Releases: wanghenshui/cppweeklynews
C++ 中文周刊 2024-08-31 第167期
本期文章由 HNY 赞助
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-08-21 第268期
文章
C++20 Modules 在阿里云的大规模应用
看一乐
MySQL 编译(打包
看一乐 感谢恒星投稿
Visualizing boost::unordered_map in GDB, with pretty-printer customization points
给boost unordered实现gdb pretty print
gdb使用pretty print很简单
第一步
(gdb) set print pretty on第二步,如果你的脚本在二进制的section中
(gdb) add-auto-load-safe-path path/to/executable如果没有,有脚本,可以加载脚本
(gdb) source path/to/boost/libs/unordered/extra/boost_unordered_printers.py其实脚本内容和放进二进制section内容是一样的,怎么放进二进制?可以学习这个 https://github.com/boostorg/outcome/blob/master/include/boost/outcome/outcome_gdb.h
我相信大部分读者是第一次知道gdb printer可以放到二进制里的
接下来是如何实现gdb printer
很简单,接口就这样
class BoostUnorderedFcaPrinter:
def __init__(self, val):
self.val = val
def to_string(self):
return f"This is a {self.val.type}"目标,实现to_string
注册也非常简单
def boost_unordered_build_pretty_printer():
pp = gdb.printing.RegexpCollectionPrettyPrinter("boost_unordered")
add_template_printer = lambda name, printer: pp.add_printer(name, f"^{name}<.*>$", printer)
add_template_printer("boost::unordered::unordered_map", BoostUnorderedFcaPrinter)
add_template_printer("boost::unordered::unordered_multimap", BoostUnorderedFcaPrinter)
add_template_printer("boost::unordered::unordered_set", BoostUnorderedFcaPrinter)
add_template_printer("boost::unordered::unordered_multiset", BoostUnorderedFcaPrinter)
return pp
gdb.printing.register_pretty_printer(gdb.current_objfile(), boost_unordered_build_pretty_printer())继续,咱们展开成员
def maybe_unwrap_foa_element(e):
element_type = "boost::unordered::detail::foa::element_type<"
if f"{e.type.strip_typedefs()}".startswith(element_type):
return e["p"]
else:
return e简单吧,现在你学会了gdb.Value.type.strip_typedefs
咱们进化一下
class BoostUnorderedFcaPrinter:
def __init__(self, val):
self.val = val
self.name = f"{self.val.type.strip_typedefs()}".split("<")[0]
self.name = self.name.replace("boost::unordered::", "boost::")
self.is_map = self.name.endswith("map")
def to_string(self):
size = self.val["table_"]["size_"]
return f"{self.name} with {size} elements"这样打印
(gdb) print my_unordered_map
$1 = boost::unordered_map with 3 elements
(gdb) print my_unordered_multiset
$2 = boost::unordered_multiset with 5 elements考虑遍历成员
def display_hint(self):
return "map"
def children(self):
def generator():
# ...
while condition:
value = # ...
if self.is_map:
first = value["first"]
second = value["second"]
yield "", first
yield "", second
else:
yield "", count
yield "", value
return generator()后面就不展开了
gdb python的玩法还是非常多的
PS: 吴乎提问: 放进二进制section这个,strip时不知道是跟着debug符号走,还是跟着binary走
笔者查了一下,使用的section debug_gdb_scripts也是debug symbol,strip会被删,
这种建议先strip后objcopy把debug_gdb_scripts搞回来 详情点击这个SO
gdb section可以看这里
SIMD Matters
图形生成算法使用simd性能提升显著。代码就不贴了
Honey, I shrunk {fmt}: bringing binary size to 14k and ditching the C++ runtime
介绍了fmtlib在减小二进制上的探索,比如查表优化
auto do_count_digits(uint32_t n) -> int {
// An optimization by Kendall Willets from https://bit.ly/3uOIQrB.
// This increments the upper 32 bits (log10(T) - 1) when >= T is added.
# define FMT_INC(T) (((sizeof(#T) - 1ull) << 32) - T)
static constexpr uint64_t table[] = {
FMT_INC(0), FMT_INC(0), FMT_INC(0), // 8
FMT_INC(10), FMT_INC(10), FMT_INC(10), // 64
FMT_INC(100), FMT_INC(100), FMT_INC(100), // 512
FMT_INC(1000), FMT_INC(1000), FMT_INC(1000), // 4096
FMT_INC(10000), FMT_INC(10000), FMT_INC(10000), // 32k
FMT_INC(100000), FMT_INC(100000), FMT_INC(100000), // 256k
FMT_INC(1000000), FMT_INC(1000000), FMT_INC(1000000), // 2048k
FMT_INC(10000000), FMT_INC(10000000), FMT_INC(10000000), // 16M
FMT_INC(100000000), FMT_INC(100000000), FMT_INC(100000000), // 128M
FMT_INC(1000000000), FMT_INC(1000000000), FMT_INC(1000000000), // 1024M
FMT_INC(1000000000), FMT_INC(1000000000) // 4B
};
auto inc = table[__builtin_clz(n | 1) ^ 31];
return static_cast<int>((n + inc) >> 32);
}
template <typename T> constexpr auto count_digits_fallback(T n) -> int {
int count = 1;
for (;;) {
// Integer division is slow so do it for a group of four digits instead
// of for every digit. The idea comes from the talk by Alexandrescu
// "Three Optimization Tips for C++". See speed-test for a comparison.
if (n < 10) return count;
if (n < 100) return count + 1;
if (n < 1000) return count + 2;
if (n < 10000) return count + 3;
n /= 10000u;
count += 4;
}
}这两种用法,查表就是要多一堆符号的,如果业务要小二进制,就不用查表
另外就是 -nodefaultlibs -fno-exceptions 这种场景下 new delete基本也得去掉 最后减小到14K,如果去除main6k fmt整体小于10k
Faster random integer generation with batching
批量生成随机数相当于给一堆数打散,第一反应就是shuffle
void shuffle(mytype *storage, uint64_t size) {
for (uint64_t i = size; i > 1; i--) {
uint64_t nextpos = random(i); // random value in [0,i)
std::swap(storage[i - 1], storage[nextpos]);
}
}显然这个shuffle中的random是瓶颈,我们常规的实现就是%i,有没有更快的做法?
uint64_t random_bounded(uint64_t range) {
__uint128_t random64bit, multiresult;
uint64_t leftover;
uint64_t threshold;
random64bit = rng(); // 64-bit random integer
multiresult = random64bit * range;
leftover = (uint64_t)multiresult;
if (leftover < range) {
threshold = -range % range;
while (leftover < threshold) {
random64bit = rng();
multiresult = random64bit * range;
leftover = (uint64_t)multiresult;
}
}
return (uint64_t)(multiresult >> 64); // [0, range)
}
/ Fisher-Yates shuffle
void shuffle(uint64_t *storage, uint64_t size, uint64_t (*rng)(void)) {
uint64_t i;
for (i = size; i > 1; i--) {
uint64_t nextpos = random_bounded(i, rng);
uint64_t tmp = storage[i - 1];
uint64_t val = storage[nextpos];
storage[i - 1] = val;
storage[nextpos] = tmp;
}
}这实际上也是gcc的实现,我们能不能拆成批量shuffle?
考虑一个场景,你需要多个shuffle,显然每次都执行random_bound代价大
能不能一个random_bound把多个shuffle一起计算?当然可以
然后多个shuffle组合成一个shuffle就是修改index的问题了是不是?
