I have recently contributed to veles, a more mature version of this. You should probably check it out, it has a bunch more awesome.
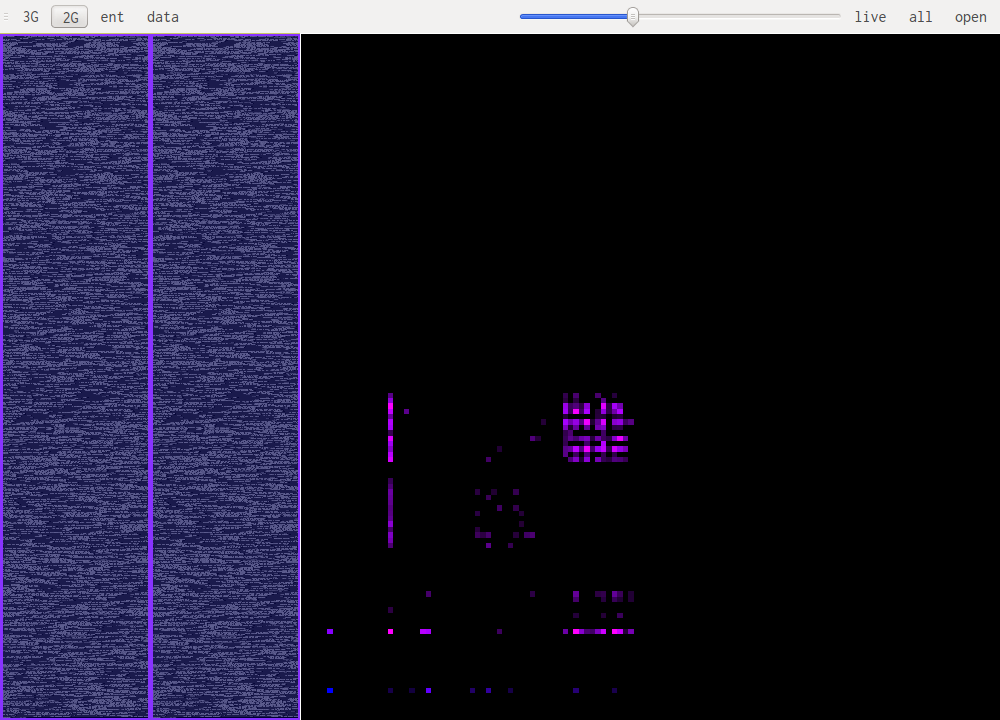
binglide is a visual reverse engineering tool. It is designed to offer a quick overview of the different data types that are present in a file. The screenshot bellow shows a small portion of the php5 binary that has a weird signature pattern:

This tool does not know about any particular file format, everything is done using the same analysis working on the data. This means it works even if headers are missing or corrupted or if the file format is unknown.
This first version of binglide was part of a project for my M.Sc. in the School of Computing of the University of Kent, in Canterbury, UK. I'd like to thank Dr. Julio Hernandez Castro for introducing me to the field of Visual Reverse Engineering and for his feedback on my work. I'm planning on doing a second version with more features and rich user interface so if you have any requests feel free to create an issue for that.
- PyQt4
- pyqtgraph
- numpy
- numba
binglide uses python3, be careful to install packages for that version of python. The basic libraries used by binglide are numpy and pyqtgraph. pyqtgraph needs pyqt4 and pyqt4.opengl, these can't be installed through pip as far as I know. However without the JIT optimisations this will be quite slow, for this the numba library is used. https://github.com/numba/numba (install instructions not included here!)
If there are problems with those instructions please report them on the issue. I can't test all distros.
This is tested on Ubuntu but might work for similar distributions. It shouldn't be hard to extrapolate what you need for other distributions. We just need to get all the requirements working and then setup binglide using setup.py.
git clone https://github.com/wapiflapi/binglide
sudo apt-get install python3-pyqt4 python3-pyqt4.qtopengl python3-opengl
sudo pip3 install pyqtgraph numpy
cd ./binglide && \
sudo python3 setup.py install
git clone https://github.com/wapiflapi/binglide
sudo yum -y install python3-pip python3-PyQt4 python3-PyOpenGL python3-numpy python3-scipy
sudo pip-python3 install pyqtgraph
cd ./binglide && \
sudo python3 setup.py install
Binglide was developed in order to better understand the algorithms that have been used in other projects, here is a non-exclusive list of projects and people this was inspired by.
