-
Notifications
You must be signed in to change notification settings - Fork 154
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
b17983f
commit 0c576a9
Showing
6 changed files
with
892 additions
and
1 deletion.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,177 @@ | ||
| JsoupXpath | ||
| ========== | ||
|
|
||
| [](https://github.com/zhegexiaohuozi/JsoupXpath/releases) | ||
| [](http://search.maven.org/#search%7Cgav%7C1%7Cg%3A%22cn.wanghaomiao%22%20AND%20a%3A%22JsoupXpath%22) | ||
| [](https://opensource.org/licenses/Apache-2.0) | ||
|
|
||
| A pure Java implementation of an HTML parser that supports W3C Xpath 1.0 standard syntax. It is a HTML parser based on Jsoup and Antlr4, and it might be the best in Java. Just try it. | ||
|
|
||
| [English Doc](https://github.com/zhegexiaohuozi/JsoupXpath/blob/master/README_EN.md) | ||
|
|
||
| ## Introduction ## | ||
|
|
||
| **JsoupXpath** is a pure Java-developed HTML data parser that uses XPath to parse and extract data. It completely re-implements the W3C XPATH 1.0 standard syntax for HTML parsing. The lexer and parser of XPath are built using Antlr4, and the HTML DOM tree is generated using Jsoup, hence the name JsoupXpath. Developed to enjoy the power and convenience of XPath in Java but unable to find a sufficiently user-friendly XPath parser, JsoupXpath has a clear implementation logic and is easy to extend. It fully supports the W3C XPATH 1.0 standard syntax. W3C specification: http://www.w3.org/TR/1999/REC-xpath-19991116, JsoupXpath grammar file [Xpath.g4](https://github.com/zhegexiaohuozi/JsoupXpath/blob/master/src/main/resources/Xpath.g4). | ||
|
|
||
| # Change Log # | ||
|
|
||
| https://github.com/zhegexiaohuozi/JsoupXpath/releases | ||
|
|
||
| # Community Discussion # | ||
|
|
||
| - Issue | ||
|
|
||
| https://github.com/zhegexiaohuozi/JsoupXpath/issues | ||
|
|
||
| - WeChat Subscription Account | ||
|
|
||
|  | ||
|
|
||
| This account will publish some usage cases and articles, as well as the latest update dynamics of the Seimi system and related projects. It will also feature articles and reflections from the author on backend internet technology. | ||
|
|
||
| ## Quick Start ## | ||
|
|
||
| Maven dependency, for all versions, please refer to [release information](https://github.com/zhegexiaohuozi/JsoupXpath/releases) or [central Maven repository](http://search.maven.org/#search%7Cgav%7C1%7Cg%3A%22cn.wanghaomiao%22%20AND%20a%3A%22JsoupXpath%22): | ||