比如拆成两个
// product_bound can be any integer >= range1*range2
// it may be updated to become range1*range2
std::pair<uint64_t, uint64_t>
random_bounded_2(uint64_t range1, uint64_t range2,
uint64_t &product_bound) {
__uint128_t random64bit, multiresult;
uint64_t leftover;
uint64_t threshold;
random64bit = rng(); // 64-bit random integer
multiresult = random64bit * range1;
leftover = (uint64_t)multiresult;
uint64_t result1 = (uint64_t)(multiresult >> 64); // [0, range1)
multiresult = leftover * range2;
leftover = (uint64_t)multiresult;
uint64_t result2 = (uint64_t)(multiresult >> 64); // [0, range2)
if (leftover < product_bound) {
product_bound = range2 * range1;
if (leftover < product_bound) {
threshold = -product_bound % product_bound;
while (leftover < threshold) {
random64bit = rng();
multiresult = random64bit * range1;
leftover = (uint64_t)multiresult;
result1 = (uint64_t)(multiresult >> 64); // [0, range1)
multiresult = leftover * range2;
leftover = (uint64_t)multiresult;
result2 = (uint64_t)(multiresult >> 64); // [0, range2)
}
}
}
return std::make_pair(result1, result2);
}void shuffle_2(mytype *storage, uint64_t size) {
uint64_t i = size;
for (; i > 1 << 30; i--) {
uint64_t index = random_bounded(i, g);
// index is in [0, i-1]
std::swap(storage[i - 1], storage[index]);
}
// Batches of 2 for sizes up to 2^30 elements
uint64_t product_bound = i * (i - 1);
for (; i > 1; i -= 2) {
auto [index1, index2] = random_bounded_2(i, i - 1,
product_bound, g);
// index1 is in [0, i-1]
// index2 is in [0, i-2]
std::swap(storage[i - 1], storage[index1]);
std::swap(storage[i - 2], storage[index2]);
}
}测试linux gcc快30%
Parsing tiny and very large floating-point values: a programming-language comparison
处理无限大无限小,各种语言的差别
python
>>> float("1e-1000")
0.0
>>> float("1e1000")
infgolang
package main
import (
"fmt"
"strconv"
)
func main() {
f, err := strconv.ParseFloat("1e-1000"...C++ 中文周刊 2024-08-18 第166期
本期文章由 HNY 赞助
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-08-14 第267期
文章
彻底理解 C++ ABI
今天群聊提到了一个场景,unique_ptr传值加move 并不能完美优化掉,看代码
void consume(int* ptr);
void foo(int* ptr) {
consume(ptr);
}
/*
foo:
jmp consume@PLT
*/
void consume(unique_ptr<int> ptr);
void foo(unique_ptr<int> ptr) {
consume(std::move(ptr)); //
}
/*
foo(std::unique_ptr<int, std::default_delete<int> >):
push rbx
sub rsp, 16
mov rax, QWORD PTR [rdi]
mov QWORD PTR [rdi], 0
lea rdi, [rsp+8]
mov QWORD PTR [rsp+8], rax
call consume(std::unique_ptr<int, std::default_delete<int> >)
mov rdi, QWORD PTR [rsp+8]
test rdi, rdi
je .L1
mov esi, 4
call operator delete(void*, unsigned long)
.L1:
add rsp, 16
pop rbx
ret
mov rbx, rax
jmp .L3
foo(std::unique_ptr<int, std::default_delete<int> >) [clone .cold]:
*/主要原因是 函数实参在 caller 方析构, unique_ptr没有彻底优化掉。感觉可以优化掉
改成传引用,传&&甚至改成not_null都能省掉
void consume(not_null<int> ptr); //std::unique_ptr<int> && 也可以
void foo(not_null<int> ptr) {
consume(ptr); //
}
/*
foo(not_null<int>):
jmp consume(not_null<int>)
*/感谢anms nugine ni fvs zwuis 讨论
godbolt https://godbolt.org/z/fbqEa4M1r
noexcept Can (Sometimes) Help (or Hurt) Performance
使用noexcept需要保证没有异常,否则生成的代码代价更高
通常来说noexcept是给move用的
另外有一个搞笑的场景
noexcept affects libstdc++’s unordered_set
libstdc++的 unordered set 对于noexcept限定 针对hash函数有特化
如果hash函数是noexcept 认为函数计算很轻,不额外保存key hash,否则会缓存key hash加速
这就导致一个尴尬的场景,对于int,这种优化是对的,对于string hash接口使用noexcept会弄巧成拙速度更慢
标准库对于noexcept限定应该给用户端保留余地,不要影响效果,如果影响,最好给出api约定,比如transparent compare
这种莫名其妙的限制很坑,可能喜欢秀一下用noexcept正好掉坑里
Temporarily dropping a lock: The anti-lock pattern
异步lock暂时解锁的组件。代码
template<typename Mutex>
struct anti_lock
{
anti_lock() = default;
explicit anti_lock(Mutex& mutex)
: m_mutex(std::addressof(mutex)) {
if (m_mutex) m_mutex->unlock();
}
private:
struct anti_lock_deleter {
void operator()(Mutex* mutex) { mutex->lock(); }
};
std::unique_ptr<Mutex, anti_lock_deleter> m_mutex;
};
winrt::fire_and_forget DoSomething()
{
auto guard = std::lock_guard(m_mutex);
step1();
// All co_awaits must be under an anti-lock.
int cost = [&] {
auto anti_guard = anti_lock(m_mutex);
return co_await GetCostAsync();
}();
step2(cost);
}Surprisingly Slow NaNs
https://voithos.io/articles/surprisingly-slow-nans/
代码存在0除0导致NAN NAN导致性能下降
规避?isnan判定 DCHECK
### What's so hard about class types as non-type template parameters?
NTTP 支持类实例的困难原因 无法判定相等
有operator template()提案和反射提案的加持下可能有解
Reflection-based JSON in C++ at Gigabytes per Second
反射给普通库带来压倒性序列化速度,十倍以上!使用的是P2996实现
反射快来吧
互动环节
上周熬夜看了街霸6比赛 直接给我看的不困了,尤其是肯打aki那场,看的我心率110,真刺激
不过熬夜的后果就是一周都缓不过来。睡眠问题非常大,累计起来了,石油杯这个比赛作息太抽象了
时间真快啊,转眼夏天就过去了我靠,感觉啥也没干
东西太多根本看不过来,时间真是不够用
C++ 中文周刊 2024-07-27 第165期
本期文章由 Amniesia HNY Damon 赞助
最近的热门是windows蓝屏事件了,其实国内外安全都有关系户
本期内容不多
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 264期
文章
Safer code in C++ with lifetime bounds
llvm和msvc支持生命周期检查,返回string_view有概率悬空,用错
std::string_view my_get_host(std::string_view url_string) {
auto url = ada::parse(url_string).value();
return url.get_host();
}比如这种用法明显就是错的,加上编译检查能抓出来
#ifndef __has_cpp_attribute
#define ada_lifetime_bound
#elif __has_cpp_attribute(msvc::lifetimebound)
#define ada_lifetime_bound [[msvc::lifetimebound]]
#elif __has_cpp_attribute(clang::lifetimebound)
#define ada_lifetime_bound [[clang::lifetimebound]]
#elif __has_cpp_attribute(lifetimebound)
#define ada_lifetime_bound [[lifetimebound]]
#else
#define ada_lifetime_bound
#endif
...
std::string_view get_host() const noexcept ada_lifetime_bound;编译报错
fun.cpp:8:10: warning: address of stack memory associated with local variable 'url' returned [-Wreturn-stack-address]
8 | return url.get_host();想要了解可以看这里 https://clang.llvm.org/docs/AttributeReference.html#lifetimebound
strlcpy and how CPUs can defy common sense strlcpy and how CPUs can defy common sense
strlcpy 实现openbsd和glibc实现不同,openbsd是这样的
size_t strlcpy(char *dst, const char *src, size_t dsize)
{
const char *osrc = src;
size_t nleft = dsize;
if (nleft != 0) while (--nleft != 0) { /* Copy as many bytes as will fit. */
if ((*dst++ = *src++) == '\0')
break;
}
if (nleft == 0) { /* Not enough room in dst, add NUL and traverse rest of src. */
if (dsize != 0) *dst = '\0'; /* NUL-terminate dst */
while (*src++) ;
}
return(src - osrc - 1); /* count does not include NUL */
}能看到是一边复制一边移动的,没有提前算出src边界,而glibc是用strlen先计算src长度的,相当于重复计算了
所以openbsd版本应该比glibc版本快是不是?并不
考虑到strlen和memcpy有可能优化,咱们手写一个版本
size_t bespoke_strlcpy(char *dst, const char *src, size_t size)
{
size_t len = 0;
for (; src[len] != '\0'; ++len) {} // strlen() loop
if (size > 0) {
size_t to_copy = len < size ? len : size - 1;
for (size_t i = 0; i < to_copy; ++i) // memcpy() loop
dst[i] = src[i];
dst[to_copy] = '\0';
}
return len;
}编译使用 -fno-builtin避免strlen memcpy优化
这个也比openbsd快
实际上没有长度信息 每次都要判断\0,严重影响优化,循环出现依赖,没法彻底优化
What's so hard about constexpr allocation?
讨论constexpr vector难做的原因,先从unique_ptr开始讨论,constexpr导致相关的传递语义发生变化,不好优化
考虑引入新关键字propconst 标记常量传递 讨论的还是比较有深度的,感兴趣的可以读一下
Does C++ allow template specialization by concepts?