-
Cantor Dust hasn't been released but the glimpses we got to see from the project at various conferences greatly inspired the GUI of binglide and its beauty is something to strive for.
-
binvis one of the currently available tools that presents the most visualizations and whose authors have greatly contributed to the field.
-
binwalk a standard tool for reverse engineers its focus is not visualization but it still is an inspiration.
-
Aldo Cortesi does awesome work on visualizations and his work on Hilbert curves will be featured in the next versions of binglide.
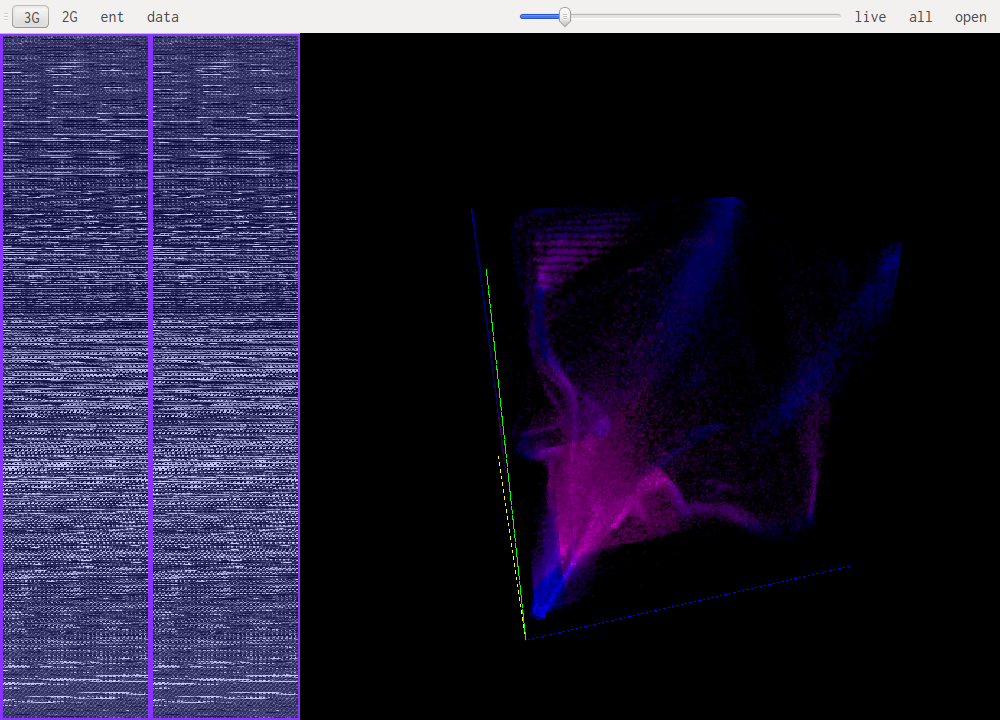
The main windows is split in three zones, the two on the left allow for selection of the part of the file that is being studied. The bigger pane on the right shows the results of the selected algorithm.
Data visualisation is the most basic of all views, it simply shows each byte as it is in the file, taking its value as a color: 0xff will be very bright, 0x00 will be black.
This uses a sliding window over the data to compute "local" Shannon entropy. The color represents the entropy, if it is dark then the data doesn't have high entropy, if it gets lighter the entropy increases.
This are the most useful views when it comes to identifying what kind of data one is looking at. The idea is to look at a histogram of bigrams or trigrams in the file. Those are represented in 2D or 3D.
This representation offers very visual patterns that are different enough from one data type to another to be easily recognized once you get used to them.
A data point in one of those views represents how often those bytes are found together. Data in pink is simply the printable ascii range.
For example this is a 2D representation of the histogram of bigrams in english text:
Notice the square representing the lowercase ascii letters that follow each other. Slightly to the left we see some traces of uppercase followed by lowercase and beneath that another, more subtle, square representing all caps words. The rest is mainly characters followed by spaces or other punctuation.
You can find screenshots of some common data types under the /samples/ directory.
