Personal reference repo for manipulating data in a database using Knex and PostgreSQL. Resources and review for SQL.
PostgreSQL is an open source relational database system.
- Download and set up postgreSQL locally and set up environement variables for Windows.
- Set
POSTGRES_DIRto point to the root folder of your Postgres install. - Create a
PGDATAenvironment variable that points to the folder that database files are stored in. Add a new entry forPGDATAsetting it to%POSTGRES_DIR%/data. - Edit the
PATHvariable in order to run Postgres commands likepsql,pg_ctl,createuser, andcreatedbfrom the command line. - Edit the existing
PATHvariable by appending%POSTGRES_DIR%\bin. - Set up
pgpass.conf(tells the Postgres client what password to use when attempting to connect to our local server as the postgres) andpg_hba.conffiles.
Knex.js is a SQL query builder for Postgres, MSSQL, MySQL, MariaDB, SQLite3, Oracle, and Amazon Redshift.
- Run
npm install knex --save - Run
npm install pg - Initialize the library inside file:
require('dotenv').config();
const knex = require('knex');
const knexInstance = knex({
client: 'pg',
connection: process.env.DATABASE_URL,
});- Open command prompt and run
pg_ctl start - Run
pg_ctl statusto check if server is running - Run
psqlorpsql -U postgresto connect with postgres
- Clone this repository to your local machine
[email protected]:williamwdev/sql-practice.git cdinto the cloned repository- Make a fresh start of the git history for this project with
rm -rf .git && git init - Install the node dependencies
npm install - Create your
.envfile to store your local settings - Edit the contents of the
package.jsonto use NEW-PROJECT-NAME instead of"name": "express-boilerplate",
- SQL (Structured Query Language) is a language designed to manage data in a RDBMS (Relational Database Management System). Allows us to interact with relational databases and tables in a way to glean specific and meaningful information
- Relational databases are systems for managing information and are made up of tables. Each column in the table has a name and a data type, and each row in the table is a specific instance of whatever the table is about.
- ERD (Entity Relationship Diagram) is a visual representation of the relationships among all relevant tables within a database
- Primary Key = unique identifier for each row in a table
- Foreign key = used to reference data in one table to those in another table
- Queries are statements constructed to get data from the database
- Most common kind of
JOINis theINNER JOINand the most common way to join tables is using primary key and foreign key columns - You can do joins on any columns, but the key columns are optimized for fast results
Database Related Commands
SHOW DATABASES;to see currently available databasesCREATE DATABASE <database_name>;to create a new databaseUSE <database_name>;to select a database to useSOURCE <path_of_.sql_file>;to import SQL commands from .sql fileDROP DATABASE <database_name>;to delete a database
Table Related Commands
SHOW TABLESto see currently available tables in a database- To create a new table:
CREATE TABLE <table_name1> (
<col_name1> <col_type1>,
<col_name2> <col_type2>,
<col_name3> <col_type3>
PRIMARY KEY (<col_name1>),
FOREIGN KEY (<col_name2>) REFERENCES <table_name2>(<col_name2>)
);Integrity contraints in CREATE TABLE
- NOT NULL
- PRIMARY KEY (col_name1, col_name2,...)
- FOREIGN KEY (col_namex1, …, col_namexn) REFERENCES table_name(col_namex1, …, col_namexn)
DESCRIBE <table_name>;to describe columns of a table- Insert into a table
INSERT INTO <table_name> (<col_name1>, <col_name2>, <col_name3>, …)
VALUES (<value1>, <value2>, <value3>, …);- Update a table
UPDATE <table_name>
SET <col_name1> = <value1>, <col_name2> = <value2>, ...
WHERE <condition>;- Delete all contents of a table
DELETE FROM <table_name>; - Delete a table
DROP TABLE <table_name>;
Querying Related Commands
- SELECT
SELECT <col_name1>, <col_name2>, …
FROM <table_name>;- SELECT DISTINCT
SELECT DISTINCT <col_name1>, <col_name2>, …
FROM <table_name>;- WHERE
SELECT <col_name1>, <col_name2>, …
FROM <table_name>
WHERE <condition>;- GROUP BY (often used with aggregate functions such as COUNT, MAX, MIN, SUM and AVG to group the result-set)
SELECT <col_name1>, <col_name2>, …
FROM <table_name>
GROUP BY <col_namex>;- HAVING
SELECT <col_name1>, <col_name2>, ...