用require实现函数偏特化
template <typename T>
void clear(T & t);
template <typename T>
concept not_string =
!std::is_same_v<T, std::string>;
template <>
void clear(std::string & t) {
t.clear();
}
template <class T>
void clear(T& container) requires not_string<T> {
for(auto& i : container) {
i = typename T::value_type{};
}
}看一乐
Scan HTML even faster with SIMD instructions (C++ and C#)
实现特殊版本find_first_of 向量化。代码不贴了,感兴趣的看一下
开源项目介绍
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群753302367和作者对线
互动环节
看了死侍金刚狼 还可以。现在漫威太垃圾了,这还算能看的
实际剧情和银河护卫队差不多,不能细想反派,看个乐呵
C++ 中文周刊 2024-07-20 第164期
本期文章由 HNY lh_mouse 终盛 赞助
资讯
标准委员会动态/ide/编译器信息放在这里
其中 3351是群友Mick的提案
群友发的就等于大家发的,都是机会滋道吧
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-07-10 第262期
ThinkCell发布了他们的C++26参会报告 Trip Report: Summer ISO C++ Meeting in St. Louis, USA
另外发现了一个好玩的网站 https://highload.fun/tasks/ 各种大数据场景 各种优化trick都可以用。感觉适合做面试题
另外发现一个关于高频低延迟开发的一本小书
C++ design patterns for low-latency applications including high-frequency tradin
这里总结一下
- cache warm
代码大概这样
#include <benchmark/benchmark.h>
#include <vector>
#include <algorithm>
constexpr int kSize = 10000000;
std::vector<int> data(kSize);
std::vector<int> indices(kSize);
static void BM_CacheCold(benchmark::State& state) {
// Generate random indices
for(auto& index : indices) {
index = rand() % kSize;
}
for (auto _ : state) {
int sum = 0;
// Access data in random order
for (int i = 0; i < kSize; ++i) {
benchmark::DoNotOptimize(sum += data[indices[i]]);
}
benchmark::ClobberMemory();
}
}
static void BM_CacheWarm(benchmark::State& state) {
// Warm cache by accessing data in sequential order
int sum_warm = 0;
for (int i = 0; i < kSize; ++i) {
benchmark::DoNotOptimize(sum_warm += data[i]);
}
benchmark::ClobberMemory();
// Run the benchmark
for (auto _ : state) {
int sum = 0;
// Access data in sequential order again
for (int i = 0; i < kSize; ++i) {
benchmark::DoNotOptimize(sum += data[i]);
}
benchmark::ClobberMemory();
}
}测试数据直接快十倍,之前也讲过类似的场景
- 利用模版和constexpr 这个就不多说了
- 循环展开 这个也不说了
- 区分快慢路径
- 减少错误分支
- prefetch
一个例子
#include <benchmark/benchmark.h>
#include <vector>
// Function without __builtin_prefetch
void NoPrefetch(benchmark::State& state) {
// Create a large vector to iterate over
std::vector<int> data(state.range(0), 1);
for (auto _ : state) {
long sum = 0;
for (const auto& i : data) {
sum += i;
}
// Prevent compiler optimization to discard the sum
benchmark::DoNotOptimize(sum);
}
}
BENCHMARK(NoPrefetch)->Arg(1<<20); // Run with 1MB of data (2^20 integers)
// Function with __builtin_prefetch
void WithPrefetch(benchmark::State& state) {
// Create a large vector to iterate over
std::vector<int> data(state.range(0), 1);
for (auto _ : state) {
long sum = 0;
int prefetch_distance = 10;
for (int i = 0; i < data.size(); i++) {
if (i + prefetch_distance < data.size()) {
__builtin_prefetch(&data[i + prefetch_distance], 0, 3);
}
sum += data[i];
}
// Prevent compiler optimization to discard the sum
benchmark::DoNotOptimize(sum);
}
}
BENCHMARK(WithPrefetch)->Arg(1<<20); // Run with 1MB of data (2^20 integers)
BENCHMARK_MAIN();论文中快30%,当然编译器可以向量化的吧,不用手动展开吧
- 有符号无符号整数比较,慢,避免
- float double混用慢,避免
- SSE加速
- mutex替换成atomic (这个还是取决于应用场景)
- bypass
还有其他模块介绍就不谈了,比较偏HFT
文章
C++ Error Handling Strategies – Benchmarks and Performance
浅析Cpp 错误处理
最近不约而同有两个关于错误处理的压测
第一个文章没有体验出正确路径错误路径不同压力的表现,只测了错误路径,因此没啥代表价值。只是浅显的说了异常代价大,谁还不知道这个
问题是什么情况用异常合适?异常不是你期待的东西,如果你的错误必须处理,那就不叫异常
另外第二篇文章是群友写的,给了个50%失败错误路径的测试,结果符合直觉
结论: 异常在happy path出现的路径下收益高(错误出现非常少)
我相信大多数人都没看过这个,是的我之前也没有看过
这个话题可以展开讲一下,这里标记一个TODO
When __cxa_pure_virtual is just a different flavor of SEGFAULT
有时候可能会遇到这种打印挂掉pure virtual method called
一个简单的复现代码
class Base {
public:
Base() {fn();} // thinking it would be calling the Derived's `fn()`
// the same happens with dtor
// virtual ~Base() {fn();}
virtual void fn() = 0;
};
class Derived : public Base{
public:
void fn() {}
};
int main() {
Derived d;
return 0;
}简单来说基类构造的时候子类还没构造,fn没绑定,还是纯虚函数,就会挂
不要这么写,不要在构造函数中调用虚函数
What’s the point of std::monostate? You can’t do anything with it!
就是空类型,帮助挡刀的
比如这个场景
struct Widget {
// no default constructor
Widget(std::string const& id);
};
struct PortListener {
// default constructor has unwanted side effects
PortListener(int port = 80);
};
std::variant<Widget, PortListener> thingie; // can't do this
我们想让Widget当第一个,但是Widget没有默认构造,PortListener放第一个又破坏可读性,对应关系乱了
怎么办,monostate出场
std::variant<std::monostate, Widget, PortListener> thingie;帮Widget挡一下编译问题
顺便一提,monostate的hash
result_type operator()(const argument_type&) const {
return 66740831; // return a fundamentally attractive random value.
}开源项目介绍
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群753302367和作者对线
- https://github.com/Psteven5/CFLAG.h/tree/main 一个类似GFLAGS的库,但是功能非常简单,口述一下原理
示例代码
int main(int argc, char **argv) {
char const *i = NULL, *o = NULL;
bool h = false;
CFLAGS(i, o, h);
printf("i=%s, o=%s, h=%s\n", i, o, h ? "true" : "false");
}
// ./main -i=main.js -h -o trash主要原理就是利用c11的_Generic
介绍一下generic用法
#include <math.h>
#include <stdio.h>
// Possible implementation of the tgmath.h macro cbrt
#define cbrt(X) _Generic((X), \
long double: cbrtl, \
default: cbrt, \
float: cbrtf \
)(X)
int main(void) {
double x = 8.0;
const float y = 3.375;
printf("cbrt(8.0) = %f\n", cbrt(x)); // selects the default cbrt
printf("cbrtf(3.375) = %f\n", cbrt(y)); // converts const float to float,
// then selects cbrtf
}看懂了吧,_Generic根据输入能生成自定义的语句,上面的例子根据X生成对应的函数替换
能换函数,那肯定也能换字符串,这个关键字能玩的很花哨
回到我们这个flags,和Gflags差不多,我们怎么实现?
我们考虑一个最简单的场景 CFLAGS(i),应该展开成 解析arg遍历匹配字符串i并讲对应的值赋值给i,这个赋值得通过格式化字符串复制
遍历arg好实现,通过argc argv遍历就行,i字符串话也简单 #,把argv的值赋值, sscanf,格式化字符串哪里来?generic
大概思路已经有了,怎么实现大家看代码吧
互动环节
周末看了抓娃娃,和西虹市首富差不多,结尾马马虎虎。还算好笑
好久没去电影院的椅子全变成带按摩的了,离谱,被赚了20
C++ 中文周刊 164期补充
昨天更新关于HFT的内容有误
-
cache warm 效果有限,加热icache缺乏其他优化验证修复,比如pgo,比如调大tlb。当然cache warm对于可以观测数据集预估业务的场景来说,简单粗暴,不过对于优化而言,很难说问题的根因在哪里,PGO应该是最直观的,cache warm给人一种野路子歪打正着的感觉,需要进一步分析。对于不可预估后端场景,cache warm就相当于CPU做无用功了,一定要测试,测试,测试
-
其他例子,比如prefetch等,例子粗糙,缺少系统视角,如果缺乏这个知识需要科普,看这个小册子,反而可能造成误导
需要系统了解可以看现代cpu性能分析与优化 有中文版本
英文版 https://book.easyperf.net/perf_book
中文版本可能比较旧,但对于科普系统学习知识也足够,京东77应该是涨价了,我买的时候是50
公开课可以学一下mit 6.172 b站有视频 ppt可以这里下载 https://ocw.mit.edu/courses/6-172-performance-engineering-of-software-systems-fall-2018/
实际上优化相关知识广,碎,杂,需要系统整体视角
本文感谢崔博武 Anien 指正
C++ 中文周刊 2024-07-06 第163期
本期文章由 HMY lhmouse赞助
资讯
标准委员会动态/ide/编译器信息放在这里
最近陆陆续续又有很多c++26 St Louis参会报告出来,这里列一下
另外Ykiko也写了一个 St. Louis WG21 会议回顾
OpenSSH 鉴权超时终止会话时信号竞态条件漏洞,可远程攻击,可拿root shell
2020年10月到24年5月之间的版本全部中招,请及时打补丁
本台记者lhmouse报道
我们在 OpenSSH 的服务器(sshd)中发现了一个漏洞(信号处理器竞赛条件):如果客户端没有在 LoginGraceTime 秒(默认为 120 秒,旧版本为 600 秒)内进行身份验证,那么 sshd 的 SIGALRM 处理器就会被异步调用,但这个信号处理器会调用各种非异步信号安全的函数(例如 syslog())。这种竞赛条件会影响默认配置下的 sshd。
经调查,我们发现该漏洞实际上是 CVE-2006-5051 的回归("4.4 之前 OpenSSH 中的信号处理器竞赛条件允许远程攻击者导致拒绝服务(崩溃),并可能执行任意代码"),该漏洞由 Mark Dowd 于 2006 年报告。
这一回归是在 2020 年 10 月(OpenSSH 8.5p1)的 752250c 号提交("修订 OpenSSH 的日志基础架构")中引入的,该提交意外删除了 sigdie() 中的 "#ifdef DO_LOG_SAFE_IN_SIGHAND",而 sigdie() 是 sshd 的 SIGALRM 处理程序直接调用的函数。换句话说
如果未针对 CVE-2006-5051 进行回传修补,或未针对 CVE-2008-4109 进行修补(CVE-2008-4109 是针对 CVE-2006-5051 的不正确修补),OpenSSH < 4.4p1 就容易受到此信号处理器竞赛条件的影响;
4.4p1 <= OpenSSH < 8.5p1 不会受到此信号处理器竞赛条件的影响(因为 CVE-2006-5051 补丁在 sigdie() 中添加的 "#ifdef DO_LOG_SAFE_IN_SIGHAND "将此不安全函数转换为安全的 _exit(1) 调用);
8.5p1 <= OpenSSH < 9.8p1 会再次出现这种信号处理竞赛条件(因为 "#ifdef DO_LOG_SAFE_IN_SIGHAND" 被意外地从 sigdie() 中删除了)。
鉴定为和之前xz 被植入木马一样的问题
开源社区并不是免费的,得盯着相关更新了
(安全的同事应该是在关注的。不过这些年降本增效第一个裁的就是安全吧)
文章
Can you change state in a const function in C++? Why? How?