Bytecode patterns are usually very similar even when looking at different architectures. This mean code in an unknown architecture might be recognized as code and at the same time with practice one can identify the architecture. Bellow is i386, x86_64 and powerpc in that order.
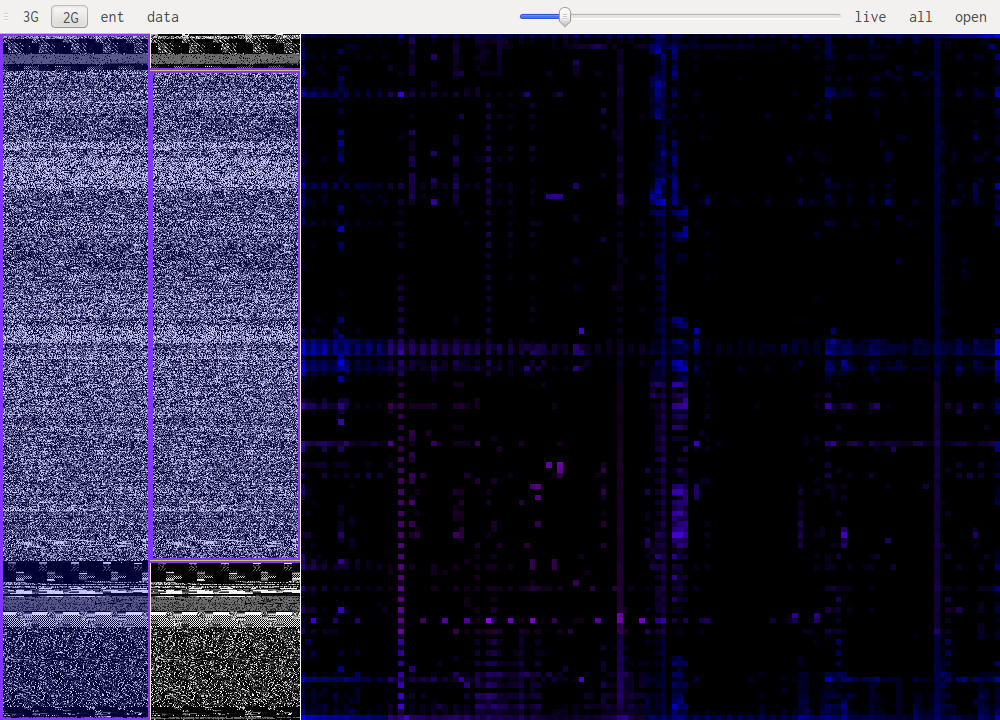
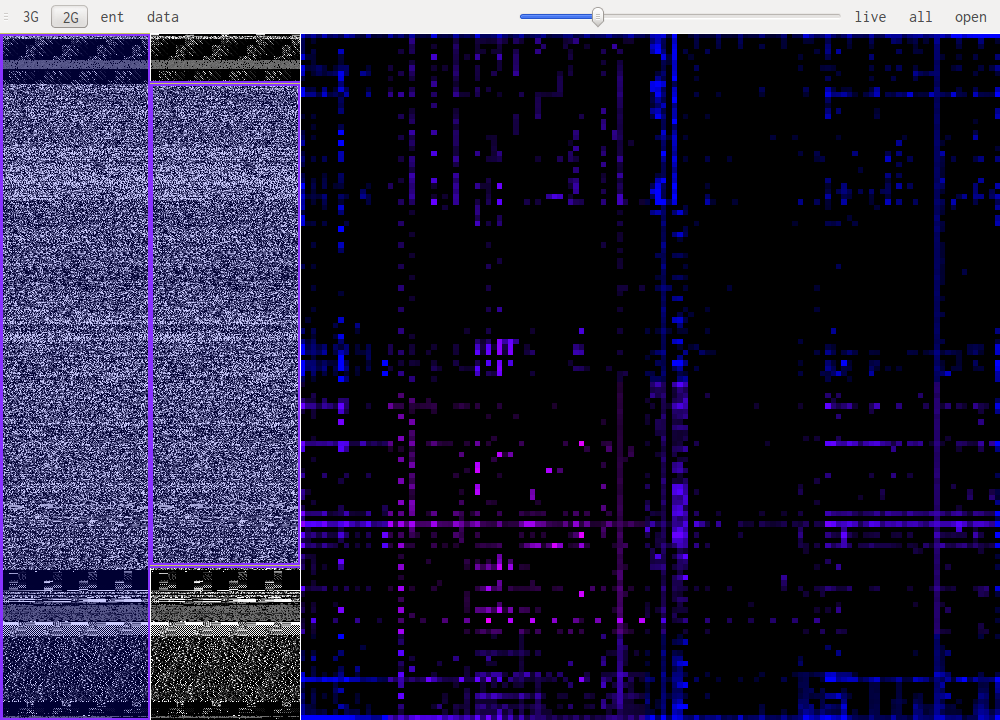
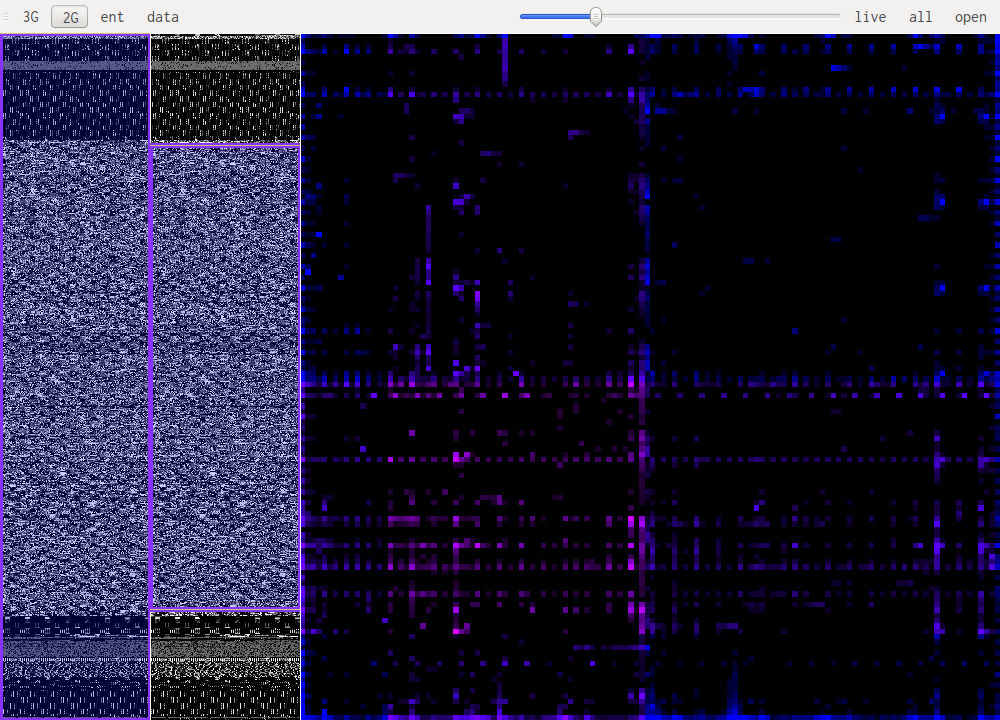
When looking at uncompressed images or sound the patterns are pretty similar. It