FROM <table_name>
GROUP BY <column_namex>
HAVING <condition>- ORDER BY (sort a result set in ascending or descending order)
SELECT <col_name1>, <col_name2>, …
FROM <table_name>
ORDER BY <col_name1>, <col_name2>, … ASC|DESC;- BETWEEN (used to select data within a given range)
SELECT <col_name1>, <col_name2>, …
FROM <table_name>
WHERE <col_namex> BETWEEN <value1> AND <value2>;- LIKE (used in a WHERE clause to search for a specified pattern in text)
- % (Zero, one, or multiple characters)
- _(A single character)
SELECT <col_name1>, <col_name2>, …
FROM <table_name>
WHERE <col_namex> LIKE <pattern>;- IN (allow multiple values within a WHERE clause)
SELECT <col_name1>, <col_name2>, …
FROM <table_name>
WHERE <col_namen> IN (<value1>, <value2>, …);- JOIN (used to combine values of two or more tables based on common attributes within them)

SELECT <col_name1>, <col_name2>, …
FROM <table_name1>
JOIN <table_name2>
ON <table_name1.col_namex> = <table2.col_namex>;- Views (virtual SQL tables created using a result set of a statement)
CREATE VIEW <view_name> AS
SELECT <col_name1>, <col_name2>, …
FROM <table_name>
WHERE <condition>;DROP VIEW <view_name>;- Aggregate Functions
- COUNT(col_name) — Returns the number of rows
- SUM(col_name) — Returns the sum of the values in a given column
- AVG (col_name)— Returns the average of the values of a given column
- MIN(col_name) — Returns the smallest value of a given column
- MAX(col_name) — Returns the largest value of a given column
- Nested Subqueries (SQL queries which include a SELECT-FROM-WHERE expression that is nested within another query)
SELECT DISTINCT course_id
FROM section
WHERE semester = ‘Fall’ AND year= 2009 AND course_id IN (
SELECT course_id
FROM section
WHERE semester = ‘Spring’ AND year= 2010
);LIKEcan be used with wildcards such as%and_to match various characters.- Aggregate functions take multiple rows of data and combine them into one number
COUNTis one of the most widely-used aggregate functionSELECT COUNT(col_name) FROM table- Null is the value of an empty entry.
SELECT (0 IS NOT NULL) AND ('' IS NOT NULL) COUNT(*)counts rows as long as ANY one of their columns is non-null.SELECT COUNT(*) FROM tableCASE WHENblock acts as a big if-else statement
CASE
WHEN <clause> THEN <result>
WHEN <clause> THEN <result>
...
ELSE <result>
ENDSELECT DISTINCTreturns unique entries (no duplication)GROUP BYallows us to split up the dataset and apply aggregate functions within each group, resulting in one row per groupHAVINGis useful for filtering result of grouping and aggregrationJOINSare used to create an augmented table because the original didn't contain the information we needed.
