Collection of corpora for various languages downloaded from the Coursera site.
Blogs/News/Tweets corpora from SwiftKey.
4.3 million lines of text, over 100 million words.
10 percent of the total number of lines on each file was used.
Data cleaning tasks applied to the dataset are:
Convert the entire document to lower case.
Removing punctuation marks, numbers, extra whitespace, and single letters.
Katz Back-off approach based on a 4-gram
The algorithm takes a text / phrase and cleans it up with the same method used for cleaning the dataset.
Katz back-off starts looking for a match in the highest possible n-gram, until the lower level ngrams.
The probability of matches that appear in lower ngrams depends on the GT probability of the ngram, multiplied by Katz Alpha.
The generated predictions from all ngrams are sorted in descending order by Katz Probability
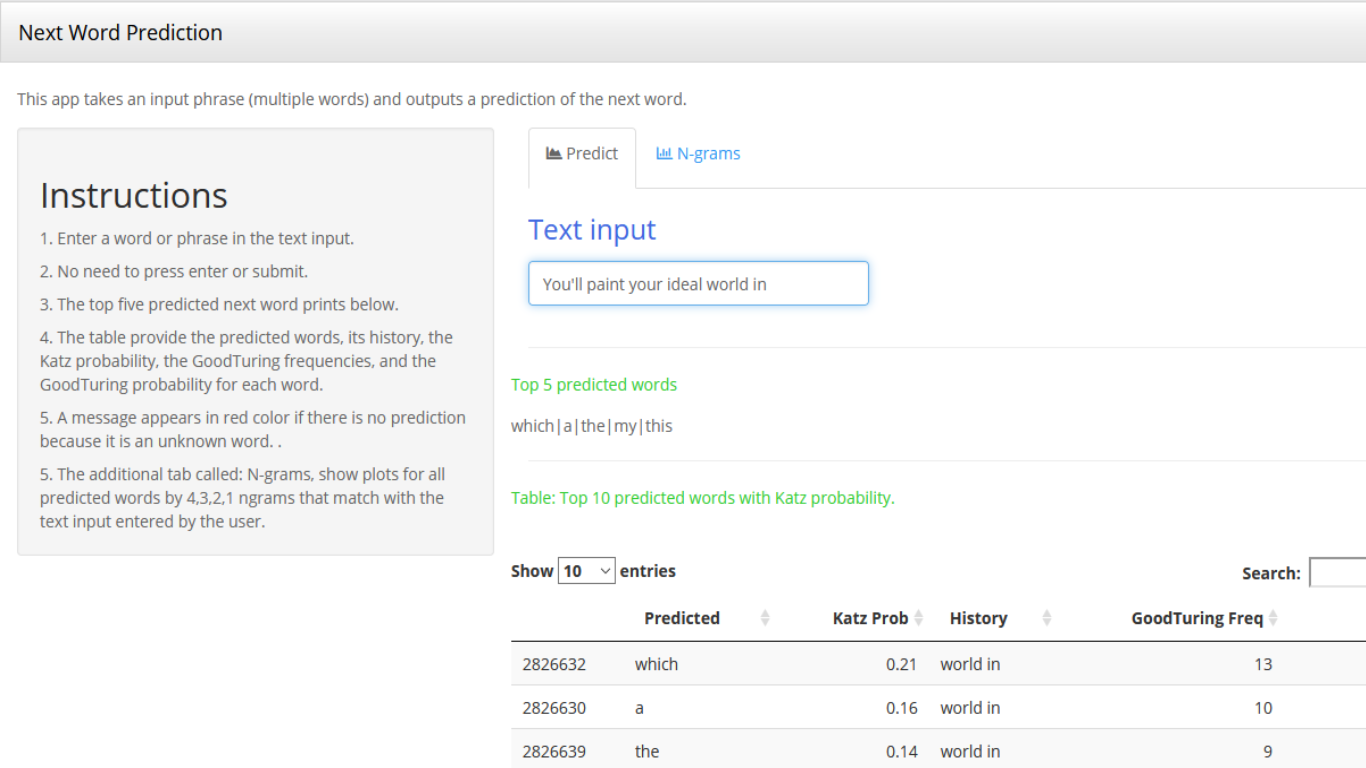
Shiny Application link: https://yaniela.shinyapps.io/PredictiveWordShinyApp/
Source code available on Github: https://github.com/yaniela/DataSciencieCapstoneProject
Reference:
Dobrinov, N.(2018). A Model to Predict the Next Word You Are Typing via Natural Language Processing in R
available in: https://nikdobri.shinyapps.io/wordpred3grm/_w_7ca01872/word.prediction.html.