is mainly a diagonal with some "organic" features, this is because the data doesn't change much from one point in the file to the next. One thing to notice is the number of channels the data is encoded with. Especially in 3D you can notice 3 distinct features when an image is encoded in RGB, these are the RGB, GBR and BRG trigrams. Another caveat is the presence of an (almost) unused channel, this happens with unused alpha channels, or sound encoded on 16bit but with the original data coming from an 8 bit source for example. In those cases one of the channels will almost never change thus projecting the whole histogram on a couple of planes in the 3D view. Here are some samples:
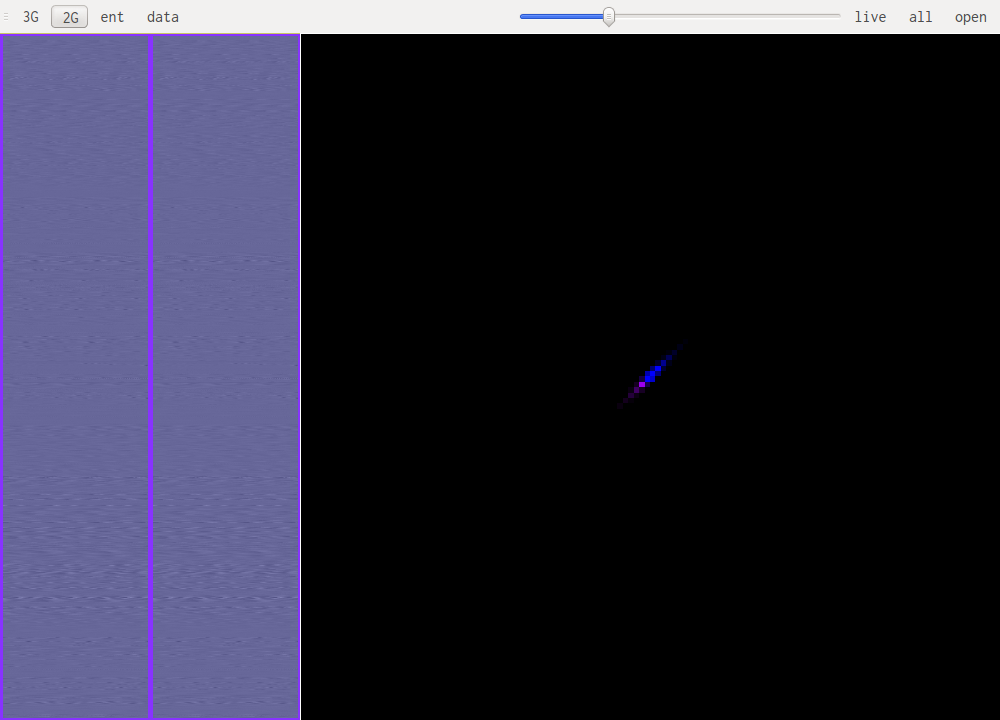 This is human speech, notice the very small range of values that are used.
This is human speech, notice the very small range of values that are used.
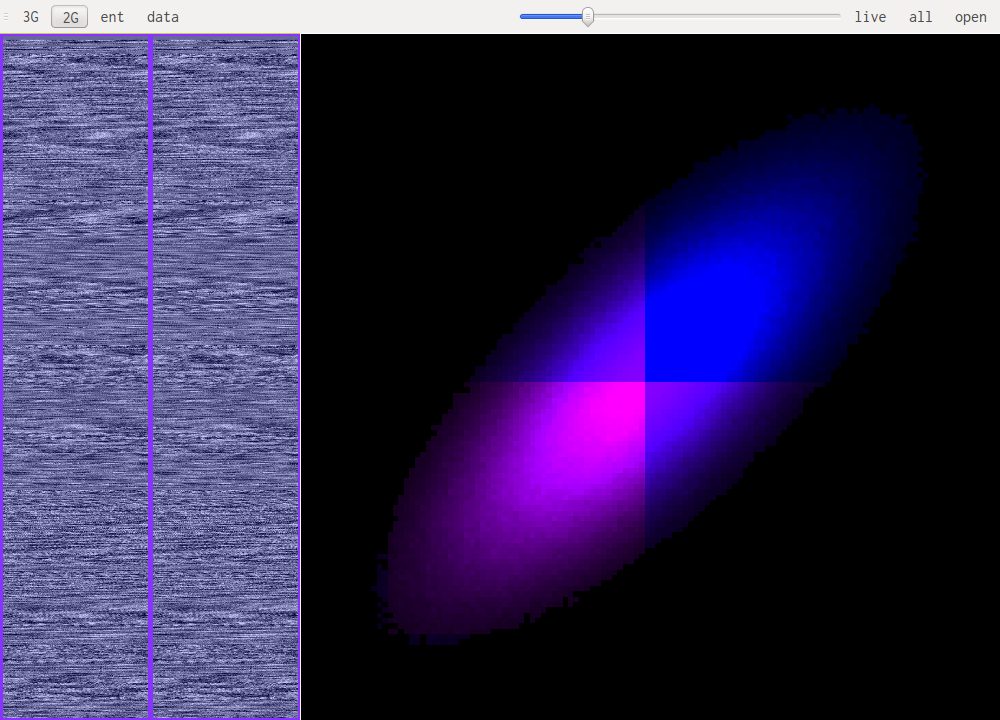 For reference this is rock music.