const_cast
Cooperative Interruption of a Thread in C++20
介绍stop_token,其实就是塞了个状态回调,规范化了一下 直接看代码
#include <chrono>
#include <iostream>
#include <thread>
#include <vector>
using namespace::std::literals;
auto func = [](std::stop_token stoken) { // (1)
int counter{0};
auto thread_id = std::this_thread::get_id();
std::stop_callback callBack(stoken, [&counter, thread_id] { // (2)
std::cout << "Thread id: " << thread_id
<< "; counter: " << counter << '\n';
});
while (counter < 10) {
std::this_thread::sleep_for(0.2s);
++counter;
}
};
int main() {
std::vector<std::jthread> vecThreads(10);
for(auto& thr: vecThreads) thr = std::jthread(func);
std::this_thread::sleep_for(1s); // (3)
for(auto& thr: vecThreads) thr.request_stop(); // (4)
}A 16-byte std::function implementation.
直接贴代码吧
template<typename T>
struct sfunc;
template<typename R, typename ...Args>
struct sfunc<R(Args...)> {
struct lambda_handler_result {
void* funcs[3];
};
enum class tag {
free,
copy,
call
};
lambda_handler_result (*lambda_handler)(void*, void**) {nullptr};
void* lambda {nullptr};
template<typename F>
sfunc(F f) { *this = f;}
sfunc() {}
sfunc(const sfunc& f) { *this = f; }
sfunc(sfunc&& f) { *this = f; }
sfunc& operator = (sfunc&& f) {
if(&f == this){
return *this;
}
lambda_handler = f.lambda_handler;
lambda = f.lambda;
f.lambda_handler = nullptr;
f.lambda = nullptr;
return *this;
}
void free_lambda() {
if(lambda_handler) {
auto ff {lambda_handler(lambda, nullptr).funcs[(int)tag::free]};
if(ff){
((void(*)(void*))ff)(lambda);
}
}
lambda = nullptr;
}
sfunc& operator = (const sfunc& f) {
if(&f == this) {
return *this;
}
free_lambda();
lambda_handler = f.lambda_handler;
if(f.lambda) {
auto ff {lambda_handler(lambda, nullptr).funcs[(int)tag::copy]};
if(ff) {
((void(*)(void*, void**))ff)(f.lambda, &lambda);
} else {
lambda = f.lambda;
}
}
return *this;
}
template<typename ...>
struct is_function_pointer;
template<typename T>
struct is_function_pointer<T> {
static constexpr bool value {false};
};
template<typename T, typename ...Ts>
struct is_function_pointer<T(*)(Ts...)> {
static constexpr bool value {true};
};
template<typename F>
auto operator = (F f) {
if constexpr(is_function_pointer<F>::value == true) {
free_lambda();
lambda = (void*)f;
lambda_handler = [](void* l, void**) {
return lambda_handler_result{/* 两个括号jekyll报错*/{nullptr, nullptr, (void*)+[](void* l, Args... args) {
auto& f {*(F)l};
return f(forward<Args>(args)...);
}}};
};
} else {
free_lambda();
lambda = {new F{f}};
lambda_handler = [](void* d, void** v) {
return lambda_handler_result{/* 两个括号jekyll报错*/{(void*)[](void*d){ delete (F*)d;},
(void*)[](void*d, void** v){ *v = new F{*((F*)d)};},
(void*)[](void* l, Args... args)
{
auto& f {*(F*)l};
return f(forward<Args>(args)...);
}}};
};
}
}
inline R operator()(Args... args) {
return ((R(*)(void*, Args...))lambda_handler(nullptr, nullptr).funcs[(int)tag::call])(lambda, forward<Args>(args)...);
}
~sfunc() { free_lambda(); }
};没SSO
A Type for Overload Set
函数没有类型,直接赋值是不可以的
void f(int);
void f(int, int);
// `f` is an overload set with 2 members
auto g = f; // error! cannot deduce the type of `g`
// This is because:
using FF = decltype(f); // error! overload set has not type
std::invocable<int> auto g = f; // error! cannot deduce the type of `g`
// bind invoke也不行,他们要接受对象
而lambda有类型,即使这个类型看不到,那么就可以封装一层
#include <cassert>
#include <utility>
int g(int x) { return x + 1; }
int g(int x, int y) { assert(false); }
class MyClass {
public:
int f(int x) { return x + 1; }
int f(int x, int y) { assert(false); }
};
#define OVERLOAD(...) [&](auto &&... args) -> decltype(auto) { \
return __VA_ARGS__(std::forward<decltype(args)>(args)...); \
}
int main(int argc, char *argv[]) {
assert(OVERLOAD(g)(5) == 6);
MyClass obj;
assert(OVERLOAD(obj.f)(5) == 6);
return 0;
}Compile-time JSON deserialization in C++
没看懂
Beating NumPy's matrix multiplication in 150 lines of C code
代码在这 https://github.com/salykova/matmul.c
感觉不是很靠谱,影响因素太多了
视频
C++ Weekly - Ep 435 - Easy GPU Programming With AdaptiveCpp (68x Faster!)
自己看吧,我不是业内,不了解
Björn Fahller: Cache friendly data + functional + ranges = ❤️ https://www.youtube.com/watch?v=3Rk-zSzloL4&ab_channel=SwedenCpp
开源项目介绍
互动环节
团建了一波,定的酒店露天自助,人均四百,吃出了80的感觉,亏麻
酒店内的餐饮服务还是太坑
C++ 中文周刊 2024-06-30 第162期
欢迎投稿,推荐或自荐文章/软件/资源等,评论区留言
本期文章由 HMY lhmouse赞助
资讯
标准委员会动态/ide/编译器信息放在这里
后续有其他报道咱们也会转发一下
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-06-26 第260期
文章
Member ordering and binary sizes
就是字段排序可能存在空洞 导致padding填充
比如
class Example1 {
public:
double a;// = 4.2; // 8 bytes
int b;// = 1; // 4 bytes
float c; // 4 bytes
char d; // 1 byte
bool e; // 1 byte
bool f; // 1 byte
// Assuming typical alignment, 'a' (8 bytes) should be first,
// followed by 'b' and 'c' (both 4 bytes), and then 'd' and 'e' (1 byte each).
};
static_assert(sizeof(Example1) == 24);
struct Example2 {
int b;//=1; // 4 bytes
char d; // 1 byte
float c; // 4 bytes
bool e; // 1 byte
double a;// = 4.2; // 8 bytes
bool f;
};
static_assert(sizeof(Example2) == 32);popcnt也能向量化?
看个乐
UB or not UB: How gcc and clang handle statically known undefined behaviour
省流 gcc遇到UB倾向于生成ud2 崩溃,clang遇到UB倾向于不崩溃,把影响抹除
How the STL uses explicit
Efficiently allocating lots of std::shared_ptr
单线程分配shared_ptr对象,比较new make_shared 对象池,压测结果
| new | make_shared | fast_pool_allocator | |
|---|---|---|---|
| GCC | 69.0 | 38.1 | 34.0 |
| Clang + libstdc++ | 69.2 | 38.6 | 35.7 |
| Clang + libc++ | 76.5 | 40.8 | 40.4 |
| GCC + tcmalloc | 57.2 | 30.3 | 33.8 |
| GCC + jemalloc | 86.7 | 42.7 | 33.9 |
看一乐 当然结果是满足直觉的,池化快一些,或者别用一堆shared ptr
How much memory does a call to ‘malloc’ allocates?
