.to_dict(orient='dict'), 'trip_distance_dim': trip_distance_dim.to_dict(orient='dict'), 'rate_code_dim': rate_code_dim.to_dict(orient='dict'), 'pickup_location_dim': pickup_location_dim.to_dict(orient='dict'), 'dropoff_location_dim': dropoff_location_dim.to_dict(orient='dict'), 'payment_type_dim': payment_type_dim.to_dict(orient='dict'), 'fact_table': fact_table.to_dict(orient='dict') } print(fact_table) return "success" @test def test_output(output, *args) -> None: """ Template code for testing the output of the block. """ assert output is not None, 'The output is undefined'
- Export data ➝
from mage_ai.data_preparation.repo_manager import get_repo_path from mage_ai.io.bigquery import BigQuery from mage_ai.io.config import ConfigFileLoader from pandas import DataFrame from os import path if 'data_exporter' not in globals(): from mage_ai.data_preparation.decorators import data_exporter @data_exporter def export_data_to_big_query(data, **kwargs) -> None: """ Template for exporting data to a BigQuery warehouse. Specify your configuration settings in 'io_config.yaml'. Docs: https://docs.mage.ai/design/data-loading#bigquery """ config_path = path.join(get_repo_path(), 'io_config.yaml') config_profile = 'default' for key, value in data.items(): table_id = 'project-trips-422012.trips_de_project.{}'.format(key) BigQuery.with_config(ConfigFileLoader(config_path, config_profile)).export( DataFrame(value), table_id, if_exists='replace', # Specify resolution policy if table name already exists )
A data pipeline UI sample ➝
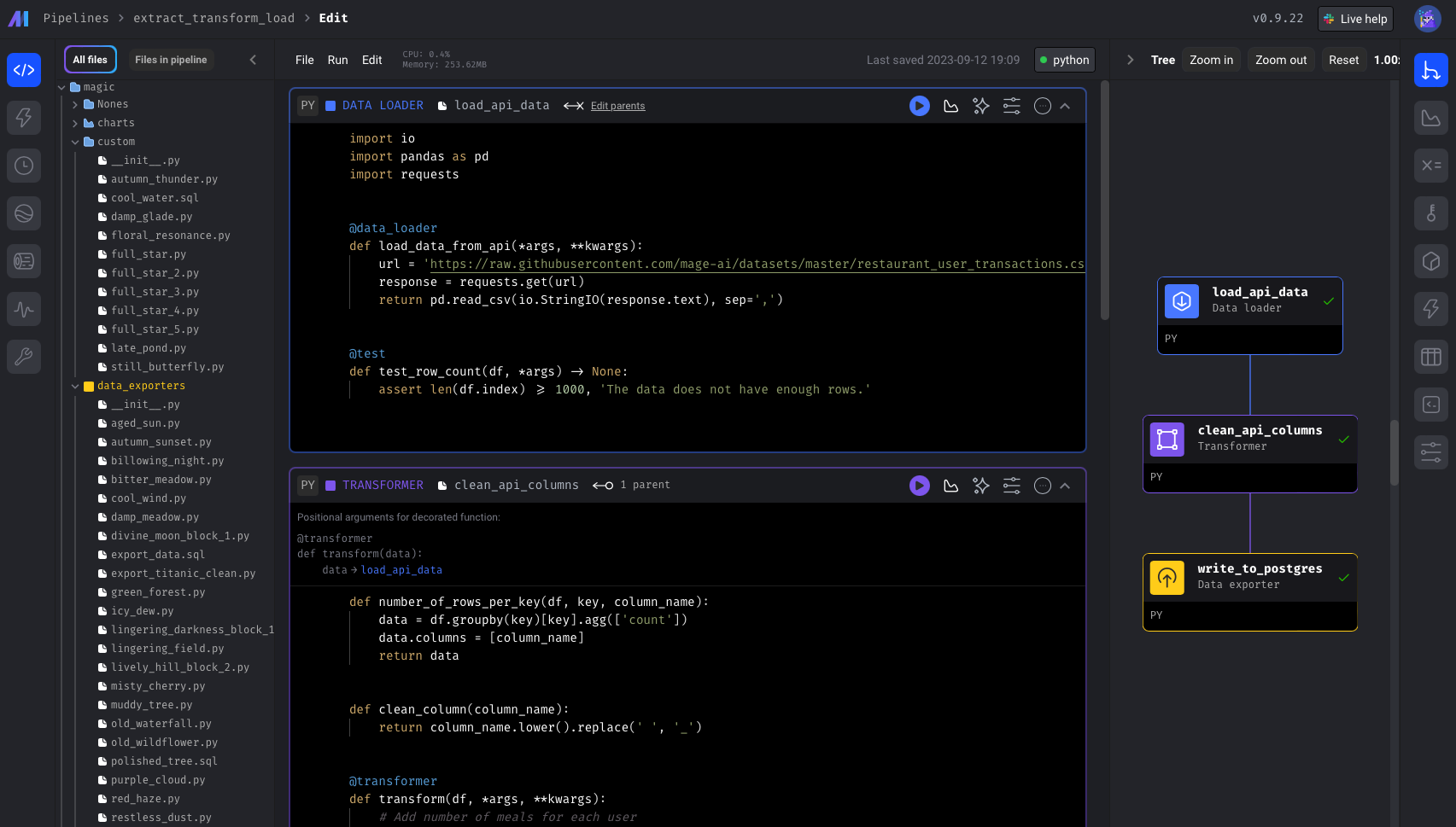
🏔️ Data storage
In GCP's BigQuery ecosystem, the Data Exporter boasts a sophisticated codebase designed to seamlessly interact with the API and securely handle credential keys. This robust engineering ensures a scalable and resilient data solution, capable of meeting the demands of modern data-intensive applications.
| 💻 | Data storage | Data solution in cloud. |
These are the fundamental concepts that Mage uses to operate.
| Project | Like a repository on GitHub; this is where you write all your code. |
| Pipeline | Contains references to all the blocks of code you want to run, charts for visualizing data, and organizes the dependency between each block of code. |
| Block | A file with code that can be executed independently or within a pipeline. |
| Data product | Every block produces data after it's been executed. These are called data products in Mage. |
| Trigger | A set of instructions that determine when or how a pipeline should run. |
| Run | Stores information about when it was started, its status, when it was completed, any runtime variables used in the execution of the pipeline or block, etc. |
Given recent fluctuations in Mage, I made the decision to migrate the final solution to Colab > Cloud. On an interim basis, data storage is hosted in a Cloud environment, implemented through a different Jupyter. Simpler. However, following the same logic as the Trips Data Engineering Project.
This new system will provide a temporary answer to our solution. A database in the cloud, allowing SQL analysis in a versatile and, in some ways, faster way for the short term. Additionally, it integrates seamlessly with tools like Spreadsheets, Looker, and other resources, providing a more fluid and efficient experience for all users.
To access the Python code that performs this temporary solution, simply click on the link:
Check out the contributing guide to set up your development environment and start building.
Wow! It's a lot of info, huh?.
🧙♂️🧙 Conclusion
The project aims to perform an E2E Data Engineering project. Tools and technologies includes GCP Storage, Python, Compute Instance, Mage Data Pipeline Tool, BigQuery, and scalable with Looker.
The task involves building an automated process to ingest data on-demand (with .parquets of TLC Database), representing trips by different vehicles with city, origin, and destination information. This automation enables continuous analysis of travel patterns, demand trends, operational efficiency, and other key metrics, providing valuable insights for route optimization, resource allocation, and strategic decisions.
| GitHub |