For reference this is rock music.
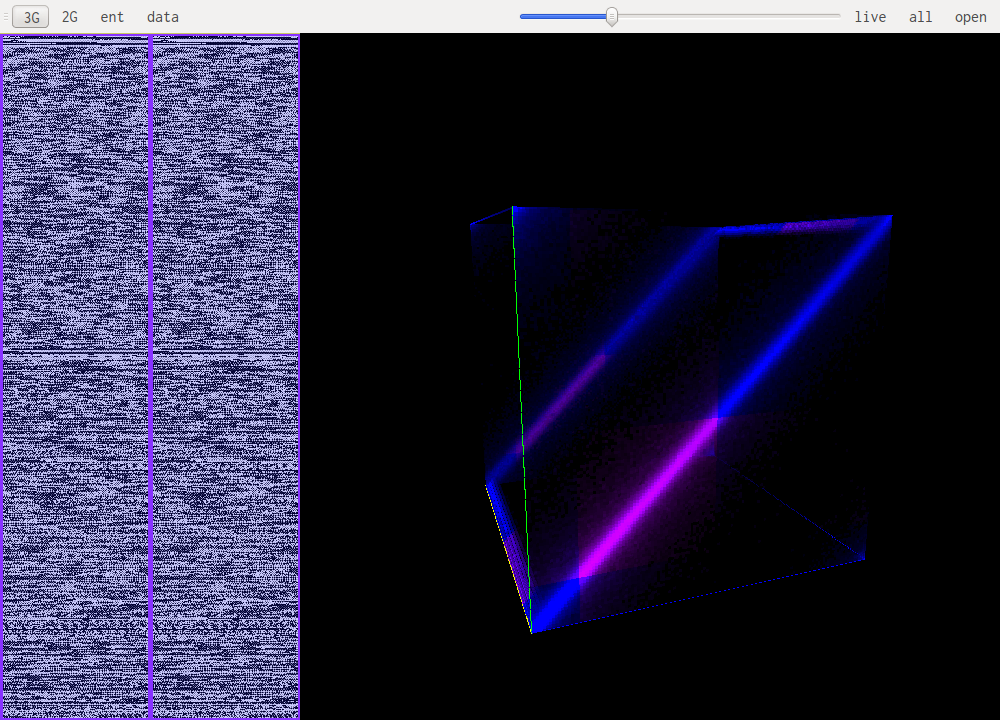 This is the same speech encoded on 16bit. Each high-order byte will be very close to 0xff or 0x00 because of the small amount of values that are actually used. Each being a signed uint16 close to 0. This is why this pattern emerges.
This is the same speech encoded on 16bit. Each high-order byte will be very close to 0xff