讲的是个常识,你分配的内存总是向上取整的,不一定是你要多少分配多少
size, speed and order tradeoffs
其实就是访问l1 l2 cache会有不同延迟,通过不同大小文件来测试,有空可以跑一下代码
为什么C++的std::forward会有两种重载
超详细!spdlog源码解析
Latency-Sensitive Applications and the Memory Subsystem: Keeping the Data in the Cache
while循环,没干活,干活逻辑是数据访问,那没干活分支应该可以热数据
比如原来的逻辑
td::unordered_map<int32_t, order> my_orders;
...
packet_t* p;
while(!exit) {
p = get_packet();
// If packet arrived
if (p) {
// Check if the identifier is known to us
auto it = my_orders.find(p->id);
if (it != my_orders.end()) {
send_answer(p->origin, it->second);
}
}
}while里是个干活逻辑,但是有个大的if,我们可以把这个if拆出来分成干活不干活两个逻辑
std::unordered_map<int32_t, order> my_orders;
...
packet_t* p;
int64_t total_random_found = 0;
while(!exit) {
// 增加个检查header 然后再判断packet,不满足就去warm
// 如果header没满足,packet必不满足
if (packet_header_arrived()) {
p = get_packet();
// If packet arrived
if (p) {
// Check if the identifier is known to us
auto it = my_orders.find(p->id);
if (it != my_orders.end()) {
send_answer(p->origin, it->second);
}
}
} else {
// 不干活就Cache warming
auto random_id = get_random_id();
auto it = my_orders.find(random_id);
// 随便干点啥避免被编译器优化掉
total_random_found += (it != my_orders.end());
}
}
std::cout << "Total random found " << total_random_found << "\n";当然这种cache warm不一定非得随机,有可能副作用
可以从历史值来用,有个词怎么说来着,启发式
硬件层也有cache warm 比如 intel
amd也有 L3 Cache Range Reservation 不过没例子
作者测试了软件模拟cache warm,随机访问
数据,迭代多次的延迟,越小越好
| hashmap数据量 | 正常访问hashmap | 没有访问的时候只warm 0 | 没有访问的时候随机warm |
|---|---|---|---|
| 1 K | 226.1 (219.0) | 213.3 (205.1) | 132.5 (67.3) |
| 4 K | 324.7 (296.3) | 350.7 (331.3) | 140.1 (95.4) |
| 16 K | 396.8 (341.1) | 389.1 (354.5) | 208.7 (134.5) |
| 64 K | 425.5 (376.1) | 416.0 (360.6) | 232.1 (152.6) |
| 256 K | 514.2 (451.5) | 473.3 (480.6) | 338.8 (317.6) |
| 1 M | 599.8 (550.2) | 615.1 (573.6) | 466.3 (429.8) |
| 4 M | 702.1 (647.0) | 619.7 (649.2) | 531.3 (508.3) |
| 16 M | 756.7 (677.6) | 668.8 (707.4) | 543.2 (499.9) |
| 64 M | 769.1 (702.3) | 735.9 (734.2) | 641.0 (774.4) |
能看到随机访问 随机warm效果显著
Latency-Sensitive Application and the Memory Subsystem Part 2: Memory Management Mechanisms
这篇文章的视角比较奇怪,可能和已知的信息不同,目标是低延迟避免内存机制影响
page fault会引入延迟,所以要破坏page fault的生成条件 怎么做?
尽可能分配好,而不是用到在分配,有概率触发page fault
- mmap使用MAP_POPULATE
- 使用calloc不用malloc,用malloc/new 强制0填充
- 零初始化数组,立马使用上
- vector 创造时直接构造好大小,不用reserve reserve不一定内存预分配,可能还会造成page fault()
- 或者重载allocator,预先分配内存
- 其他容器也是有类似的问题
- 使用内存大页
- 禁用 5-Level Page Walk
- TLB shotdown规避 这个一时半会讲不完 可以看这个
- 关闭swap
视频
C++ Weekly - Ep 434 - GCC's Amazing NEW (2024) -Wnrvo
-Wnrvo 帮助分析,效果显著
Mirko Arsenijević — Lifting the Pipes - Beyond Sender/Receiver and Expected Outcome — 26.6.2024.
介绍他的dag库,没开源
开源项目介绍
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群753302367和作者对线
互动环节
最近睡眠很差,如果觉得内容有误大家多多指出,困了,先睡
练了一下午街霸6,好难啊我靠,我年纪真是大了,反应跟不上连招连不上,也有可能是设备不行
C++ 中文周刊 2024-06-23 第161期
本期文章由 HNY lhmouse 赞助
lhmouse的项目 mcfthread/asteria 推荐大家关注
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 第268期
文章
C++20 std::format 替换 fmtlib 的关键点
可以参考
Lambda, bind(front), std::function, Function Pointer Benchmarks
看一乐
gcc 协程的那些bug
看一乐
Your Own Constant Folder in C/C++
clang ffast-math有bug
__m128 test(const __m128 vec)
{
return _mm_sqrt_ps(vec);
}
/*
test: # @test
sqrtps xmm0, xmm0
ret
*/正常生成汇编没问题,但ffast-math生成的汇编有问题, 会替换成rsqrtps然后由于精度问题退化成牛顿法,反而满了我靠
.LCPI0_0:
.long 0xbf000000 # float -0.5
.long 0xbf000000 # float -0.5
.long 0xbf000000 # float -0.5
.long 0xbf000000 # float -0.5
.LCPI0_1:
.long 0xc0400000 # float -3
.long 0xc0400000 # float -3
.long 0xc0400000 # float -3
.long 0xc0400000 # float -3
test:
rsqrtps xmm1, xmm0
movaps xmm2, xmm0
mulps xmm2, xmm1
movaps xmm3, xmmword ptr [rip + .LCPI0_0] # xmm3 = [-5.0E-1,-5.0E-1,-5.0E-1,-5.0E-1]
mulps xmm3, xmm2
mulps xmm2, xmm1
addps xmm2, xmmword ptr [rip + .LCPI0_1]
mulps xmm2, xmm3
xorps xmm1, xmm1
cmpneqps xmm0, xmm1
andps xmm0, xmm2
ret为了规避只好手写汇编
__m128 test(__m128 vec)
{
__asm__ ("sqrtps %1, %0" : "=x"(vec) : "x"(vec));
return vec;
}但是手写汇编优化不彻底,该有的常量折叠没做
__attribute__((always_inline)) __m128 test(__m128 vec)
{
__asm__ ("sqrtps %1, %0" : "=x"(vec) : "x"(vec));
return vec;
}
__m128 call_test()
{
return test(_mm_setr_ps(1.f, 2.f, 3.f, 4.f));
}test:
sqrtps xmm0, xmm0
ret
.LCPI1_0:
.long 0x3f800000 # float 1
.long 0x40000000 # float 2
.long 0x40400000 # float 3
.long 0x40800000 # float 4
call_test:
movaps xmm0, xmmword ptr [rip + .LCPI1_0] # xmm0 = [1.0E+0,2.0E+0,3.0E+0,4.0E+0]
sqrtps xmm0, xmm0
retsqrtps并没有优化掉
手动折叠, __builtin_constant_p
__attribute__((always_inline)) __m128 test(__m128 vec)
{
if (__builtin_constant_p(vec))
{
return _mm_sqrt_ps(vec);
}
__asm__ ("sqrtps %1, %0" : "=x"(vec) : "x"(vec));
return vec;
}
__m128 call_test()
{
return test(_mm_setr_ps(1.f, 2.f, 3.f, 4.f));
}汇编
call_test:
movaps xmm0, xmmword ptr [rip + .LCPI11_0] # xmm0 = [1.0E+0,2.0E+0,3.0E+0,4.0E+0]
sqrtps xmm0, xmm0
ret并没有优化掉??又有个bug,__builtin_constant_p不能用于数组,得手动展开
__attribute__((always_inline)) __m128 test(__m128 vec)
{
if (__builtin_constant_p(vec[0]) &&
__builtin_constant_p(vec[1]) &&
__builtin_constant_p(vec[2]) &&
__builtin_constant_p(vec[3]))
{
return _mm_sqrt_ps(vec);
}
__asm__ ("sqrtps %1, %0" : "=x"(vec) : "x"(vec));
return vec;
}
__m128 call_test()
{
return test(_mm_setr_ps(1.f, 2.f, 3.f, 4.f));
}.LCPI15_0:
.long 0x3f800000 # float 1
.long 0x3fb504f3 # float 1.41421354
.long 0x3fddb3d7 # float 1.73205078
.long 0x40000000 # float 2
call_test:
movaps xmm0, xmmword ptr [rip + .LCPI15_0] # xmm0 = [1.0E+0,1.41421354E+0,1.73205078E+0,2.0E+0]
ret折叠了
Displaying File Time in C++: Finally fixed in C++20
c++20之前,文件的时间不够直观,得转一手
auto filetime = fs::last_write_time(myPath);
std::time_t convfiletime = std::chrono::system_clock::to_time_t(filetime);
std::cout << "Updated: " << std::ctime(&convfiletime) << '\n';c++20可以直接用了
auto temp = std::filesystem::temp_directory_path() / "example.txt";
std::ofstream(temp.c_str()) << "Hello, World!";
auto ftime = std::filesystem::last_write_time(temp);
std::cout << std::format("File write time is {0:%R} on {0:%F}\n", ftime);
std::cout << ftime;
// File write time is 14:52 on 2024-06-22
// 2024-06-22 14:52:46.632061324Temporary Lifetime Extension: Complicated Cases
这个之前讲过,就是这个例子
#include <iostream>
#include <string_view>
#include <cstring>
struct Example {
char data[6] = "hello";
std::string_view sv = data;
~Example() {
strcpy(data, "bye");
std::cout <<"~Example: "<< sv << '\n';
}
};
int main() {
auto&& local = Example().sv; // Here we extend lifetime of entire Example
std::cout << local << '\n'; // 打印hello
}Example并不会立即析构,生命周期被local延长了,local打印hello
How to use the new counted_by attribute in C (and Linux)
列举了内核里使用count by的例子,比如
- cmd.cmd.scan_type = WMI_ACTIVE_SCAN;
- cmd.cmd.num_channels = 0;
+ cmd->scan_type = WMI_ACTIVE_SCAN;
+ cmd->num_channels = 0;
n = min(request->n_channels, 4U);
for (i = 0; i < n; i++) {
int ch = request->channels[i]->hw_value;
@@ -991,7 +988,8 @@ static int wil_cfg80211_scan(struct wiphy *wiphy,
continue;
}
/* 0-based channel indexes */
- cmd.cmd.channel_list[cmd.cmd.num_channels++].channel = ch - 1;
+ cmd->num_channels++;
+ cmd->channel_list[cmd->num_channels - 1].channel = ch - 1;
wil_dbg_misc(wil, "Scan for ch %d : %d MHz\n", ch,
request->channels[i]->center_freq);
}
...