SELECT column, another_table_column, …
FROM mytable
INNER JOIN another_table
ON mytable.id = another_table.id
WHERE condition(s)
ORDER BY column, … ASC/DESC
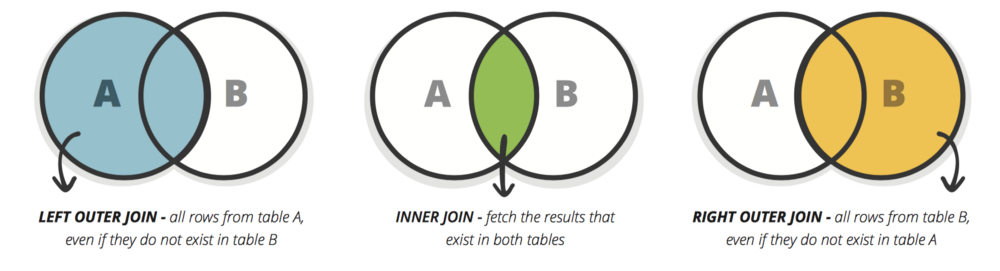
LIMIT num_limit OFFSET num_offset;INNER JOINis a process that matches rows from the first table and second table which have the same key (as defined by the ON constraint) to create a result row with the combined columns from both tables.INNER JOINandJOINare equivalentOUTER JOINis used when two tables have asymmetric data to ensure that the data you need is not left out of the results
SELECT column, another_column, …
FROM mytable
INNER/LEFT/RIGHT/FULL JOIN another_table
ON mytable.id = another_table.matching_id
WHERE condition(s)
ORDER BY column, … ASC/DESC
LIMIT num_limit OFFSET num_offset;- When joining table A to table B:
LEFT JOINsimply includes rows from A regardless of whether a matching row is found in BRIGHT JOINis the same, but reversed, keeping rows in B regardless of whether a match is found in AFULL JOINsimply means that rows from both tables are kept, regardless of whether a matching row exists in the other table- When using any of the above joins, you need to account and deal with
NULLin the result and constraints - When outer-joining two tables with asymmetric data, you can test a column for
NULLvalues in aWHEREclause by using either theIS NULLorIS NOT NULLconstraint
SELECT column, another_column, …
FROM mytable
WHERE column IS/IS NOT NULL
AND/OR another_condition
AND/OR …;ASkeyword is used to give descriptive alias to expressions used in theSELECTpart of the query
SELECT col_expression AS expr_description, …
FROM mytable;- Additionally, regular columns and tables can also have aliases to make them easier to reference in the output and helps in simplifying more complex queries
SELECT column AS better_column_name, …
FROM a_long_widgets_table_name AS mywidgets
INNER JOIN widget_sales
ON mywidgets.id = widget_sales.widget_id;- Query with aggregate functions over all the rows
SELECT AGG_FUNC(column_or_expression) AS aggregate_description, …
FROM mytable
WHERE constraint_expression;- Common aggregate functions
COUNT(*), COUNT(column)= Common function used to count the number of rows in the group if no column name is specified. Otherwise, count the number of rows in the group with non-NULL values in the specified columnMIN(column)= Finds the smallest numerical value in the specified column for all rows in the groupMAX(column= Finds the largest numerical value in the specified column for all rows in the groupAVG(column)= Finds the average numerical value in the specified column for all rows in the groupSUM(column)= Finds the sum of all numerical values in the specified column for the rows in the group
- Grouped aggregate functions
SELECT AGG_FUNC(column_or_expression) AS aggregate_description, …
FROM mytable
WHERE constraint_expression
GROUP BY column;HAVINGclause is used specifically with theGROUP BYclause to allow us to filter grouped rows from the result set
SELECT group_by_column, AGG_FUNC(column_expression) AS aggregate_result_alias, …
FROM mytable
WHERE condition
GROUP BY column
HAVING group_condition;- Order of Execution of a Query (Each query begins with finding the data that we need in a database, and then filtering that data down into something that can be processed and understood as quickly as possible)
SELECT DISTINCT column, AGG_FUNC(column_or_expression), …
FROM mytable
JOIN another_table
ON mytable.column = another_table.column
WHERE constraint_expression
GROUP BY column
HAVING constraint_expression
ORDER BY column ASC/DESC
LIMIT count OFFSET COUNT;- In SQL, the database schema is what describes the structure of each table, and the datatypes that each column of the table can contain. This fixed structure is what allows a database to be efficient, and consistent despite storing millions or even billions of rows.