or 0x00 because of the small amount of values that are actually used. Each being a signed uint16 close to 0. This is why this pattern emerges.
Images have the same diagonal shape but are much more organic.
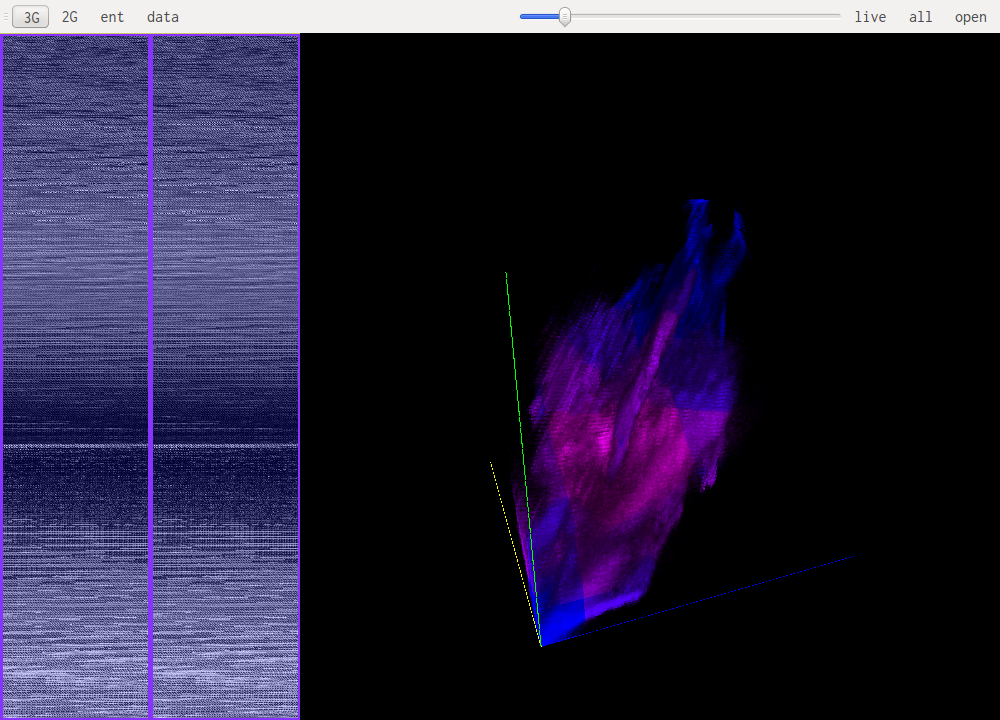
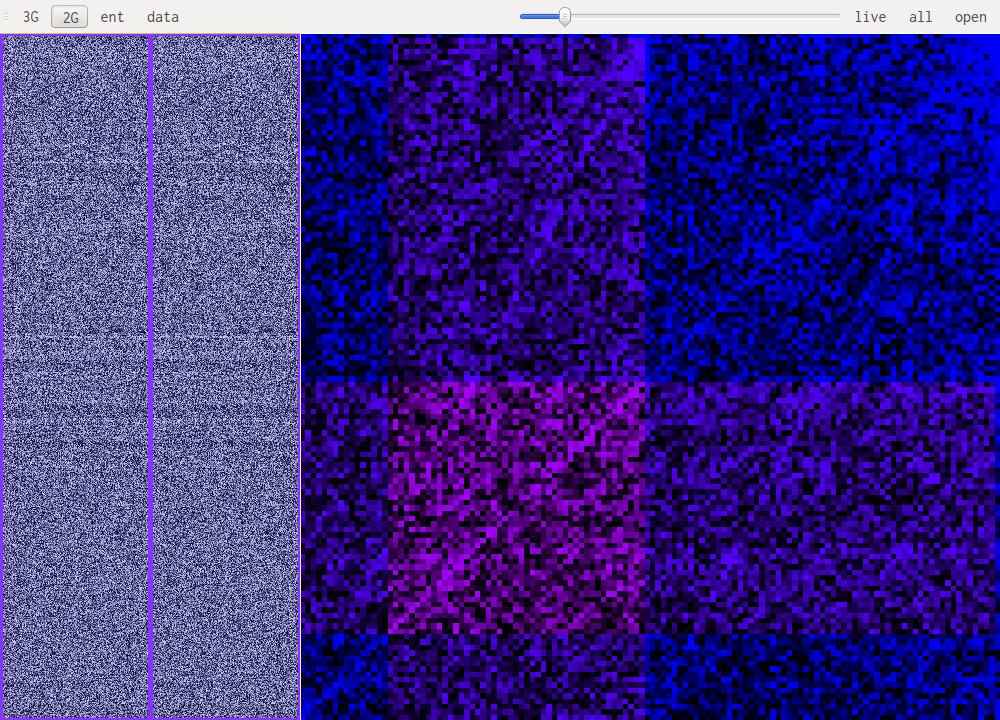
Compressed data almost looks like random data, which is expected. But some patterns can still be recognized.