--- a/drivers/net/wireless/ath/wil6210/wmi.h
+++ b/drivers/net/wireless/ath/wil6210/wmi.h
@@ -474,7 +474,7 @@ struct wmi_start_scan_cmd {
struct {
u8 channel;
u8 reserved;
- } channel_list[];
+ } channel_list[] __counted_by(num_channels);
} __packed;没啥说的。就是针对变长数组做的一个patch,帮助编译器分析的,类似guard_by
Double Linked List with a Single Link Field
就是异或链表,代码不贴了,谁这么写离我远点
On the sadness of treating counted strings as null-terminated strings
字符串复制要注意/0截断问题
Implementing General Relativity: What's inside a black hole?
看不懂
视频
C++ Weekly - Ep 433 - C++'s First New Floating Point Types in 40 Years!
介绍float特殊类型
#include <bit>
#include <concepts>
#include <cstdint>
#include <format>
#include <iomanip>
#include <iostream>
#include <stdfloat>
void explore_float16(std::uint16_t val) {
const auto f16 = std::bit_cast<std::float16_t>(val);
const auto bf16 = std::bit_cast<std::bfloat16_t>(val);
std::cout << std::format(
"{:#016b} {:#04x} {} {}f16 (0b{:01b}'{:05b}'{:010b}) {}bf16 "
"(0b{:01b}'{:08b}'{:07b})\n",
val, val, val, f16, (val >> 15) & 0b1, (val >> 10) & 0b11111,
(val & 0b1111111111), bf16, (val >> 15) & 0b1, (val >> 7) & 0b11111111,
(val & 0b1111111));
}
int main() {
explore_float16(0b0'01101'0101010101);
explore_float16(0b0'11110'1111111111);
explore_float16(0b1'11100'0011111111);
}开源项目介绍
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群753302367和作者对线
- https://github.com/mull-project/mull 一个mutation test库,有点意思
互动环节
最近的热点消息那必然是各个群里都传的过劳事件了,大家保重身体不要太拼了,起码睡够,不睡够干不了活的,起码闭眼够
C++ 中文周刊 2024-06-17 第160期
本期文章由 HNY 赞助
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-06-12 第258期
文章
Why do Windows functions all begin with a pointless MOV EDI, EDI instruction?
这是2011年的文章了,最近又有讨论了,简单来说就是nop,window上可以在线热补丁把这行汇编替换成jmp xx 不过这玩意也就windows 有
其实XCHG edi, edi也是一个意思
Making a bignum library for fun
实现一个大数乘法,直接看代码吧
这里当字符串处理的,难度降低了很多, 面试题属于是
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
typedef struct {
char *digits;
int size;
} BigNum;
void bignum_init(BigNum *n, const char *str) {
n->size = strlen(str);
n->digits = malloc(n->size * sizeof(char));
for (int i = 0; i < n->size; i++) {
// Store digits in reverse. Convert from ASCII.
n->digits[i] = str[n->size - 1 - i] - '0';
}
}
void bignum_free(BigNum *n) {
free(n->digits);
n->digits = NULL;
n->size = 0;
}
void bignum_print(BigNum *n) {
printf("BigNum: ");
for (int i = n->size - 1; i >= 0; i--) {
printf("%d", n->digits[i]);
}
printf("\n");
}
int bignum_compare(const BigNum *a, const BigNum *b) {
// Returns 1 if a is greater than b, -1 if less than, and 0 if equal to.
if (a->size != b->size) {
return a->size > b->size ? 1 : -1;
}
for (int i = a->size - 1; i >= 0; i--) {
if (a->digits[i] != b->digits[i]) {
return a->digits[i] > b->digits[i] ? 1 : -1;
}
}
return 0;
}
void bignum_add(BigNum *result, const BigNum *a, const BigNum *b) {
int max_size = a->size > b->size ? a->size : b->size;
result->digits = malloc((max_size + 1) * sizeof(char));
int carry = 0;
int i;
for (i = 0; i < max_size || carry; i++) {
int sum = carry + (i < a->size ? a->digits[i] : 0) + (i < b->size ? b->digits[i] : 0);
result->digits[i] = sum % 10; // Store the last digit of the sum.
carry = sum / 10; // Carry any overflow.
}
result->size = i;
}
void bignum_multiply(BigNum *result, const BigNum *a, const BigNum *b) {
result->digits = calloc(a->size + b->size, sizeof(char));
result->size = a->size + b->size; // Max size we will need.
for (int i = 0; i < a->size; i++) {
for (int j = 0; j < b->size; j++) {
int index = i + j;
result->digits[index] += a->digits[i] * b->digits[j];
result->digits[index + 1] += result->digits[index] / 10;
result->digits[index] %= 10;
}
}
// Trim any leading zeros.
while (result->size > 1 && result->digits[result->size - 1] == 0) {
result->size--;
}
}
int main() {
BigNum a, b, sum, product;
bignum_init(&a, "12345678901234567890");
bignum_init(&b, "98765432109876543210");
bignum_print(&a);
bignum_print(&b);
bignum_add(&sum, &a, &b);
bignum_print(&sum);
bignum_free(&sum);
bignum_multiply(&product, &a, &b);
bignum_print(&product);
bignum_free(&product);
int cmp_result = bignum_compare(&a, &b);
if (cmp_result > 0) {
printf("a is greater than b\n");
} else if (cmp_result < 0) {
printf("a is less than b\n");
} else {
printf("a is equal to b\n");
}
bignum_free(&a);
bignum_free(&b);
return 0;
}Using namespaces effectively
不要头文件直接使用using namespace 放在cpp文件中或者函数里
另外 namespace 版本控制,两种玩法
namespace gem {
namespace v1 {
struct Point {
int x;
int y;
};
}
namespace v2 {
struct Point {
int y; // y goes first in v2
int x;
};
}
using namespace v1; // pull everything under v1 out
}namespace gem {
inline namespace v1 {
...
}
namespace v2 {
...
}
}推荐用inline,少写一行
其实是c++11之前有bug,但是我觉得还是不知道这个bug比较好,就当少写一行
What’s the deal with std::type_identity?
template<typename T>
struct type_identity {
using type = T;
};感觉很垃圾,这是干嘛的?
举个例子
template<typename T>
T add(T a, T b) {
return a + b;
}
auto sum = add(0.5, 1); // error: cannot deduce T报错了,这怎么办?主要是类型匹配太多,可以用identity建立关系,消除冲突的重载
template<typename T>
T add(T a, std::type_identity_t<T> b) {
return a + b;
}
auto sum = add(0.5, 1); // T is "double"来个现实例子
void enqueue(std::function<void(void)> const& work);
template<typename...Args>
void enqueue(std::function<void(Args...)> const& work,
Args...args)
{
enqueue([=] { work(args...); });
}
enqueue([](int v) { std::cout << v; }, 42); // 编译不过这俩enqueue明显有推导关系 为啥编译不过呢,因为lambda可能匹配两个enqueue
需要一个限制
template<typename...Args>
void enqueue(
std::type_identity_t<
std::function<void(Args...)>
> const& work,
Args...args)
{
enqueue([=] { work(args...); });
}当然改成这样也行
template<typename...Args>
void enqueue(
std::function<void(
std::type_identity_t<Args>...
)> const& work,
Args...args)
{
enqueue([=] { work(args...); });
}当然还可以这样改
template<typename...Args>
void enqueue(
std::function<void(
std::decay_t<Args>...
)> const& work,
Args&&...args)
{
enqueue([work, ...args = std::forward<Args>(args)]
{ work(std::move(args)...); });
}当然也可以这样改 chatgpt老师教的
template<typename Func, typename... Args>
void enqueue(Func&& func, Args&&... args)
{
enqueue([=]() { std::invoke(std::forward<Func>(func), std::forward<Args>(args)...); });
}The limits of maybe_unused
不是特别好用,void忽略也能对服用
Destructuring Lambda Expression Parameters
结构化绑定很好用
int sum(tuple<int, int, int> triple) {
auto [a, b, c] = triple;
return a + b + c;
}结构化绑定的值如果能直接传给lambda是不是很帅
比如这样
extern bool is_good(string s, int v);
auto foo(map<string, int> items) {
return views::filter(
items,
// DOES NOT WORK!