INSERTstatement with values for all columns
INSERT INTO mytable
VALUES (value_or_expr, another_value_or_expr, …),
(value_or_expr_2, another_value_or_expr_2, …),
…;INSERTstatement with specific columns (when you have incomplete data and the table contains columns that support default values)
INSERT INTO mytable
(column, another_column, …)
VALUES (value_or_expr, another_value_or_expr, …),
(value_or_expr_2, another_value_or_expr_2, …),
…;INSERTstatement with expressions (use mathematical and string expressions with the values that you are inserting)
INSERT INTO boxoffice
(movie_id, rating, sales_in_millions)
VALUES (1, 9.9, 283742034 / 1000000);UPDATEstatement with values (takes multiple column/value pairs, and applying those changes to each and every row that satisfies the constraint in theWHEREclause)
UPDATE mytable
SET column = value_or_expr,
other_column = another_value_or_expr,
…
WHERE condition;- NOTE: Always write the constraint first and test it in a
SELECTquery to make sure you are updating the right rows, and only then writing the column/value pairs to update DELETEstatement with condition (if there is noWHEREconstraint, then all rows will be removed)
DELETE FROM mytable
WHERE condition;- NOTE: Recommended to run the constraint in a
SELECTquery first to ensure that you are removing the right rows. Without a proper backup or test database, it is downright easy to irrevocably remove data so always read yourDELETEstatements wice and execute once. CREATE TABLEstatement with optional table constraint and default value
CREATE TABLE IF NOT EXISTS mytable (
column DataType TableConstraint DEFAULT default_value,
another_column DataType TableConstraint DEFAULT default_value,
…
);- Table data types
INTEGER,BOOLEAN= interger can store whole integer values like the count of a number or an age. Boolean value is just represented as an integer value of just 0 or 1FLOAT,DOUBLE,REAL= floating point datatypes can store more precise numerical data like measurements or fractional values.CHARACTER(num_chars),VARCHAR(num_chars),TEXT= text based datatypes can store strings and text in all sorts of locales. Both theCHARACTERandVARCHAR(variable character)types are specified with the max number of characters that they can store.DATE,DATETIME= SQL can also store data and time stamps to keep track of time series and event data. (Manipulating data across timezones can be tricky)BLOB= SQL can store binary data in blobs right in the database. These values are often opaque to the database, so you usually have to store them with the right metadata to requery them
- Table constraints
PRIMARY KEY= Values in this column are unique, and each value can be used to identify a single row in this tableAUTOINCREMENT= For integer values, this means that the value is automatically filled in and incremented with each row insertion.UNIQUE= Values in this column have to be unique, so you can't insert another row with the same value in this column as another row in the table. Differs from thePRIMARY KEYin that it doesn't have to be a key for a row in the tableNOT NULL= Inserted value can not beNULLCHECK(expression) = Allows you to run a more complex expression to test whether the values inserted are valid (check that values are positive, or greater than a specific size, or start with a certain prefix, etc)FOREIGN KEY= consisgtency check which ensures that each value in this column corresponds to another value in a column in another table.
- Example table schema
CREATE TABLE movies (
id INTEGER PRIMARY KEY,
title TEXT,
director TEXT,
year INTEGER,
length_minutes INTEGER
);ALTER TABLEto add new column(s)
ALTER TABLE mytable
ADD column DataType OptionalTableConstraint
DEFAULT default_value;ALTER TABLEto remove column(s)
ALTER TABLE mytable
DROP column_to_be_deleted;ALTER TABLEto rename table name
ALTER TABLE mytable
RENAME TO new_table_name;DROP TABLE IF EXISTSstatement removes an entire table including all of its data and metadata
DROP TABLE IF EXISTS mytable;- PostgreSQL 13.0 Documentation
- PostgreSQL Tutorial
- PostgreSQL tutorial cheat-sheet
- PostgreSQL cheat sheet
- PostgreSQL Exercises
- PostgreSQL Tutorialspoint
- SQLBolt - One of the better interactive interfaces for learning and practicing in browser
- Select Star SQL - Great resource for interactive learning
- SQL Murder Mystery - Amazing walkthrough
- SQL Cheat Sheet
- SQLZoo
- WebDevSimplified SQL
- SQL Database Programming eBook
- GalaXQL
- Mode SQL tutorial
- Datacamp intro to SQL
- SQLcourse
- SQLcourse 2
- Codeacademy
- SQL tutorial
- Kaggle SQL
- Kaggle Advanced SQL
- Studybyyourself
- Stratascratch
- Sololearn
- w3school
- SQLite