{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Understand and the implement K-means clustering algorithm and group firms.
- Conduct Principal Component Analysis (PCA) to perform dimensionality reduction and visualize the groupings.
- Understand the benefits of using machine learning to group firms when defining fixed effects for regression models.
If you have any comments or suggestions, email me at [email protected].
In this notebook, I group US public firms by implementing the K-means unsupervised learning.
I form groups to construct fixed effects and use them in my UC Berkeley Haas PhD Dissertation (Yoon 2022). However, this code can be generalized and used in many other settings, such as customer/market segmentation and recommendation systems.
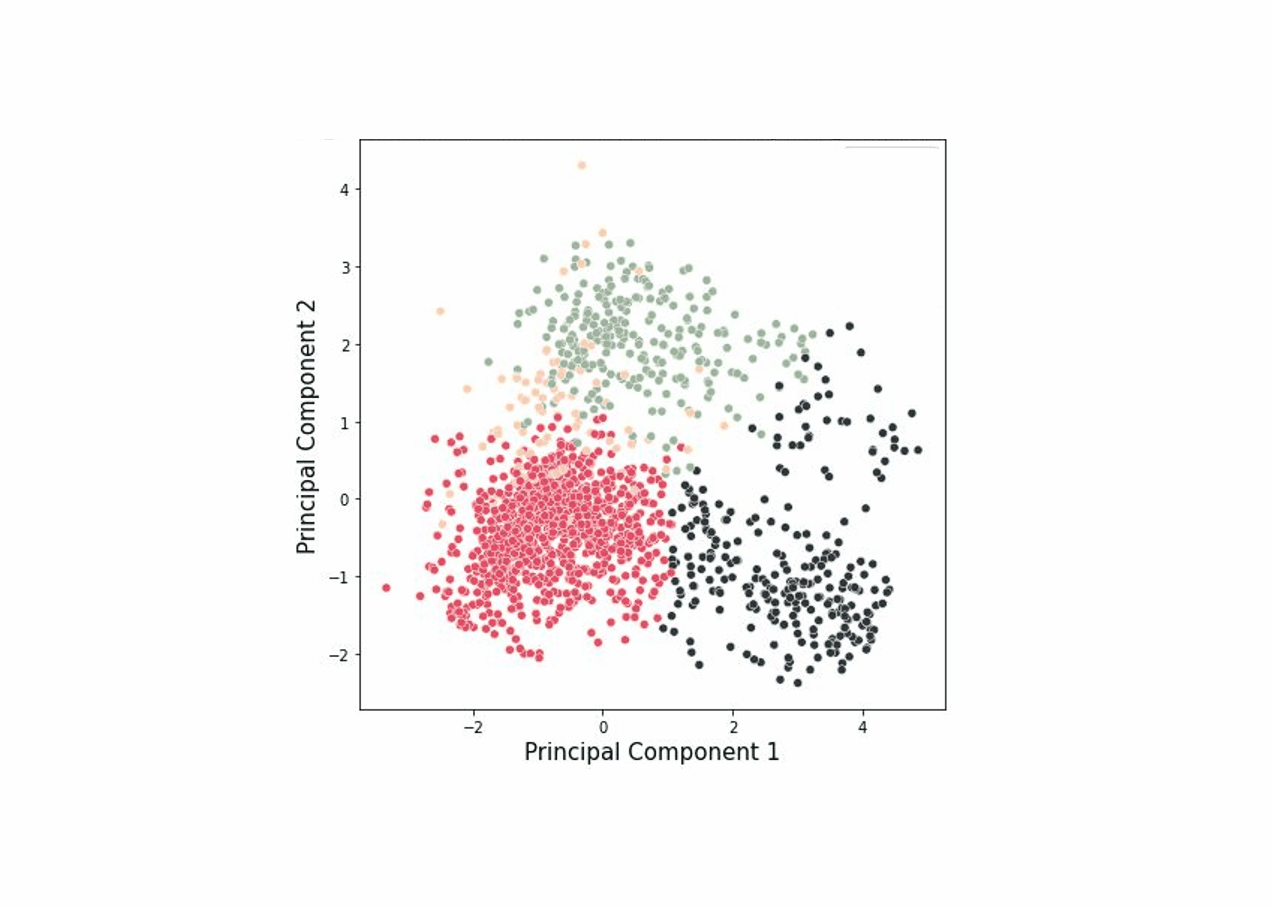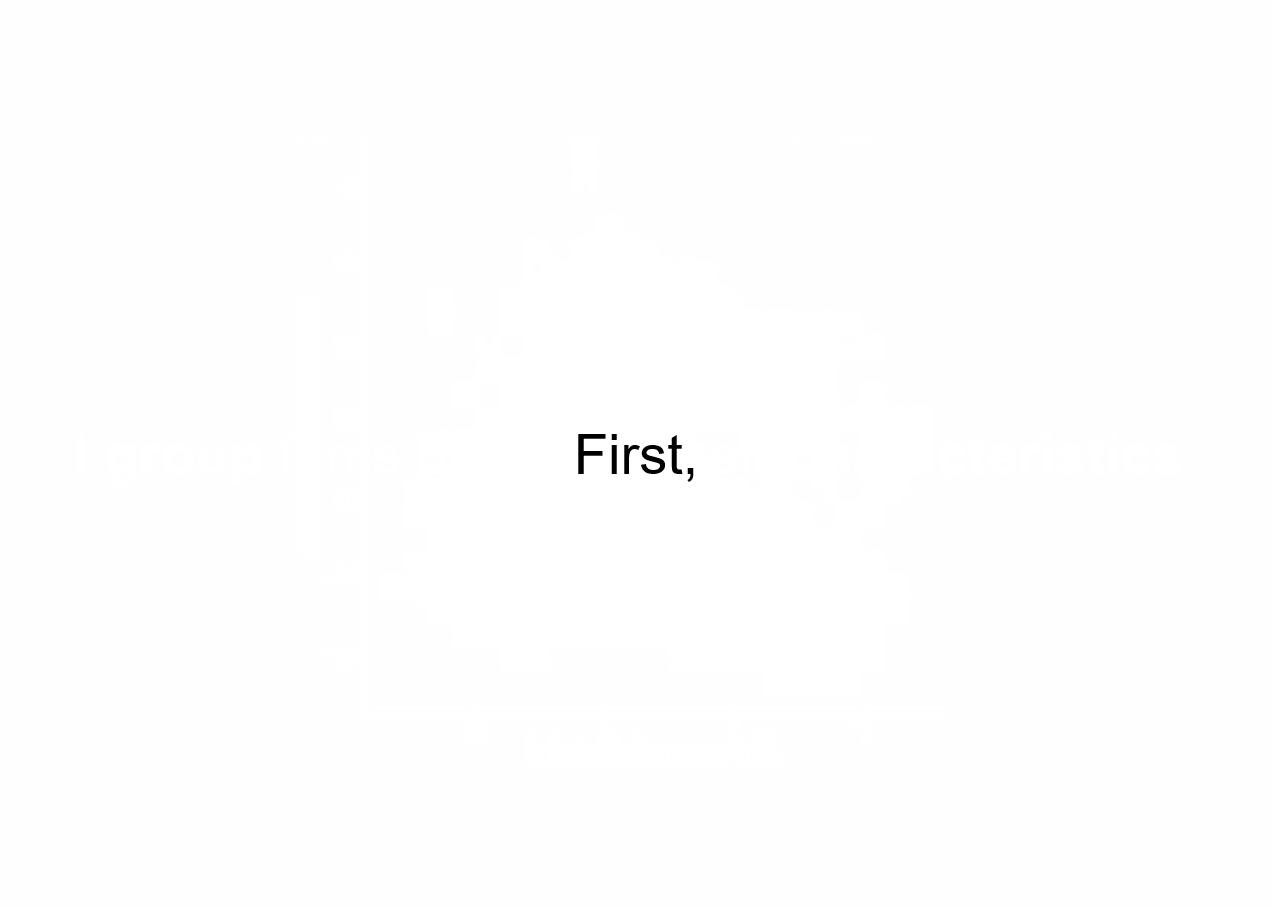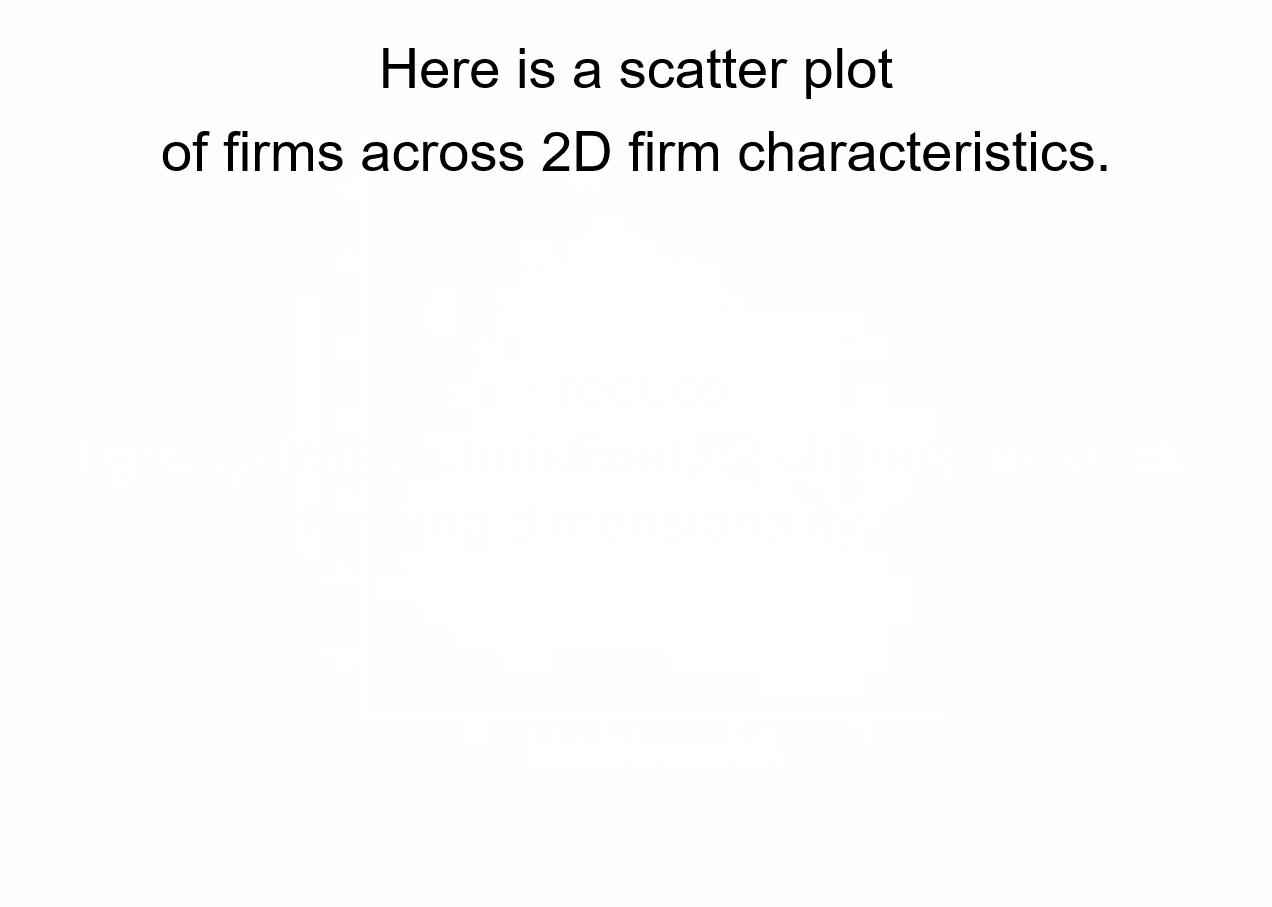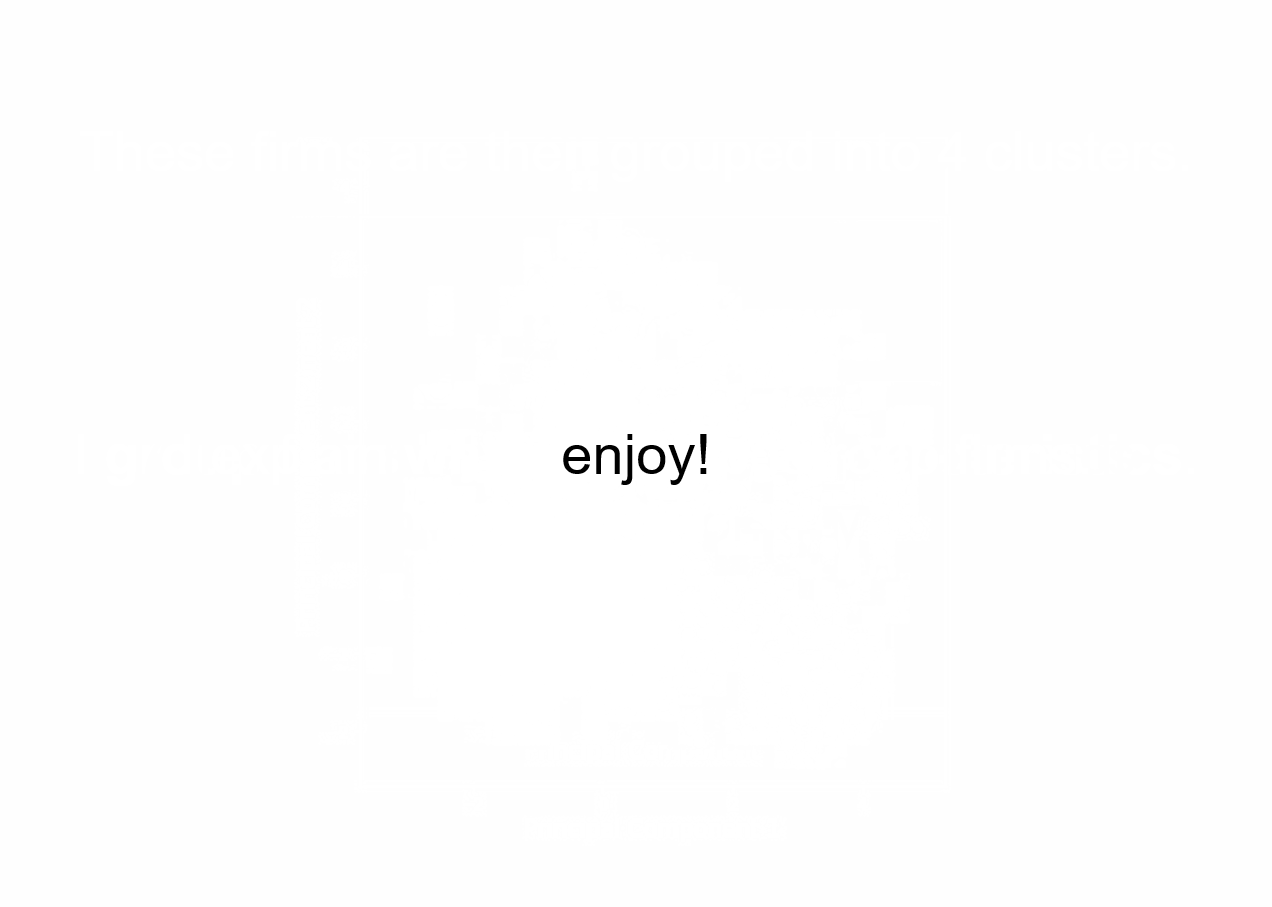