[](auto [key, value]) {
return is_good(key, value);
});
}
写一个转发吧,其实就是
inline constexpr struct {
template <typename F>
constexpr auto operator%(F&& fn) const {
return [fn](auto&& tpl) {
return std::apply(fn, FWD(tpl));
};
}
} spread_args;
上面的代码就可以这样了
auto foo(map<string, int> items) {
return views::filter(
items,
// Works!
spread_args % [](auto key, auto value) {
return is_good(key, value);
});
}甚至可以更简单点
auto foo(map<string, int> items) {
return views::filter(items, spread_args % is_good);
}Scan HTML faster with SIMD instructions: Chrome edition
常规
void NaiveAdvanceString(const char *&start, const char *end) {
for (;start < end; start++) {
if(*start == '<' || *start == '&'
|| *start == '\r' || *start == '\0') {
return;
}
}
}常规sse
void AdvanceString(const char*& start, const char* end) {
const __m128i quote_mask = _mm_set1_epi8('<');
const __m128i escape_mask = _mm_set1_epi8('&');
const __m128i newline_mask = _mm_set1_epi8('\r');
const __m128i zero_mask = _mm_set1_epi8('\0');
static constexpr auto stride = 16;
for (; start + (stride - 1) < end; start += stride) {
__m128i data = _mm_loadu_si128(
reinterpret_cast<const __m128i*>(start));
__m128i quotes = _mm_cmpeq_epi8(data, quote_mask);
__m128i escapes = _mm_cmpeq_epi8(data, escape_mask);
__m128i newlines = _mm_cmpeq_epi8(data, newline_mask);
__m128i zeros = _mm_cmpeq_epi8(data, zero_mask);
__m128i mask = _mm_or_si128(_mm_or_si128(quotes, zeros),
_mm_or_si128(escapes, newlines));
int m = _mm_movemask_epi8(mask);
if (m != 0) {
start += __builtin_ctz(m);
return;
}
}
// Process any remaining bytes (less than 16)
while (start < end) {
if (*start == '<' || *start == '&'
|| *start == '\r' || *start == '\0') {
return;
}
start++;
}
}查表 sse
void AdvanceStringTable(const char *&start, const char *end) {
uint8x16_t low_nibble_mask = {0b0001, 0, 0, 0, 0, 0, 0b0100,
0, 0, 0, 0, 0, 0b0010, 0b1000, 0, 0};
uint8x16_t high_nibble_mask = {0b1001, 0, 0b0100, 0b0010,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};
uint8x16_t v0f = vmovq_n_u8(0xf);
uint8x16_t bit_mask = {16, 15, 14, 13, 12, 11, 10, 9, 8,
7, 6, 5, 4, 3, 2, 1};
static constexpr auto stride = 16;
for (; start + (stride - 1) < end; start += stride) {
uint8x16_t data = vld1q_u8(reinterpret_cast<const uint8_t *>(start));
uint8x16_t lowpart = vqtbl1q_u8(low_nibble_mask, vandq_u8(data, v0f));
uint8x16_t highpart = vqtbl1q_u8(high_nibble_mask,
vshrq_n_u8(data, 4));
uint8x16_t classify = vandq_u8(lowpart, highpart);
uint8x16_t matchesones = vtstq_u...C++ 中文周刊 2024-06-02 第159期
本期文章由 HNY 404 赞助
资讯
标准委员会动态/ide/编译器信息放在这里
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-05-29 第256期
P3292R0 Provenance and Concurrency
这个论文讲了一种场景,这个场景其实也不算啥问题,然后也没提出啥解决方案,也没有啥好解决的方案,当前场景对服用也不是不行
分享给大家浪费一下大家时间
文章
C++23: chrono related changes
chrono相关改动
- 修复缺陷:自动本地化
std::locale::global(std::locale("ru_RU"));
using sec = std::chrono::duration<double>;
auto s_std = std::format("{:%S}", sec(4.2)); // s == "04.200" (not localized)
auto s_std2 = std::format("{:L%S}", sec(4.2)); // s == "04,200" (localized)
std::string s_fmt = fmt::format("{:%S}", sec(4.2)); // s == "04.200" (not localized)第四行c++20会挂,新版本强制自动本地化,如果你不想要这种行为,自己手动format
- 澄清本地化的编码格式兼容问题
对于语言,存在本地编码和文字编码不匹配的问题??
std::locale::global(std::locale("Russian.1251"));
auto s = std::format("День недели: {:L}", std::chrono::Monday);这个就会乱码,因为俄语的星期一有两种符号一个是utf8的一个不是
很抽象
- 放松clock要求
现在只要支持now就行
An Extensive Benchmark of C and C++ Hash Tables
他这个压测场景和数据非常详细。非常不错
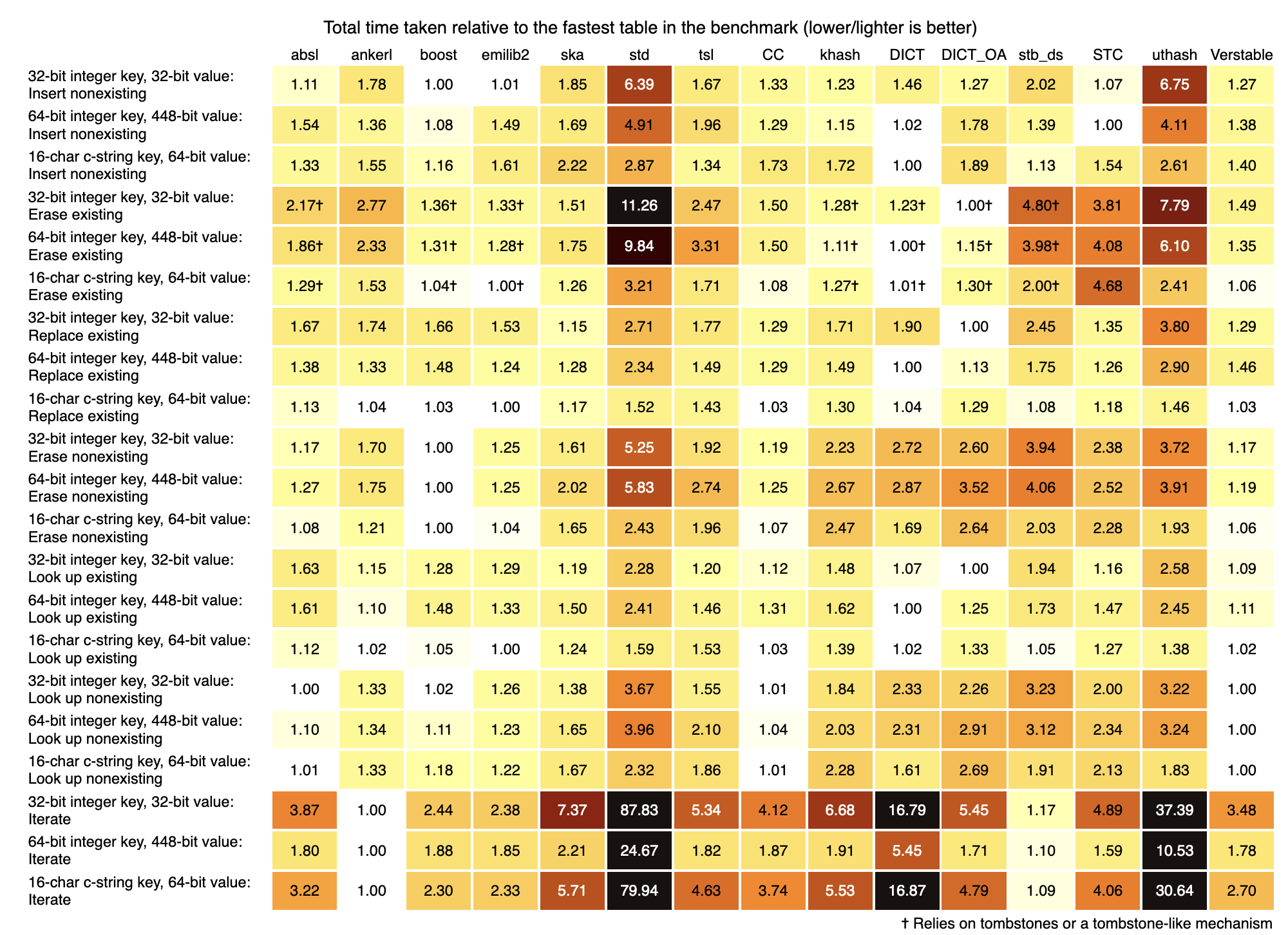
看图来说 boost unordered map性能不错
多线程的hashmap比如tbb boost concurrency unorderedmap folly map之类 的压测,没有
感觉这个还是挺值得测的
另外这里没有folly f14, 感觉可以加一下 (感谢mwish指出)
Quickly checking whether a string needs escaping
简单实现可能是这样
bool simple_needs_escaping(std::string_view v) {
for (char c : v) {
if ((uint8_t(c) < 32) | (c == '"') | (c == '\\')) {
return true;
}
}
return false;
}优化一下,去掉分枝
bool branchless_needs_escaping(std::string_view v) {
bool b = false;
for (char c : v) {
b |= ((uint8_t(c) < 32) | (c == '"') | (c == '\\'));
}
return b;
}更自然的,查表
static constexpr std::array<uint8_t, 256> json_quotable_character =
[]() constexpr {
std::array<uint8_t, 256> result{};
for (int i = 0; i < 32; i++) {
result[i] = 1;
}
for (int i : {'"', '\\'}) {
result[i] = 1;
}
return result;
}
();
bool table_needs_escaping(std::string_view view) {
uint8_t needs = 0;
for (uint8_t c : view) {
needs |= json_quotable_character[c];
}
return needs;
}更更自然的,simd
inline bool simd_needs_escaping(std::string_view view) {
if (view.size() < 16) {
return simple_needs_escaping(view);
}
size_t i = 0;
__m128i running = _mm_setzero_si128();
for (; i + 15 < view.size(); i += 16) {
__m128i word = _mm_loadu_si128((const __m128i *)(view.data() + i));
running = _mm_or_si128(running, _mm_cmpeq_epi8(word, _mm_set1_epi8(34)));
running = _mm_or_si128(running, _mm_cmpeq_epi8(word, _mm_set1_epi8(92)));
running = _mm_or_si128(
running, _mm_cmpeq_epi8(_mm_subs_epu8(word, _mm_set1_epi8(31)),
_mm_setzero_si128()));
}
if (i < view.size()) {
__m128i word =
_mm_loadu_si128((const __m128i *)(view.data() + view.length() - 16));
running = _mm_or_si128(running, _mm_cmpeq_epi8(word, _mm_set1_epi8(34)));
running = _mm_or_si128(running, _mm_cmpeq_epi8(word, _mm_set1_epi8(92)));
running = _mm_or_si128(
running, _mm_cmpeq_epi8(_mm_subs_epu8(word, _mm_set1_epi8(31)),
_mm_setzero_si128()));
}
return _mm_movemask_epi8(running) != 0;
}性能就不说了。看有没有必要吧,没有必要的话最多无分支版本哈,代码太多了,收益不大。当然性能肯定是simd最快
感兴趣自己玩一下 代码
Function Composition and the Pipe Operator in C++23 – With std::expected
实现shell管道用法
#include <iostream>
#include <functional>
#include <string>
#include <concepts>
#include <random>
#include <expected>
template < typename T >