| ``` | ||
| <dependency> | ||
| <groupId>cn.wanghaomiao</groupId> | ||
| <artifactId>JsoupXpath</artifactId> | ||
| <version>2.5.3</version> | ||
| </dependency> | ||
| ``` | ||
|
|
||
| Example: | ||
|
|
||
| ``` | ||
| String html = "<html><body><script>console.log('aaaaa')</script><div class='test'>some body</div><div class='xiao'>Two</div></body></html>"; | ||
| JXDocument underTest = JXDocument.create(html); | ||
| String xpath = "//div[contains(@class,'xiao')]/text()"; | ||
| JXNode node = underTest.selNOne(xpath); | ||
| Assert.assertEquals("Two",node.asString()); | ||
| ``` | ||
| For more references, see [`org.seimicrawler.xpath.JXDocumentTest`](https://github.com/zhegexiaohuozi/JsoupXpath/blob/master/src/test/java/org/seimicrawler/xpath/JXDocumentTest.java), which contains a large number of test cases. | ||
|
|
||
| Or you can look at the [typical examples](https://github.com/zhegexiaohuozi/JsoupXpath/issues?q=is%3Aissue+is%3Aclosed+label%3A%E6%96%B0%E6%89%8B%E5%8F%82%E8%80%83) in the Issues. | ||
|
|
||
| ## Syntax ## | ||
|
|
||
| Supports the complete W3C XPATH 1.0 standard syntax. W3C specification: http://www.w3.org/TR/1999/REC-xpath-19991116 | ||
|
|
||
| Here is an example of the syntax tree generated by JsoupXpath using Antlr4, which provides a quick overview of JsoupXpath's syntax handling capabilities and the syntax parsing process. | ||
| - `//ul[@class='subject-list']/li[./div/div/span[@class='pl']/num()>(1000+90*(2*50))][last()][1]/div/h2/allText()` | ||
| This example demonstrates the parsing of nested expressions. Click the image to view the full-size version. | ||
| [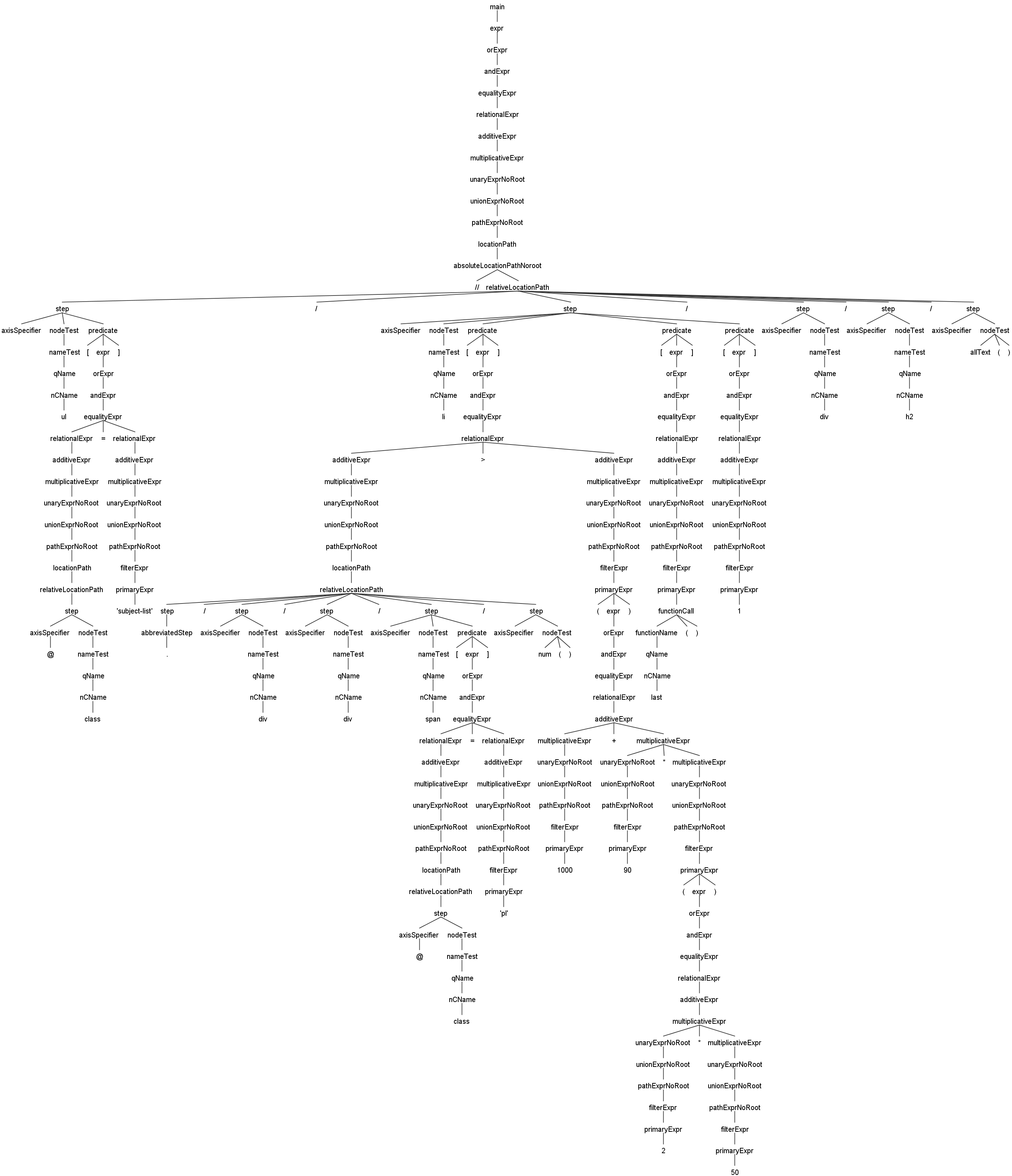](https://imgs.wanghaomiao.cn/jsoupxpath/antlr4_parse_tree_muti_expr.png) | ||
|
|
||
| - `//ul[@class='subject-list']/li[not(contains(self::li/div/div/span[@class='pl']//text(),'14582'))]/div/h2//text()` | ||
| This example demonstrates the parsing of built-in functions. Click the image to view the full-size version. | ||
| [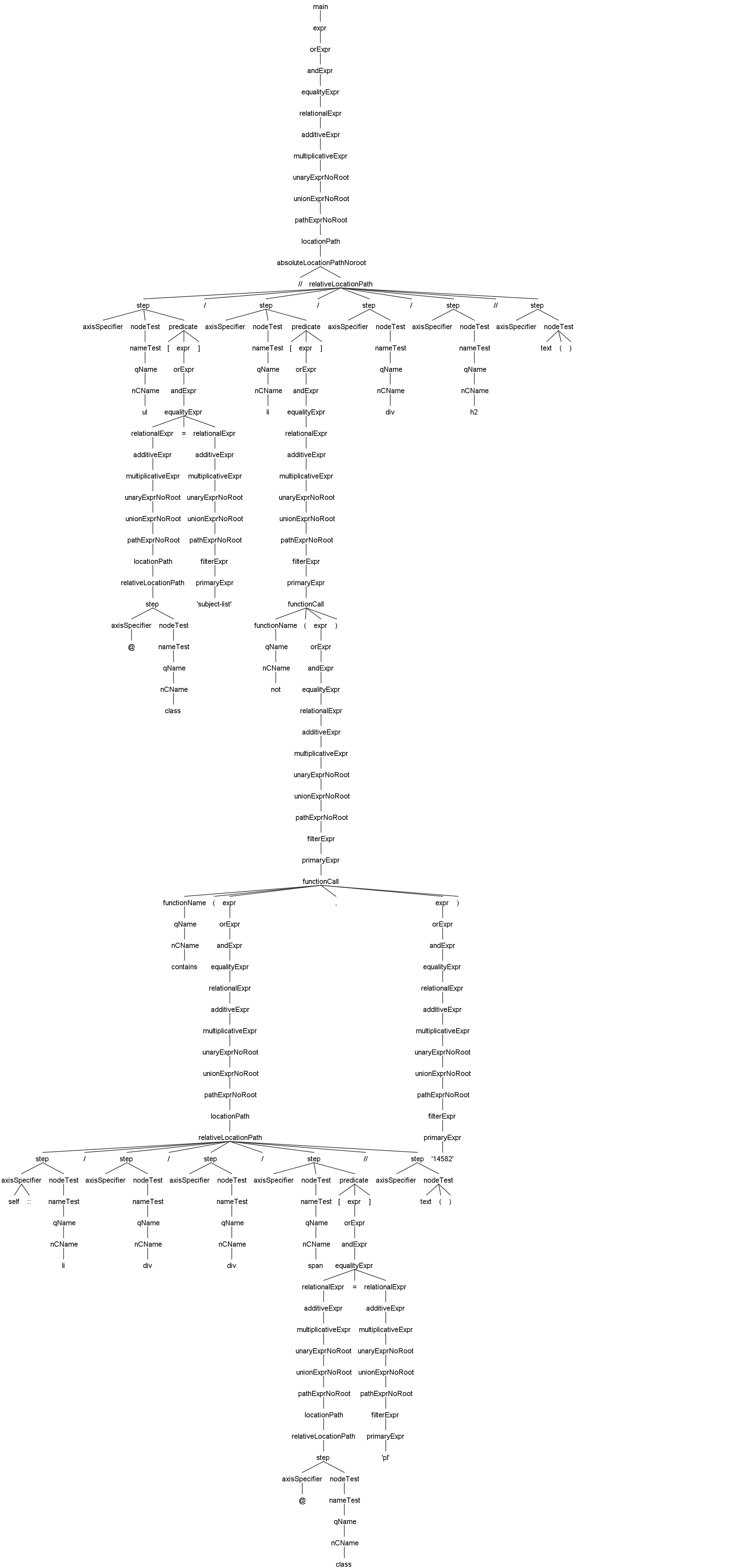](https://imgs.wanghaomiao.cn/jsoupxpath/antlr4_parse_tree_functions_v2.png) | ||
|
|
||
| ### Precautions When Using Xpath ### | ||
|
|
||