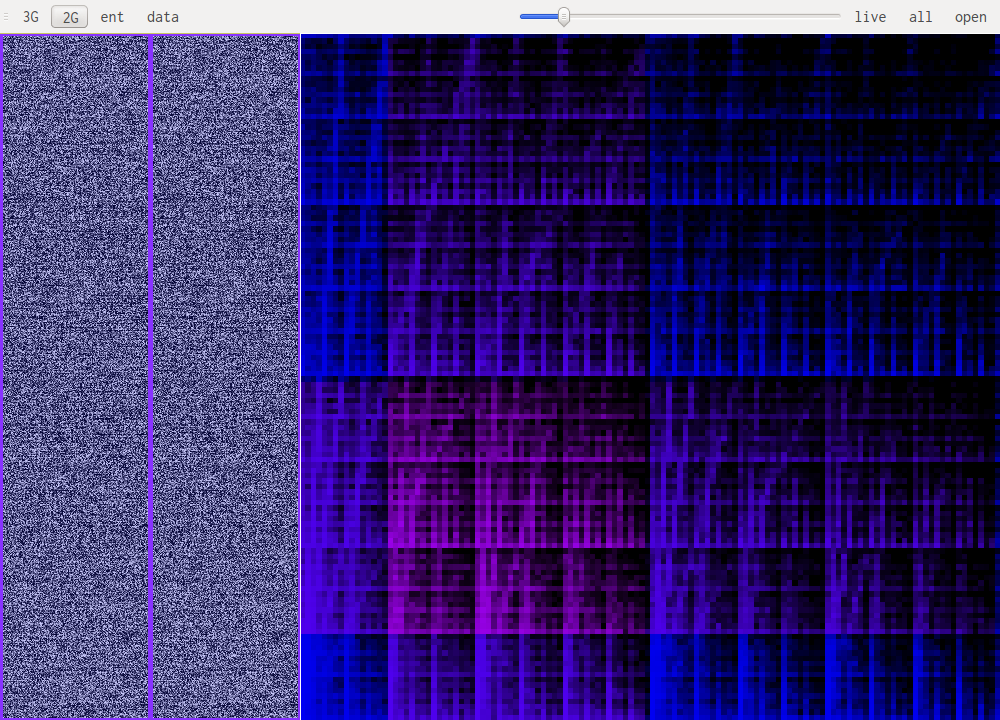
 The screenshot above shows gzip's deflate compression. Notice the lines going diagonally through the image.
The screenshot above shows gzip's deflate compression. Notice the lines going diagonally through the image.
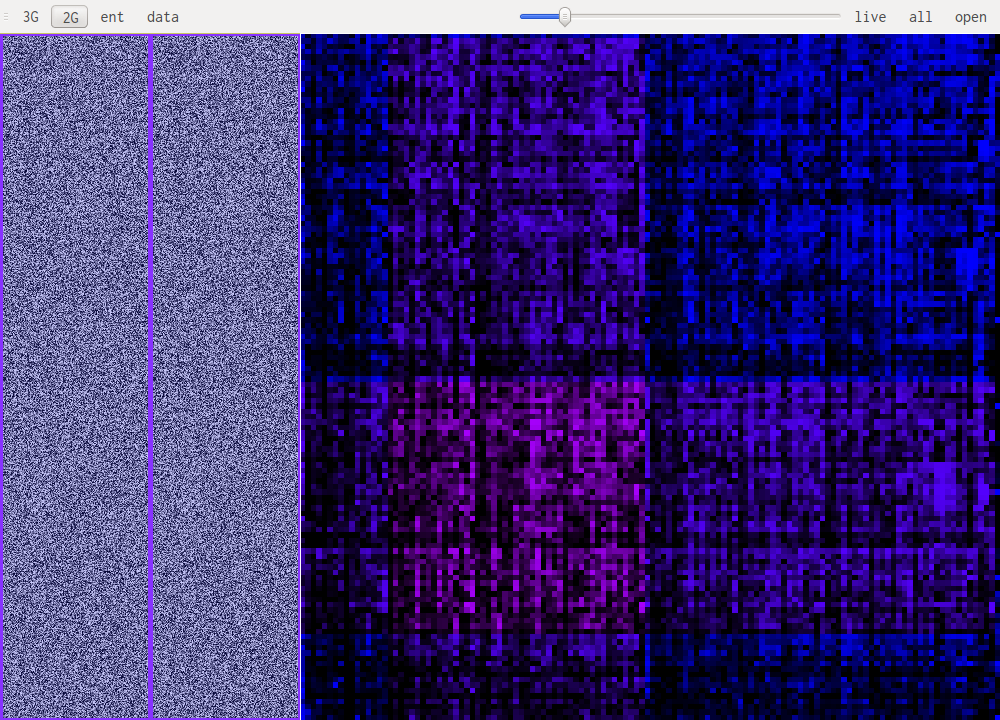 Those two images show gif and jpeg respectively.
Those two images show gif and jpeg respectively.