Figure 1 presents companies' seven features shown in a 2-dimensional space after conducting dimensionality reduction. My goal is to group companies that share similar features, as shown in Figure 2.


In my dissertation, I study whether the new lease rule causes firms to reduce their leasing activity (e.g., discontinue a truck lease). To establish this causality between the new lease rule and firms' leasing activity, I need to eliminate other factors that can also affect lease use. For example, imagine that a group of automobile companies experienced a supply shock that resulted in a reduction in leasing activity. Because such shock is unrelated to the new lease rule, I need to nullify its effects on leasing activity in order to study the effects of the new lease rule.
The fixed effects method is one of the popular ways to control for group-specific shocks. Going back to the previous example, because the group of automobile companies belongs to the automobile industry, conducting industry fixed effects analysis would eliminate the automobile industry-specific shocks. In my dissertation, however, industry grouping may not be adequate because leasing decisions depend on various firm features and not just an industry membership. If the relationships between firm features and leasing decisions are perfectly linear, then adding firm features as control variables in regression models should be sufficient. However, since that is unlikely the case, adding fixed effects of groups generated using firm features provides an incremental benefit.
One way to form groups is to transform all firm features to high/low values and group firms with similar values. For example, I can create two groups based on high/low values of firm size or four groups based on high/low values of firm size and past leasing activity. However, the challenge is that I have a lot more than two firm features, and I don't know an adequate number of groups. To overcome these challenges, I let the computer conduct unsupervised learning on my data and help me decide how to form groups.
The K-means clustering algorithm is one of the most popular unsupervised machine learning algorithms to form groups. A cluster refers to a group of similar things close to each other. The main goal of the algorithm is to find clusters that minimize the distances between points within clusters. I use Python's Scikit-learn library to implement the algorithm, but here is what's going on behind the scenes.
- Step 1: Choose the number of clusters (k) using the elbow method.
- Step 2: Randomly place k centroids in the data space.
- Step 3: Calculate the Euclidean distance between data points and centroids.
- Step 4: Assign each data point to the nearest centroids. Clusters are formed at this step.
- Step 5: Recalculate the centroid of the clusters (i.e., average the data - where the name K-'means' comes from).
- Step 6: Repeat steps 4 and 5.
Stop the loop when one or more of the following is true:
- (1) Centroids of new clusters no longer change.
- (2) The same data points are assigned to the same centroids.
- (3) A pre-specified maximum number of iterations are reached.