| In most cases, it is not recommended to directly copy the Xpath generated by Firefox or Chrome. These browsers often auto-complete tags according to standards during page rendering, such as automatically adding a `tbody` tag to a `table` tag. The Xpath paths generated in this way are not the most generic and may not retrieve values as expected. Therefore, to fully utilize the power and elegance of Xpath, it is best to learn the standard Xpath syntax. This will help you handle various issues with ease and enjoy the true power of Xpath! | ||
|
|
||
| ## Functions ## | ||
|
|
||
| - `int position()` returns the position of the current node within its context | ||
| - `int last()` returns the position of the last node in the context | ||
| - `int first()` returns the position of the first node in the context | ||
| - `string concat(string, string, string*)` concatenates several strings | ||
| - `boolean contains(string, string)` determines whether the first string contains the second | ||
| - `int count(node-set)` counts the number of nodes in the given node set | ||
| - `double/long sum(node-set)` calculates the sum of numeric node values in the given node set. If the parameters include non-numeric content, the calculation will be invalid. | ||
| - `boolean starts-with(string, string)` determines whether the first string starts with the second | ||
| - `int string-length(string?)` returns the length of the string if specified; if not, it converts the current node to a string and returns the length | ||
| - `string substring(string, number, number?)` the first parameter specifies the string, the second specifies the starting position (XPath indices start at 1), and the third specifies the length to extract, not the end position. | ||
|
|
||
| substring("12345", 1.5, 2.6) returns "234" | ||
|
|
||
| substring("12345", 2, 3) returns "234" | ||
|
|
||
| - `string substring-ex(string, number, number)` the first parameter specifies the string, the second specifies the starting position (following Java's convention, starting at 0), and the third specifies the end position (negative numbers are supported). This is an extended function in JsoupXpath to facilitate use by developers accustomed to Java. | ||
| - `string substring-after(string, string)` extracts the part of the first string that follows the second string | ||
| - `string substring-after-last(string, string)` extracts the part of the first string that follows the last occurrence of the second string | ||