concept is_expected = requires( T t ) {
typename T::value_type; // type requirement – nested member name exists
typename T::error_type; // type requirement – nested member name exists
requires std::is_constructible_v< bool, T >;
requires std::same_as< std::remove_cvref_t< decltype(*t) >, typename T::value_type >;
requires std::constructible_from< T, std::unexpected< typename T::error_type > >;
};
template < typename T, typename E, typename Function >
requires std::invocable< Function, T > &&
is_expected< typename std::invoke_result_t< Function, T > >
constexpr auto operator | ( std::expected< T, E > && ex, Function && f )
-> typename std::invoke_result_t< Function, T > {
return ex ? std::invoke( std::forward< Function >( f ),
* std::forward< std::expected< T, E > >( ex ) ) : ex;
}
// We have a data structure to process
struct Payload {
std::string fStr{};
int fVal{};
};
// Some error types just for the example
enum class OpErrorType : unsigned char { kInvalidInput, kOverflow, kUnderflow };
// For the pipe-line operation - the expected type is Payload,
// while the 'unexpected' is OpErrorType
using PayloadOrError = std::expected< Payload, OpErrorType >;
PayloadOrError Payload_Proc_1( PayloadOrError && s ) {
if( ! s )
return s;
++ s->fVal;
s->fStr += " proc by 1,";
std::cout << "I'm in Payload_Proc_1, s = " << s->fStr << "\n";
return s;
}
PayloadOrError Payload_Proc_2( PayloadOrError && s ) {
if( ! s )
return s;
++ s->fVal;
s->fStr += " proc by 2,";
std::cout << "I'm in Payload_Proc_2, s = " << s->fStr << "\n";
// Emulate the error, at least once in a while ...
std::mt19937 rand_gen( std::random_device {} () );
return ( rand_gen() % 2 ) ? s :
std::unexpected { rand_gen() % 2 ?
OpErrorType::kOverflow : OpErrorType::kUnderflow };
}
PayloadOrError Payload_Proc_3( PayloadOrError && s ) {
if( ! s )
return s;
s->fVal += 3;
s->fStr += " proc by 3,";
std::cout << "I'm in Payload_Proc_3, s = " << s->fStr << "\n";
return s;
}
void Payload_PipeTest() {
static_assert( is_expected< PayloadOrError > ); // a short-cut to verify the concept
auto res = PayloadOrError { Payload { "Start string ", 42 } } |
Payload_Proc_1 | Payload_Proc_2 | Payload_Proc_3 ;
// Do NOT forget to check if there is a value before accessing that value (otherwise UB)
if( res )
std::cout << "Success! Result of the pipe: fStr == " << res->fStr << " fVal == " << res->fVal;
else
switch( res.error() ) {
case OpErrorType::kInvalidInput: std::cout << "Error: OpErrorType::kInvalidInput\n"; break;
case OpErrorType::kOverflow: std::cout << "Error: OpErrorType::kOverflow\n"; break;
case OpErrorType::kUnderflow: std::cout << "Error: OpErrorType::kUnderflow\n"; break;
default: std::cout << "That's really an unexpected error ...\n"; break;
}
}
int main() { Payload_PipeTest(); }揭秘C++:虚假的零成本抽象
标题党
Hydra: 窥孔优化泛化
看不懂
开源项目介绍
互动环节
C++ 中文周刊 2024-05-25 第158期
本期文章由 HNY 赞助, 本期内容很少
资讯
标准委员会动态/ide/编译器信息放在这里
基本就是range constract executor 相关提案乱炖
讲几个R0
-
executor还没定,基于他的async object就来了。大概意思就是move only function封装用executor来管理/分配内存/生命周期管理,作者还给了POC 没有细看
简单来说就是针对类级别的更精细的内存控制
operator new(sizeof(T), type_identity<T>{}, args…)通常这种都是自己搞个数组placement new
提供根据类型的new接口,能更简单实现这种逻辑。看一乐,提供一种思路
这个其实就是很多指针实际上更多是抽象的,可以利用bit做事,但标准对这块不是很清晰,算是UB吧
比如llvm的PointerIntPair arm的MTE hash trie的指针管理 或者pointer swizzle技巧那种把指针搞出复合语义
这种玩意其实就是tag pointer,不同tag表达不同含义,感觉标准化会更好一些
浮点数的min/max处理了太多边角场景(NaN之类的),不够快,不想用ffastmath情况下提供了一套新接口
帮你把optional variant any里的T掏出来。这个很干净
帮P2786加了个接口实现P1144相同能力。看不懂?没事我也不懂
编译器信息最新动态推荐关注hellogcc公众号 本周更新 2024-0522第255期
文章
超好用的 C++ 在线编译器(VSCode 版)
godbolt集成vscode了,挺好的
C++神秘学习——memcpy的一个ub
memcpy data()了,编译器假设不空优化导致asan报错
vector string当buffer没问题,都用他们当buffer不用他们的成员函数复制是怎么个意思,瞧不起assign?
这个也和群友激烈讨论了
笔者的个人观点,data()虽然不是const,但是最好最好不乱玩,能用成员用成员,实在不行才hack,比如resize这种
assign肯定也是memcpy,他会帮你判断的,你直接拿来用,那肯定说明不为空,那编译器的假设笔者认为没毛病
write()和mmap写混用与cache alias
学到了
SLUB 分配器的下一步计划
看一乐
C++无锁(lock free)数据结构与有锁数据结构相比,速度,性能等有何区别?多线程中如何选择?
看一乐
long double to_string会丢失精度?
#include <string>
#include <iostream>
#include <iomanip>
using namespace std;
int main() {
long double d = -20704.000055577169;
string s = to_string(d);
cout << s << endl;//-20704.000056
cout << setprecision(12) << fixed << s << endl;
}两个输出没有差别。注意这个坑 godbolt
Looking up a C++ Hash Table with a pre-known hash
如果你知道了hash,如何避免容器计算hash?定制Equal,把hash比较也放进去,直接看完整代码
template<typename Hash>
class KeyHashPair {
private:
std::string_view key_;
std::size_t hash_;
public:
KeyHashPair() = delete;
KeyHashPair(std::string_view sv) : key_(sv), hash_(Hash{}(key_)) {}
std::string_view key() const { return key_; }
std::size_t hash() const { return hash_; }
};
struct Hash {
using is_transparent = void;
std::size_t operator()(std::string_view sv) const {
return std::hash<std::string_view>{}(sv);
}
std::size_t operator()(KeyHashPair<Hash> pair) const {
return pair.hash();
}
};
struct KeyEqual {
using is_transparent = void;
bool operator()(std::string_view lhs, std::string_view rhs) const {
return lhs == rhs;
}
template<typename Hash>
bool operator()(KeyHashPair<Hash> lhs, std::string_view rhs) const {
return lhs.key() == rhs;
}
};
using Set = std::unordered_set<std::string, Hash, KeyEqual>;
int main() {
Set set{"foo"};
const std::string string{"foo"};
const KeyHashPair<Set::hasher> pair{string};
assert(set.contains(pair));
}还是有点思路提升的,但并没有把hash存下来,其实更合理的思路是直接比较set内部的hash,可惜没有暴露
开源项目介绍
- asteria 一个脚本语言,可嵌入,长期找人,希望胖友们帮帮忙,也可以加群753302367和作者对线
- quill 4.0发布 编译时间 写入速度双提升
- ipvar 多进程共享变量,没明白什么场景用得上
工作招聘
互动环节
和群友聊天聊到了某些爱装逼的人,发现每一代学生都是这样的思维,沉迷某些技术 术语,爱装逼
虽然笔者讲出来有一点好为人师的感觉,但我还是很后悔大学浪费很多时间在嘴贫装逼上的。
那么问题来了,咱们读者是学生还是工作党,如果是学生,本周刊对你有没有收益?还是在咱这里学装逼来了,切记低调别装逼
如果不懂或者认为笔者有错误,大胆评论区指出,谢谢先,千万别模棱两可混过去了,笔者也不一定懂