| - `string substring-before(string, string)` extracts the part of the first string that precedes the second string | ||
| - `string substring-before-last(string, string)` extracts the part of the first string that precedes the last occurrence of the second string | ||
| - `date format-date(string, string, string)` the first parameter is the expression, the second is the time format of the expression value, and the third is the time zone locale (optional) | ||
|
|
||
| ### Developer-Added Functions ### | ||
| The above functions are just those from the XPath 1.0 standard. Developers can easily add custom functions by implementing the `org.seimicrawler.xpath.core.Function.java` interface and calling `Scanner.registerFunction(Class<? extends Function> func)` during system initialization. There is no need to modify the syntax standard; JsoupXpath will recognize and load them at runtime. For functions in the standard syntax that are currently not implemented in JsoupXpath, we welcome Pull Requests to the main repository to contribute together. | ||
|
|
||
| ### NodeTest ### | ||
| - `allText()` extracts all text under the node, replacing the recursive text extraction usage such as `//div/h3//text()` | ||
| - `html()` retrieves all internal HTML of the node | ||
| - `outerHtml()` retrieves all HTML including the node itself | ||
| - `num()` extracts all numbers from the node's own text. If you know that the node's own text (i.e., text not included in child nodes) contains only one number, such as a read count, comment count, or price, you can directly extract this number. If there are multiple numbers, the first consecutive number will be extracted. | ||
| - `text()` extracts the node's own text. For more information, see https://github.com/zhegexiaohuozi/JsoupXpath/releases/tag/v2.4.1 | ||
| - `node()` extracts all nodes | ||
|
|
||
| ## Axis ## | ||
| ``` | ||
| AxisName: 'ancestor' // Selects the ancestors of the node in the current context | ||
| | 'ancestor-or-self' // Selects the ancestors of the node in the current context, including the node itself | ||
| | 'attribute' // Marked for extracting node attributes | ||
| | 'child' // Selects the child nodes of the node in the current context; this is the default axis in XPath, e.g., /div/li is a shorthand for /div/child::li | ||
| | 'descendant' // Selects the descendants of the node in the current context | ||
| | 'descendant-or-self' // Selects the descendants of the node in the current context, including the node itself | ||
| | 'following' // Selects all nodes that follow the node in the current context | ||
| | 'following-sibling' // Selects all following sibling nodes of the node in the current context | ||
| | 'parent' // Selects the parent node of the node in the current context | ||
| | 'preceding' // Selects all nodes that precede the node in the current context | ||
| | 'preceding-sibling' // Selects all preceding sibling nodes of the node in the current context | ||
| | 'self' // Selects the node in the current context | ||
| | 'following-sibling-one' // Selects the next sibling node of the node in the context (JsoupXpath extension) | ||
| | 'preceding-sibling-one' // Selects the previous sibling node of the node in the context (JsoupXpath extension) | ||
| | 'sibling' // Selects all siblings (JsoupXpath extension) (Under development...) | ||
| ; | ||
| ``` | ||
|
|
||
| ## Operators ## | ||
|
|
||
| ``` | ||
| MINUS | ||
| : '-'; | ||
| PLUS | ||
| : '+'; | ||
| DOT | ||
| : '.'; | ||
| MUL | ||
| : '*'; | ||
| DIVISION | ||
| : '`div`'; | ||
| MODULO | ||
| : '`mod`'; | ||
| DOTDOT | ||
| : '..'; | ||
| AT | ||
| : '@'; | ||
| COMMA | ||
| : ','; | ||
| PIPE | ||
| : '|'; | ||
| LESS | ||
| : '<'; | ||
| MORE_ | ||
| : '>'; | ||
| LE | ||
| : '<='; | ||
| GE | ||
| : '>='; | ||
| START_WITH | ||
| : '^='; // `a^=b` string a starts with string b (JsoupXpath extension) | ||
| END_WITH | ||
| : '$='; // `a$=b` a contains b, a contains b (JsoupXpath extension) | ||
| CONTAIN_WITH | ||
| : '*='; // a contains b, a contains b (JsoupXpath extension) | ||
| REGEXP_WITH | ||
| : '~='; // content of a matches regular expression b (JsoupXpath extension) | ||
| REGEXP_NOT_WITH | ||
| : '!~'; // content of a does not match regular expression b (JsoupXpath extension) | ||
| ``` | ||
|
|
||
| ## Applied Projects ## | ||
| Currently, JsoupXpath is widely used in projects or organizations such as [SeimiCrawler](https://github.com/zhegexiaohuozi/SeimiCrawler). | ||
| If you have a project that uses JsoupXpath and would like it to be listed here, please contact me through the following contact information. The email format can be: | ||
| ``` | ||
| Project or Organization Name: XX | ||
| Project or Organization URL: http://xxx.xxx.cc | ||
| ``` |
Oops, something went wrong.